This is page 1 of 4. Use http://codebase.md/dbt-labs/dbt-mcp?page={x} to view the full context.
# Directory Structure
```
├── .changes
│ ├── header.tpl.md
│ ├── unreleased
│ │ ├── .gitkeep
│ │ ├── Bug Fix-20251028-143835.yaml
│ │ ├── Enhancement or New Feature-20251014-175047.yaml
│ │ └── Under the Hood-20251030-151902.yaml
│ ├── v0.1.3.md
│ ├── v0.10.0.md
│ ├── v0.10.1.md
│ ├── v0.10.2.md
│ ├── v0.10.3.md
│ ├── v0.2.0.md
│ ├── v0.2.1.md
│ ├── v0.2.10.md
│ ├── v0.2.11.md
│ ├── v0.2.12.md
│ ├── v0.2.13.md
│ ├── v0.2.14.md
│ ├── v0.2.15.md
│ ├── v0.2.16.md
│ ├── v0.2.17.md
│ ├── v0.2.18.md
│ ├── v0.2.19.md
│ ├── v0.2.2.md
│ ├── v0.2.20.md
│ ├── v0.2.3.md
│ ├── v0.2.4.md
│ ├── v0.2.5.md
│ ├── v0.2.6.md
│ ├── v0.2.7.md
│ ├── v0.2.8.md
│ ├── v0.2.9.md
│ ├── v0.3.0.md
│ ├── v0.4.0.md
│ ├── v0.4.1.md
│ ├── v0.4.2.md
│ ├── v0.5.0.md
│ ├── v0.6.0.md
│ ├── v0.6.1.md
│ ├── v0.6.2.md
│ ├── v0.7.0.md
│ ├── v0.8.0.md
│ ├── v0.8.1.md
│ ├── v0.8.2.md
│ ├── v0.8.3.md
│ ├── v0.8.4.md
│ ├── v0.9.0.md
│ ├── v0.9.1.md
│ └── v1.0.0.md
├── .changie.yaml
├── .env.example
├── .github
│ ├── actions
│ │ └── setup-python
│ │ └── action.yml
│ ├── CODEOWNERS
│ ├── ISSUE_TEMPLATE
│ │ ├── bug_report.yml
│ │ └── feature_request.yml
│ ├── pull_request_template.md
│ └── workflows
│ ├── changelog-check.yml
│ ├── codeowners-check.yml
│ ├── create-release-pr.yml
│ ├── release.yml
│ └── run-checks-pr.yaml
├── .gitignore
├── .pre-commit-config.yaml
├── .task
│ └── checksum
│ └── d2
├── .tool-versions
├── .vscode
│ ├── launch.json
│ └── settings.json
├── CHANGELOG.md
├── CONTRIBUTING.md
├── docs
│ ├── d2.png
│ └── diagram.d2
├── evals
│ └── semantic_layer
│ └── test_eval_semantic_layer.py
├── examples
│ ├── .DS_Store
│ ├── aws_strands_agent
│ │ ├── __init__.py
│ │ ├── .DS_Store
│ │ ├── dbt_data_scientist
│ │ │ ├── __init__.py
│ │ │ ├── .env.example
│ │ │ ├── agent.py
│ │ │ ├── prompts.py
│ │ │ ├── quick_mcp_test.py
│ │ │ ├── test_all_tools.py
│ │ │ └── tools
│ │ │ ├── __init__.py
│ │ │ ├── dbt_compile.py
│ │ │ ├── dbt_mcp.py
│ │ │ └── dbt_model_analyzer.py
│ │ ├── LICENSE
│ │ ├── README.md
│ │ └── requirements.txt
│ ├── google_adk_agent
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── pyproject.toml
│ │ └── README.md
│ ├── langgraph_agent
│ │ ├── __init__.py
│ │ ├── .python-version
│ │ ├── main.py
│ │ ├── pyproject.toml
│ │ ├── README.md
│ │ └── uv.lock
│ ├── openai_agent
│ │ ├── __init__.py
│ │ ├── .gitignore
│ │ ├── .python-version
│ │ ├── main_streamable.py
│ │ ├── main.py
│ │ ├── pyproject.toml
│ │ ├── README.md
│ │ └── uv.lock
│ ├── openai_responses
│ │ ├── __init__.py
│ │ ├── .gitignore
│ │ ├── .python-version
│ │ ├── main.py
│ │ ├── pyproject.toml
│ │ ├── README.md
│ │ └── uv.lock
│ ├── pydantic_ai_agent
│ │ ├── __init__.py
│ │ ├── .gitignore
│ │ ├── .python-version
│ │ ├── main.py
│ │ ├── pyproject.toml
│ │ └── README.md
│ └── remote_mcp
│ ├── .python-version
│ ├── main.py
│ ├── pyproject.toml
│ ├── README.md
│ └── uv.lock
├── LICENSE
├── pyproject.toml
├── README.md
├── src
│ ├── client
│ │ ├── __init__.py
│ │ ├── main.py
│ │ └── tools.py
│ ├── dbt_mcp
│ │ ├── __init__.py
│ │ ├── .gitignore
│ │ ├── config
│ │ │ ├── config_providers.py
│ │ │ ├── config.py
│ │ │ ├── dbt_project.py
│ │ │ ├── dbt_yaml.py
│ │ │ ├── headers.py
│ │ │ ├── settings.py
│ │ │ └── transport.py
│ │ ├── dbt_admin
│ │ │ ├── __init__.py
│ │ │ ├── client.py
│ │ │ ├── constants.py
│ │ │ ├── run_results_errors
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ └── parser.py
│ │ │ └── tools.py
│ │ ├── dbt_cli
│ │ │ ├── binary_type.py
│ │ │ └── tools.py
│ │ ├── dbt_codegen
│ │ │ ├── __init__.py
│ │ │ └── tools.py
│ │ ├── discovery
│ │ │ ├── client.py
│ │ │ └── tools.py
│ │ ├── errors
│ │ │ ├── __init__.py
│ │ │ ├── admin_api.py
│ │ │ ├── base.py
│ │ │ ├── cli.py
│ │ │ ├── common.py
│ │ │ ├── discovery.py
│ │ │ ├── semantic_layer.py
│ │ │ └── sql.py
│ │ ├── gql
│ │ │ └── errors.py
│ │ ├── lsp
│ │ │ ├── __init__.py
│ │ │ ├── lsp_binary_manager.py
│ │ │ ├── lsp_client.py
│ │ │ ├── lsp_connection.py
│ │ │ └── tools.py
│ │ ├── main.py
│ │ ├── mcp
│ │ │ ├── create.py
│ │ │ └── server.py
│ │ ├── oauth
│ │ │ ├── client_id.py
│ │ │ ├── context_manager.py
│ │ │ ├── dbt_platform.py
│ │ │ ├── fastapi_app.py
│ │ │ ├── logging.py
│ │ │ ├── login.py
│ │ │ ├── refresh_strategy.py
│ │ │ ├── token_provider.py
│ │ │ └── token.py
│ │ ├── prompts
│ │ │ ├── __init__.py
│ │ │ ├── admin_api
│ │ │ │ ├── cancel_job_run.md
│ │ │ │ ├── get_job_details.md
│ │ │ │ ├── get_job_run_artifact.md
│ │ │ │ ├── get_job_run_details.md
│ │ │ │ ├── get_job_run_error.md
│ │ │ │ ├── list_job_run_artifacts.md
│ │ │ │ ├── list_jobs_runs.md
│ │ │ │ ├── list_jobs.md
│ │ │ │ ├── retry_job_run.md
│ │ │ │ └── trigger_job_run.md
│ │ │ ├── dbt_cli
│ │ │ │ ├── args
│ │ │ │ │ ├── full_refresh.md
│ │ │ │ │ ├── limit.md
│ │ │ │ │ ├── resource_type.md
│ │ │ │ │ ├── selectors.md
│ │ │ │ │ ├── sql_query.md
│ │ │ │ │ └── vars.md
│ │ │ │ ├── build.md
│ │ │ │ ├── compile.md
│ │ │ │ ├── docs.md
│ │ │ │ ├── list.md
│ │ │ │ ├── parse.md
│ │ │ │ ├── run.md
│ │ │ │ ├── show.md
│ │ │ │ └── test.md
│ │ │ ├── dbt_codegen
│ │ │ │ ├── args
│ │ │ │ │ ├── case_sensitive_cols.md
│ │ │ │ │ ├── database_name.md
│ │ │ │ │ ├── generate_columns.md
│ │ │ │ │ ├── include_data_types.md
│ │ │ │ │ ├── include_descriptions.md
│ │ │ │ │ ├── leading_commas.md
│ │ │ │ │ ├── materialized.md
│ │ │ │ │ ├── model_name.md
│ │ │ │ │ ├── model_names.md
│ │ │ │ │ ├── schema_name.md
│ │ │ │ │ ├── source_name.md
│ │ │ │ │ ├── table_name.md
│ │ │ │ │ ├── table_names.md
│ │ │ │ │ ├── tables.md
│ │ │ │ │ └── upstream_descriptions.md
│ │ │ │ ├── generate_model_yaml.md
│ │ │ │ ├── generate_source.md
│ │ │ │ └── generate_staging_model.md
│ │ │ ├── discovery
│ │ │ │ ├── get_all_models.md
│ │ │ │ ├── get_all_sources.md
│ │ │ │ ├── get_exposure_details.md
│ │ │ │ ├── get_exposures.md
│ │ │ │ ├── get_mart_models.md
│ │ │ │ ├── get_model_children.md
│ │ │ │ ├── get_model_details.md
│ │ │ │ ├── get_model_health.md
│ │ │ │ └── get_model_parents.md
│ │ │ ├── lsp
│ │ │ │ ├── args
│ │ │ │ │ ├── column_name.md
│ │ │ │ │ └── model_id.md
│ │ │ │ └── get_column_lineage.md
│ │ │ ├── prompts.py
│ │ │ └── semantic_layer
│ │ │ ├── get_dimensions.md
│ │ │ ├── get_entities.md
│ │ │ ├── get_metrics_compiled_sql.md
│ │ │ ├── list_metrics.md
│ │ │ └── query_metrics.md
│ │ ├── py.typed
│ │ ├── semantic_layer
│ │ │ ├── client.py
│ │ │ ├── gql
│ │ │ │ ├── gql_request.py
│ │ │ │ └── gql.py
│ │ │ ├── levenshtein.py
│ │ │ ├── tools.py
│ │ │ └── types.py
│ │ ├── sql
│ │ │ └── tools.py
│ │ ├── telemetry
│ │ │ └── logging.py
│ │ ├── tools
│ │ │ ├── annotations.py
│ │ │ ├── definitions.py
│ │ │ ├── policy.py
│ │ │ ├── register.py
│ │ │ ├── tool_names.py
│ │ │ └── toolsets.py
│ │ └── tracking
│ │ └── tracking.py
│ └── remote_mcp
│ ├── __init__.py
│ └── session.py
├── Taskfile.yml
├── tests
│ ├── __init__.py
│ ├── env_vars.py
│ ├── integration
│ │ ├── __init__.py
│ │ ├── dbt_codegen
│ │ │ ├── __init__.py
│ │ │ └── test_dbt_codegen.py
│ │ ├── discovery
│ │ │ └── test_discovery.py
│ │ ├── initialization
│ │ │ ├── __init__.py
│ │ │ └── test_initialization.py
│ │ ├── lsp
│ │ │ └── test_lsp_connection.py
│ │ ├── remote_mcp
│ │ │ └── test_remote_mcp.py
│ │ ├── remote_tools
│ │ │ └── test_remote_tools.py
│ │ ├── semantic_layer
│ │ │ └── test_semantic_layer.py
│ │ └── tracking
│ │ └── test_tracking.py
│ ├── mocks
│ │ └── config.py
│ └── unit
│ ├── __init__.py
│ ├── config
│ │ ├── __init__.py
│ │ ├── test_config.py
│ │ └── test_transport.py
│ ├── dbt_admin
│ │ ├── __init__.py
│ │ ├── test_client.py
│ │ ├── test_error_fetcher.py
│ │ └── test_tools.py
│ ├── dbt_cli
│ │ ├── __init__.py
│ │ ├── test_cli_integration.py
│ │ └── test_tools.py
│ ├── dbt_codegen
│ │ ├── __init__.py
│ │ └── test_tools.py
│ ├── discovery
│ │ ├── __init__.py
│ │ ├── conftest.py
│ │ ├── test_exposures_fetcher.py
│ │ └── test_sources_fetcher.py
│ ├── lsp
│ │ ├── __init__.py
│ │ ├── test_lsp_client.py
│ │ ├── test_lsp_connection.py
│ │ └── test_lsp_tools.py
│ ├── oauth
│ │ ├── test_credentials_provider.py
│ │ ├── test_fastapi_app_pagination.py
│ │ └── test_token.py
│ ├── tools
│ │ ├── test_disable_tools.py
│ │ ├── test_tool_names.py
│ │ ├── test_tool_policies.py
│ │ └── test_toolsets.py
│ └── tracking
│ └── test_tracking.py
├── ui
│ ├── .gitignore
│ ├── assets
│ │ ├── dbt_logo BLK.svg
│ │ └── dbt_logo WHT.svg
│ ├── eslint.config.js
│ ├── index.html
│ ├── package.json
│ ├── pnpm-lock.yaml
│ ├── pnpm-workspace.yaml
│ ├── README.md
│ ├── src
│ │ ├── App.css
│ │ ├── App.tsx
│ │ ├── global.d.ts
│ │ ├── index.css
│ │ ├── main.tsx
│ │ └── vite-env.d.ts
│ ├── tsconfig.app.json
│ ├── tsconfig.json
│ ├── tsconfig.node.json
│ └── vite.config.ts
└── uv.lock
```
# Files
--------------------------------------------------------------------------------
/.changes/unreleased/.gitkeep:
--------------------------------------------------------------------------------
```
```
--------------------------------------------------------------------------------
/src/dbt_mcp/.gitignore:
--------------------------------------------------------------------------------
```
ui
```
--------------------------------------------------------------------------------
/examples/langgraph_agent/.python-version:
--------------------------------------------------------------------------------
```
3.13
```
--------------------------------------------------------------------------------
/examples/openai_agent/.python-version:
--------------------------------------------------------------------------------
```
3.13
```
--------------------------------------------------------------------------------
/examples/openai_responses/.python-version:
--------------------------------------------------------------------------------
```
3.13
```
--------------------------------------------------------------------------------
/examples/pydantic_ai_agent/.python-version:
--------------------------------------------------------------------------------
```
3.13
```
--------------------------------------------------------------------------------
/examples/remote_mcp/.python-version:
--------------------------------------------------------------------------------
```
3.13
```
--------------------------------------------------------------------------------
/examples/openai_agent/.gitignore:
--------------------------------------------------------------------------------
```
.envrc
```
--------------------------------------------------------------------------------
/examples/openai_responses/.gitignore:
--------------------------------------------------------------------------------
```
.envrc
```
--------------------------------------------------------------------------------
/examples/pydantic_ai_agent/.gitignore:
--------------------------------------------------------------------------------
```
.envrc
```
--------------------------------------------------------------------------------
/ui/.gitignore:
--------------------------------------------------------------------------------
```
node_modules
```
--------------------------------------------------------------------------------
/.tool-versions:
--------------------------------------------------------------------------------
```
nodejs 20.17.0
uv 0.8.19
task 3.43.2
pnpm 10.15.1
```
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
```
__pycache__/
.venv/
.env
.mypy_cache/
.pytest_cache/
*.egg-info/
.idea/
vortex_dev_mode_output.jsonl
dbt-mcp.log
```
--------------------------------------------------------------------------------
/.env.example:
--------------------------------------------------------------------------------
```
DBT_HOST=cloud.getdbt.com
DBT_PROD_ENV_ID=your-production-environment-id
DBT_DEV_ENV_ID=your-development-environment-id
DBT_USER_ID=your-user-id
DBT_TOKEN=your-service-token
DBT_PROJECT_DIR=/path/to/your/dbt/project
DBT_PATH=/path/to/your/dbt/executable
MULTICELL_ACCOUNT_PREFIX=your-account-prefix
```
--------------------------------------------------------------------------------
/.changie.yaml:
--------------------------------------------------------------------------------
```yaml
changesDir: .changes
unreleasedDir: unreleased
headerPath: header.tpl.md
changelogPath: CHANGELOG.md
versionExt: md
versionFormat: '## {{.Version}} - {{.Time.Format "2006-01-02"}}'
kindFormat: '### {{.Kind}}'
changeFormat: '* {{.Body}}'
kinds:
- label: Breaking Change
auto: major
- label: Enhancement or New Feature
auto: minor
- label: Under the Hood
auto: patch
- label: Bug Fix
auto: patch
- label: Security
auto: patch
newlines:
afterChangelogHeader: 1
beforeChangelogVersion: 1
endOfVersion: 1
envPrefix: CHANGIE_
```
--------------------------------------------------------------------------------
/examples/aws_strands_agent/dbt_data_scientist/.env.example:
--------------------------------------------------------------------------------
```
# Local Project Development Setup
DBT_PROJECT_LOCATION= Path to your local dbt project directory
DBT_EXECUTABLE= Path to dbt executable (/Users/username/.local/bin/dbt)
# Not Required: Used for comparing fusion and core
DBT_CLASSIC= Path to dbt executable (/opt/homebrew/bin/dbt)
# LLM Keys
GOOGLE_API_KEY= Your Google API Key
ANTHROPIC_API_KEY=Your Anthropic/Claude API Key
OPENAI_API_KEY=Your OpenAI API Key
# ===== REQUIRED: dbt MCP Server Configuration =====
DBT_MCP_URL= The URL of your dbt MCP server
DBT_TOKEN= Your dbt Cloud authentication token
DBT_USER_ID= Your dbt Cloud user ID (numeric)
DBT_PROD_ENV_ID= Your dbt Cloud production environment ID (numeric)
# ===== OPTIONAL: dbt Environment IDs =====
DBT_DEV_ENV_ID= Your dbt Cloud development environment ID (numeric)
DBT_ACCOUNT_ID= Your dbt Cloud account ID (numeric)
```
--------------------------------------------------------------------------------
/.pre-commit-config.yaml:
--------------------------------------------------------------------------------
```yaml
exclude: |
(?x)^(
.mypy_cache/
| .pytest_cache/
| .venv/
)$
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: pretty-format-json
args: ["--autofix"]
- id: check-merge-conflict
- id: no-commit-to-branch
args: [--branch, main]
- repo: https://github.com/rhysd/actionlint
rev: v1.7.3
hooks:
- id: actionlint
- repo: https://github.com/charliermarsh/ruff-pre-commit
rev: v0.9.5
hooks:
- id: ruff
args: [--fix]
exclude: examples/
- id: ruff-format
exclude: examples/
- repo: https://github.com/astral-sh/uv-pre-commit
rev: 0.8.19
hooks:
- id: uv-lock
- repo: https://github.com/pre-commit/mirrors-mypy
rev: v1.13.0
hooks:
- id: mypy
language: system
pass_filenames: false
args: ["--show-error-codes", "--namespace-packages", "--exclude", "examples/", "."]
exclude: examples/
```
--------------------------------------------------------------------------------
/examples/remote_mcp/README.md:
--------------------------------------------------------------------------------
```markdown
```
--------------------------------------------------------------------------------
/examples/openai_responses/README.md:
--------------------------------------------------------------------------------
```markdown
# OpenAI Responses
An example of using remote dbt-mcp with OpenAI's Responses API
## Usage
`uv run main.py`
```
--------------------------------------------------------------------------------
/ui/README.md:
--------------------------------------------------------------------------------
```markdown
# dbt MCP
This UI enables easier configuration of dbt MCP. Check out `package.json` and `Taskfile.yml` for usage.
```
--------------------------------------------------------------------------------
/examples/langgraph_agent/README.md:
--------------------------------------------------------------------------------
```markdown
# LangGraph Agent Example
This is a simple example of how to create conversational agent with remote dbt MCP & LangGraph.
## Usage
1. Set an `ANTHROPIC_API_KEY` environment variable with your Anthropic API key.
2. Run `uv run main.py`.
```
--------------------------------------------------------------------------------
/examples/pydantic_ai_agent/README.md:
--------------------------------------------------------------------------------
```markdown
# Pydantic AI Agent
An example of using Pydantic AI with the remote dbt MCP server.
## Config
Set the following environment variables:
- `OPENAI_API_KEY` (or the API key for any other model supported by PydanticAI)
- `DBT_TOKEN`
- `DBT_PROD_ENV_ID`
- `DBT_HOST` (if not using the default `cloud.getdbt.com`)
## Usage
`uv run main.py`
```
--------------------------------------------------------------------------------
/examples/google_adk_agent/README.md:
--------------------------------------------------------------------------------
```markdown
# Google ADK Agent for dbt MCP
An example of using Google Agent Development Kit with the remote dbt MCP server.
## Config
Set the following environment variables:
- `GOOGLE_GENAI_API_KEY` (or the API key for any other model supported by google ADK)
- `ADK_MODEL` (Choose a different model (default: gemini-2.0-flash))
- `DBT_TOKEN`
- `DBT_PROD_ENV_ID`
- `DBT_HOST` (if not using the default `cloud.getdbt.com`)
- `DBT_PROJECT_DIR` (if using dbt core)
### Usage
`uv run main.py`
```
--------------------------------------------------------------------------------
/examples/openai_agent/README.md:
--------------------------------------------------------------------------------
```markdown
# OpenAI Agent
Examples of using dbt-mcp with OpenAI's agent framework
## Usage
### Local MCP Server
- set up the env var file like described in the README and make sure that the `MCPServerStdio` points to it
- set up the env var `OPENAI_API_KEY` with your OpenAI API key
- run `uv run main.py`
### MCP Streamable HTTP Server
- set up the env var `OPENAI_API_KEY` with your OpenAI API key
- set up the env var `DBT_TOKEN` with your dbt API token
- set up the env var `DBT_PROD_ENV_ID` with your dbt production environment ID
- set up the env var `DBT_HOST` with your dbt host (default is `cloud.getdbt.com`)
- run `uv run main_streamable.py`
```
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
```markdown
# dbt MCP Server
[](https://www.bestpractices.dev/projects/11137)
This MCP (Model Context Protocol) server provides various tools to interact with dbt. You can use this MCP server to provide AI agents with context of your project in dbt Core, dbt Fusion, and dbt Platform.
Read our documentation [here](https://docs.getdbt.com/docs/dbt-ai/about-mcp) to learn more. [This](https://docs.getdbt.com/blog/introducing-dbt-mcp-server) blog post provides more details for what is possible with the dbt MCP server.
## Feedback
If you have comments or questions, create a GitHub Issue or join us in [the community Slack](https://www.getdbt.com/community/join-the-community) in the `#tools-dbt-mcp` channel.
## Architecture
The dbt MCP server architecture allows for your agent to connect to a variety of tools.
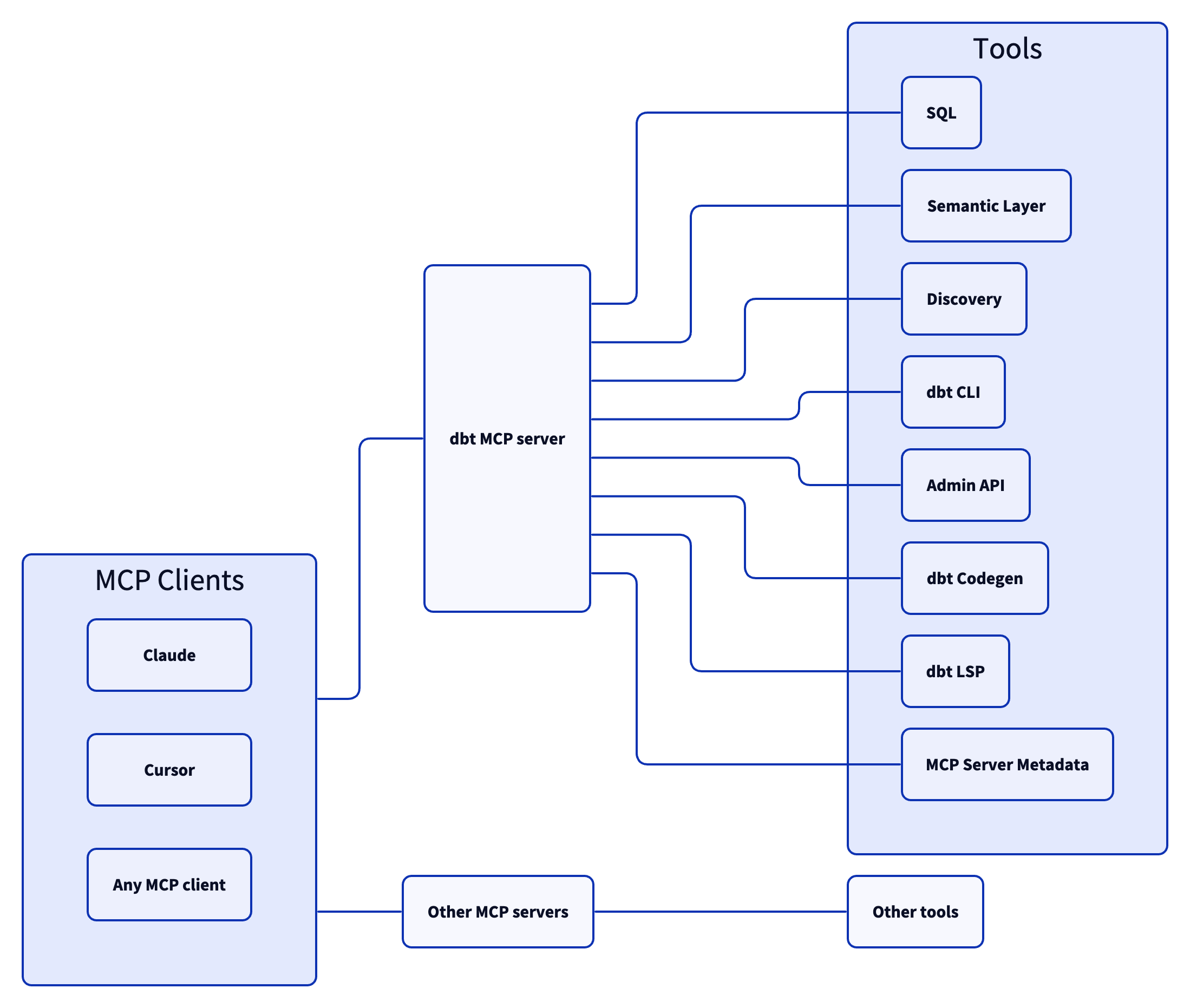
## Examples
Commonly, you will connect the dbt MCP server to an agent product like Claude or Cursor. However, if you are interested in creating your own agent, check out [the examples directory](https://github.com/dbt-labs/dbt-mcp/tree/main/examples) for how to get started.
## Contributing
Read `CONTRIBUTING.md` for instructions on how to get involved!
```
--------------------------------------------------------------------------------
/examples/aws_strands_agent/README.md:
--------------------------------------------------------------------------------
```markdown
# dbt AWS Agentcore Multi-Agent
A multi-agent system built with AWS Bedrock Agent Core that provides intelligent dbt project management and analysis capabilities.
## Architecture
This project implements a multi-agent architecture with three specialized tools:
1. **dbt Compile Tool** - Local dbt compilation functionality
2. **dbt Model Analyzer** - Data model analysis and recommendations
3. **dbt MCP Server Tool** - Remote dbt MCP server connection
## 📋 Prerequisites
- Python 3.10+
- dbt CLI installed and configured
- dbt Fusion installed
- AWS Agentcore setup
## 🛠️ Installation
1. **Clone the repository**:
```bash
git clone <repository-url>
cd dbt-aws-agent
```
2. **Create a virtual environment**:
```bash
python -m venv .venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
```
3. **Install dependencies**:
```bash
pip install -r requirements.txt
```
4. **Set up environment variables**:
```bash
cp .env.example .env
# Edit .env with your configuration
```
5. **Run**:
```bash
cd dbt_data_scientist
python agent.py
```
## Project Structure
```
dbt-aws-agent/
├── dbt_data_scientist/ # Main application package
│ ├── __init__.py # Package initialization
│ ├── agent.py # Main agent with Bedrock Agent Core integration
│ ├── prompts.py # Agent prompts and instructions
│ ├── test_all_tools.py # Comprehensive test suite
│ ├── quick_mcp_test.py # Quick MCP connectivity test
│ └── tools/ # Tool implementations
│ ├── __init__.py
│ ├── dbt_compile.py # Local dbt compilation tool
│ ├── dbt_mcp.py # Remote dbt MCP server tool (translated from Google ADK)
│ └── dbt_model_analyzer.py # Data model analysis tool
├── requirements.txt # Python dependencies
├── env.example # Environment configuration template
└── README.md # This documentation
```
## Tools Overview
### 1. dbt Compile Tool (`dbt_compile.py`)
- **Purpose**: Local dbt project compilation and troubleshooting
- **Features**:
- Runs `dbt compile --log-format json` locally
- Parses JSON logs for structured analysis
- Provides compilation error analysis and recommendations
- Routes to specialized dbt compile agent for intelligent responses
### 2. dbt Model Analyzer Tool (`dbt_model_analyzer.py`)
- **Purpose**: Data model analysis and recommendations
- **Features**:
- Analyzes model structure and dependencies
- Assesses data quality patterns and test coverage
- Reviews adherence to dbt best practices
- Provides optimization recommendations
- Generates model documentation suggestions
### 3. dbt MCP Server Tool (`dbt_mcp.py`)
- **Purpose**: Remote dbt MCP server connection using AWS Bedrock Agent Core
- **Features**:
- Connects to remote dbt MCP server using streamable HTTP client
- Supports dbt Cloud authentication with headers
- Lists available MCP tools dynamically
- Executes dbt MCP tool functions
- Provides intelligent query routing to appropriate tools
- Built-in connection testing and error handling
```
### 3. Test the Setup
Before running the full application, test that everything is working:
```bash
# Quick MCP test
python dbt_data_scientist/quick_mcp_test.py
# Full test suite
python dbt_data_scientist/test_all_tools.py
```
### 4. Run the Application
#### For AWS Bedrock Agent Core:
```bash
python -m dbt_data_scientist.agent
```
#### For Local Testing:
```bash
python -m dbt_data_scientist.agent
```
## Usage Examples
### dbt Compile Tool
```
> "Compile my dbt project and find any issues"
> "What's wrong with my models in the staging folder?"
```
### dbt Model Analyzer Tool
```
> "Analyze my data modeling approach for best practices"
> "Review the dependencies in my dbt project"
> "Check the data quality patterns in my models"
```
### dbt MCP Server Tool
```
> "List all available dbt MCP tools"
> "Show me the catalog from dbt Cloud"
> "Run my models in dbt Cloud"
> "What tests are available in my dbt project?"
```
## Testing
The project includes comprehensive testing capabilities to verify all components are working correctly.
### Quick Tests
#### Test MCP Connection Only
```bash
python dbt_data_scientist/quick_mcp_test.py
```
- Fast, minimal test of MCP connectivity
- Verifies environment variables and connection
- Lists available MCP tools
#### Test MCP Tool Directly
```bash
python dbt_data_scientist/tools/dbt_mcp.py
```
- Tests the MCP module directly
- Built-in connection testing
- Shows detailed error messages
### Comprehensive Testing
#### Full Test Suite
```bash
python dbt_data_scientist/test_all_tools.py
```
- Tests all tools individually
- Verifies agent initialization
- Tests tool integration
- Comprehensive error reporting
### What Tests Verify
1. **Environment Variables** - All required variables are set
2. **Tool Imports** - All tools can be imported successfully
3. **Agent Initialization** - Agent loads with all tools
4. **Individual Tool Testing** - Each tool executes correctly
5. **Agent Integration** - Tools work together in the agent
6. **MCP Connectivity** - Remote MCP server connection works
### Test Output Example
```
🚀 Complete Tool and Agent Test Suite
==================================================
🔧 Testing Environment Setup
------------------------------
✅ DBT_MCP_URL: https://your-mcp-server.com
✅ DBT_TOKEN: ****************
✅ DBT_USER_ID: your_user_id
✅ DBT_PROD_ENV_ID: your_env_id
✅ Environment setup complete!
📦 Testing Tool Imports
------------------------------
✅ All tools imported successfully
✅ dbt_compile is callable
✅ dbt_mcp_tool is callable
✅ dbt_model_analyzer_agent is callable
... (more tests)
🎉 All tests passed! Your agent and tools are working correctly.
```
## Key Features
### 🔄 **Intelligent Routing**
The main agent automatically routes queries to the appropriate specialized tool based on keywords and context.
### 🌐 **MCP Server Integration**
Seamless connection to remote dbt MCP servers with proper authentication and error handling.
### 📊 **Comprehensive Analysis**
Multi-faceted analysis including compilation, modeling best practices, and data quality assessment.
### ⚡ **Async Support**
Full async/await support for MCP operations while maintaining compatibility with Bedrock Agent Core.
### 🛡️ **Error Handling**
Robust error handling and fallback mechanisms for all tool operations.
## Development
### Adding New Tools
1. Create a new tool file in `dbt_data_scientist/tools/`
2. Use the `@tool` decorator from strands
3. Add the tool to the main agent's tools list in `agent.py`
4. Update the routing logic in the main agent's system prompt
## Troubleshooting
### Testing First
Before troubleshooting, run the test suite to identify issues:
```bash
# Quick test for MCP issues
python dbt_data_scientist/quick_mcp_test.py
# Comprehensive test for all issues
python dbt_data_scientist/test_all_tools.py
```
### Common Issues
1. **MCP Connection Failed**
- Run `python dbt_data_scientist/quick_mcp_test.py` to diagnose
- Verify `DBT_MCP_URL` is correct
- Check authentication headers
- Ensure dbt MCP server is accessible
- Check network connectivity
2. **dbt Compile Errors**
- Verify `DBT_PROJECT_LOCATION` path exists
- Check `DBT_EXECUTABLE` is in PATH
- Ensure dbt project is valid
- Run `dbt compile` manually to test
3. **Environment Variable Issues**
- Copy `env.example` to `.env`
- Verify all required variables are set
- Check variable values are correct
- Use the test suite to validate configuration
4. **Agent Initialization Issues**
- Check that all tools can be imported
- Verify MCP server is accessible
- Ensure all dependencies are installed
- Run individual tool tests
### Debug Mode
For detailed debugging, you can run individual components:
```bash
# Test MCP tool directly
python dbt_data_scientist/tools/dbt_mcp.py
# Test individual tools
python -c "from dbt_data_scientist.tools import dbt_compile; print(dbt_compile('test'))"
```
## Contributing
1. Fork the repository
2. Create a feature branch
3. Make your changes
4. Add tests for new functionality
5. Submit a pull request
## License
This project is licensed under the MIT License - see the LICENSE file for details.
```
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
```markdown
# Contributing
With [task](https://taskfile.dev/) installed, simply run `task` to see the list of available commands. For comments, questions, or requests open a GitHub issue.
## Setup
1. Clone the repository:
```shell
git clone https://github.com/dbt-labs/dbt-mcp.git
cd dbt-mcp
```
2. [Install uv](https://docs.astral.sh/uv/getting-started/installation/)
3. [Install Task](https://taskfile.dev/installation/)
4. Run `task install`
5. Configure environment variables:
```shell
cp .env.example .env
```
Then edit `.env` with your specific environment variables (see the `Configuration` section of the `README.md`).
## Testing
This repo has automated tests which can be run with `task test:unit`. Additionally, there is a simple CLI tool which can be used to test by running `task client`. If you would like to test in a client like Cursor or Claude, use a configuration file like this:
```
{
"mcpServers": {
"dbt": {
"command": "<path-to-uv>",
"args": [
"--directory",
"<path-to-this-directory>/dbt-mcp",
"run",
"dbt-mcp",
"--env-file",
"<path-to-this-directory>/dbt-mcp/.env"
]
}
}
}
```
Or, if you would like to test with Oauth, use a configuration like this:
```
{
"mcpServers": {
"dbt": {
"command": "<path-to-uv>",
"args": [
"--directory",
"<path-to-this-directory>/dbt-mcp",
"run",
"dbt-mcp",
],
"env": {
"DBT_HOST": "<dbt-host-with-custom-subdomain>",
}
}
}
}
```
For improved debugging, you can set the `DBT_MCP_SERVER_FILE_LOGGING=true` environment variable to log to a `./dbt-mcp.log` file.
## Signed Commits
Before committing changes, ensure that you have set up [signed commits](https://docs.github.com/en/authentication/managing-commit-signature-verification/signing-commits).
This repo requires signing on all commits for PRs.
## Changelog
Every PR requires a changelog entry. [Install changie](https://changie.dev/) and run `changie new` to create a new changelog entry.
## Debugging
The dbt-mcp server runs with `stdio` transport by default which does not allow for Python debugger support. For debugging with breakpoints, use `streamable-http` transport.
### Option 1: MCP Inspector Only (No Breakpoints)
1. Run `task inspector` - this starts both the server and inspector automatically
2. Open MCP Inspector UI
3. Use "STDIO" Transport Type to connect
4. Test tools interactively in the inspector UI (uses `stdio` transport, no debugger support)
### Option 2: VS Code Debugger with Breakpoints (Recommended for Debugging)
1. Set breakpoints in your code
2. Press `F5` or select "debug dbt-mcp" from the Run menu
3. Open MCP Inspector UI via `npx @modelcontextprotocol/inspector`
4. Connect to `http://localhost:8000/mcp/v1` using "Streamable HTTP" transport and "Via Proxy" connection type
5. Call tools from Inspector - your breakpoints will trigger
### Option 3: Manual Debugging with `task dev`
1. Run `task dev` - this starts the server with `streamable-http` transport on `http://localhost:8000`
2. Set breakpoints in your code
3. Attach your debugger manually (see [debugpy documentation](https://github.com/microsoft/debugpy#debugpy) for examples)
4. Open MCP Inspector via `npx @modelcontextprotocol/inspector`
5. Connect to `http://localhost:8000/mcp/v1` using "Streamable HTTP" transport and "Via Proxy" connection type
6. Call tools from Inspector - your breakpoints will trigger
**Note:** `task dev` uses `streamable-http` by default. The `streamable-http` transport allows the debugger and MCP Inspector to work simultaneously without conflicts. To override, use `MCP_TRANSPORT=stdio task dev`.
If you encounter any problems, you can try running `task run` to see errors in your terminal.
## Release
Only people in the `CODEOWNERS` file should trigger a new release with these steps:
1. Consider these guidelines when choosing a version number:
- Major
- Removing a tool or toolset
- Changing the behavior of existing environment variables or configurations
- Minor
- Changes to config system related to the function signature of the register functions (e.g. `register_discovery_tools`)
- Adding optional parameters to a tool function signature
- Adding a new tool or toolset
- Removing or adding non-optional parameters from tool function signatures
- Patch
- Bug and security fixes - only major security and bug fixes will be back-ported to prior minor and major versions
- Dependency updates which don’t change behavior
- Minor enhancements
- Editing a tool or parameter description prompt
- Adding an allowed environment variable with the `DBT_MCP_` prefix
2. Trigger the [Create release PR Action](https://github.com/dbt-labs/dbt-mcp/actions/workflows/create-release-pr.yml).
- If the release is NOT a pre-release, just pick if the bump should be patch, minor or major
- If the release is a pre-release, set the bump and the pre-release suffix. We support alpha.N, beta.N and rc.N.
- use alpha for early releases of experimental features that specific people might want to test. Significant changes can be expected between alpha and the official release.
- use beta for releases that are mostly stable but still in development. It can be used to gather feedback from a group of peopleon how a specific feature should work.
- use rc for releases that are mostly stable and already feature complete. Only bugfixes and minor changes are expected between rc and the official release.
- Picking the prerelease suffix will depend on whether the last release was the stable release or a pre-release:
| Last Stable | Last Pre-release | Bump | Pre-release Suffix | Resulting Version |
| ----------- | ---------------- | ----- | ------------------ | ----------------- |
| 1.2.0 | - | minor | beta.1 | 1.3.0-beta.1 |
| 1.2.0 | 1.3.0-beta.1 | minor | beta.2 | 1.3.0-beta.2 |
| 1.2.0 | 1.3.0-beta.2 | minor | rc.1 | 1.3.0-rc.1 |
| 1.2.0 | 1.3.0-rc.1 | minor | | 1.3.0 |
| 1.2.0 | 1.3.0-beta.2 | minor | - | 1.3.0 |
| 1.2.0 | - | major | rc.1 | 2.0.0-rc.1 |
| 1.2.0 | 2.0.0-rc.1 | major | - | 2.0.0 |
3. Get this PR approved & merged in (if the resulting release name is not the one expected in the PR, just close the PR and try again step 1)
4. This will trigger the `Release dbt-mcp` Action. On the `Summary` page of this Action a member of the `CODEOWNERS` file will have to manually approve the release. The rest of the release process is automated.
```
--------------------------------------------------------------------------------
/examples/google_adk_agent/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/examples/langgraph_agent/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/examples/openai_agent/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/examples/openai_responses/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/examples/pydantic_ai_agent/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/src/client/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/src/dbt_mcp/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/src/dbt_mcp/dbt_admin/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/src/dbt_mcp/mcp/create.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/src/remote_mcp/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/tests/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/tests/integration/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/tests/integration/dbt_codegen/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/tests/integration/initialization/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/tests/unit/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/tests/unit/config/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/tests/unit/dbt_admin/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/tests/unit/dbt_cli/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/tests/unit/dbt_codegen/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/tests/unit/discovery/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/ui/src/index.css:
--------------------------------------------------------------------------------
```css
```
--------------------------------------------------------------------------------
/examples/aws_strands_agent/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/.changes/v0.2.17.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.17 - 2025-07-18
```
--------------------------------------------------------------------------------
/ui/src/global.d.ts:
--------------------------------------------------------------------------------
```typescript
declare module "*.css";
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/lsp/args/column_name.md:
--------------------------------------------------------------------------------
```markdown
The column name to trace lineage for.
```
--------------------------------------------------------------------------------
/ui/pnpm-workspace.yaml:
--------------------------------------------------------------------------------
```yaml
ignoredBuiltDependencies:
- esbuild
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/list.md:
--------------------------------------------------------------------------------
```markdown
List the resources in the your dbt project.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/oauth/client_id.py:
--------------------------------------------------------------------------------
```python
OAUTH_CLIENT_ID = "34ec61e834cdffd9dd90a32231937821"
```
--------------------------------------------------------------------------------
/tests/unit/lsp/__init__.py:
--------------------------------------------------------------------------------
```python
"""Unit tests for the dbt Fusion LSP integration."""
```
--------------------------------------------------------------------------------
/.changes/v0.2.11.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.11 - 2025-07-03
### Bug Fix
* fix order_by input
```
--------------------------------------------------------------------------------
/.changes/v0.1.3.md:
--------------------------------------------------------------------------------
```markdown
## v0.1.3 and before
* Initial releases before using changie
```
--------------------------------------------------------------------------------
/examples/aws_strands_agent/dbt_data_scientist/__init__.py:
--------------------------------------------------------------------------------
```python
from . import agent
from . import prompts
from . import tools
```
--------------------------------------------------------------------------------
/src/dbt_mcp/dbt_admin/run_results_errors/__init__.py:
--------------------------------------------------------------------------------
```python
from .parser import ErrorFetcher
__all__ = ["ErrorFetcher"]
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/__init__.py:
--------------------------------------------------------------------------------
```python
from dbt_mcp.prompts.prompts import get_prompt # noqa: F401
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/table_name.md:
--------------------------------------------------------------------------------
```markdown
The source table name to generate a base model for (required)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/source_name.md:
--------------------------------------------------------------------------------
```markdown
The source name as defined in your sources.yml file (required)
```
--------------------------------------------------------------------------------
/ui/src/vite-env.d.ts:
--------------------------------------------------------------------------------
```typescript
/// <reference types="vite/client" />
declare module "*.css";
```
--------------------------------------------------------------------------------
/.changes/v0.4.1.md:
--------------------------------------------------------------------------------
```markdown
## v0.4.1 - 2025-08-08
### Under the Hood
* Upgrade dbt-sl-sdk
```
--------------------------------------------------------------------------------
/src/dbt_mcp/dbt_codegen/__init__.py:
--------------------------------------------------------------------------------
```python
"""dbt-codegen MCP tools for automated dbt code generation."""
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/discovery/get_all_models.md:
--------------------------------------------------------------------------------
```markdown
Get the name and description of all dbt models in the environment.
```
--------------------------------------------------------------------------------
/.changes/v0.8.1.md:
--------------------------------------------------------------------------------
```markdown
## v0.8.1 - 2025-09-22
### Under the Hood
* Create ConfigProvider ABC
```
--------------------------------------------------------------------------------
/.changes/v0.2.19.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.19 - 2025-07-22
### Under the Hood
* Create list of tool names
```
--------------------------------------------------------------------------------
/.changes/v0.2.10.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.10 - 2025-07-03
### Enhancement or New Feature
* Upgrade MCP SDK
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/schema_name.md:
--------------------------------------------------------------------------------
```markdown
The schema name in your database that contains the source tables (required)
```
--------------------------------------------------------------------------------
/.changes/v0.2.3.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.3 - 2025-06-02
### Under the Hood
* Fix release action to fetch tags
```
--------------------------------------------------------------------------------
/.changes/v0.10.1.md:
--------------------------------------------------------------------------------
```markdown
## v0.10.1 - 2025-10-02
### Bug Fix
* Fix get_job_run_error truncated log output
```
--------------------------------------------------------------------------------
/.changes/v0.2.12.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.12 - 2025-07-09
### Bug Fix
* Catch every tool error and surface as string
```
--------------------------------------------------------------------------------
/.changes/v0.2.13.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.13 - 2025-07-11
### Under the Hood
* Decouple discovery tools from FastMCP
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/database_name.md:
--------------------------------------------------------------------------------
```markdown
The database that contains your source data (optional, defaults to target database)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/case_sensitive_cols.md:
--------------------------------------------------------------------------------
```markdown
Whether to quote column names to preserve case sensitivity (optional, default false)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/tables.md:
--------------------------------------------------------------------------------
```markdown
List of table names to generate base models for from the specified source (required)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/docs.md:
--------------------------------------------------------------------------------
```markdown
The docs command is responsible for generating your project's documentation website.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/materialized.md:
--------------------------------------------------------------------------------
```markdown
The materialization type for the model config block (optional, e.g., 'view', 'table')
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/include_data_types.md:
--------------------------------------------------------------------------------
```markdown
Whether to include data types in the model column definitions (optional, default true)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/leading_commas.md:
--------------------------------------------------------------------------------
```markdown
Whether to use leading commas instead of trailing commas in SQL (optional, default false)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/include_descriptions.md:
--------------------------------------------------------------------------------
```markdown
Whether to include placeholder descriptions in the generated YAML (optional, default false)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/generate_columns.md:
--------------------------------------------------------------------------------
```markdown
Whether to include column definitions in the generated source YAML (optional, default false)
```
--------------------------------------------------------------------------------
/.changes/v0.2.4.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.4 - 2025-06-03
### Bug Fix
* Add the missing selector argument when running commands
```
--------------------------------------------------------------------------------
/.changes/v0.10.0.md:
--------------------------------------------------------------------------------
```markdown
## v0.10.0 - 2025-10-01
### Enhancement or New Feature
* Add get_job_run_error to Admin API tools
```
--------------------------------------------------------------------------------
/.changes/v0.2.1.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.1 - 2025-05-28
### Under the Hood
* Remove hatch from tag action
* Manually triggering release
```
--------------------------------------------------------------------------------
/.changes/unreleased/Bug Fix-20251028-143835.yaml:
--------------------------------------------------------------------------------
```yaml
kind: Bug Fix
body: Minor update to the instruction for LSP tool
time: 2025-10-28T14:38:35.729371+01:00
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/build.md:
--------------------------------------------------------------------------------
```markdown
The dbt build command will:
- run models
- test tests
- snapshot snapshots
- seed seeds
In DAG order.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/upstream_descriptions.md:
--------------------------------------------------------------------------------
```markdown
Whether to include descriptions from upstream models for matching column names (optional, default false)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/test.md:
--------------------------------------------------------------------------------
```markdown
dbt test runs data tests defined on models, sources, snapshots, and seeds and unit tests defined on SQL models.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/table_names.md:
--------------------------------------------------------------------------------
```markdown
List of specific table names to generate source definitions for (optional, generates all tables if not specified)
```
--------------------------------------------------------------------------------
/.changes/unreleased/Enhancement or New Feature-20251014-175047.yaml:
--------------------------------------------------------------------------------
```yaml
kind: Enhancement or New Feature
body: This adds the get all sources tool.
time: 2025-10-14T17:50:47.539453+01:00
```
--------------------------------------------------------------------------------
/.changes/v0.9.1.md:
--------------------------------------------------------------------------------
```markdown
## v0.9.1 - 2025-09-30
### Under the Hood
* Reorganize code and add ability to format the arrow table differently
```
--------------------------------------------------------------------------------
/.changes/unreleased/Under the Hood-20251030-151902.yaml:
--------------------------------------------------------------------------------
```yaml
kind: Under the Hood
body: Add version number guidelines to contributing.md
time: 2025-10-30T15:19:02.963083-05:00
```
--------------------------------------------------------------------------------
/.changes/v0.2.15.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.15 - 2025-07-16
### Under the Hood
* Refactor sl tools for reusability
* Update VSCode instructions in README
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/args/sql_query.md:
--------------------------------------------------------------------------------
```markdown
This is the SQL query to run against the data platform. Do not add a limit to this query. Use the `limit` argument instead.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/prompts.py:
--------------------------------------------------------------------------------
```python
from pathlib import Path
def get_prompt(name: str) -> str:
return (Path(__file__).parent / f"{name}.md").read_text()
```
--------------------------------------------------------------------------------
/examples/aws_strands_agent/dbt_data_scientist/tools/__init__.py:
--------------------------------------------------------------------------------
```python
from .dbt_compile import dbt_compile
from .dbt_mcp import dbt_mcp_tool
from .dbt_model_analyzer import dbt_model_analyzer_agent
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/args/full_refresh.md:
--------------------------------------------------------------------------------
```markdown
If true, dbt will force a complete rebuild of incremental models (built from scratch) rather than processing new or modifed data.
```
--------------------------------------------------------------------------------
/.changes/v0.2.16.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.16 - 2025-07-18
### Under the Hood
* Adding the ability to exclude certain tools when registering
* OpenAI responses example
```
--------------------------------------------------------------------------------
/ui/tsconfig.json:
--------------------------------------------------------------------------------
```json
{
"files": [],
"references": [
{
"path": "./tsconfig.app.json"
},
{
"path": "./tsconfig.node.json"
}
]
}
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/model_name.md:
--------------------------------------------------------------------------------
```markdown
The name of the model to generate import CTEs for, search for the model name provided with and without extension provided by users(required)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/args/model_names.md:
--------------------------------------------------------------------------------
```markdown
List of model names to generate YAML documentation for, search for the model names provided with and without extension provided by users(required)
```
--------------------------------------------------------------------------------
/.vscode/settings.json:
--------------------------------------------------------------------------------
```json
{
"python.testing.pytestArgs": [
"tests",
"evals"
],
"python.testing.pytestEnabled": true,
"python.testing.unittestEnabled": false
}
```
--------------------------------------------------------------------------------
/.changes/v0.2.14.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.14 - 2025-07-14
### Enhancement or New Feature
* Make dbt CLI command timeout configurable
### Bug Fix
* Allow passing entities in the group by
```
--------------------------------------------------------------------------------
/src/dbt_mcp/errors/base.py:
--------------------------------------------------------------------------------
```python
"""Base error class for all dbt-mcp tool calls."""
class ToolCallError(Exception):
"""Base exception for all tool call errors in dbt-mcp."""
pass
```
--------------------------------------------------------------------------------
/.changes/v0.6.0.md:
--------------------------------------------------------------------------------
```markdown
## v0.6.0 - 2025-08-22
### Under the Hood
* Update docs with new tools
* Using streamable http for SQL tools
* Correctly handle admin API host containing protocol prefix
```
--------------------------------------------------------------------------------
/.changes/v0.9.0.md:
--------------------------------------------------------------------------------
```markdown
## v0.9.0 - 2025-09-30
### Enhancement or New Feature
* Adding the dbt codegen toolset.
### Under the Hood
* Updates README with new tools
* Fix .user.yml error with Fusion
```
--------------------------------------------------------------------------------
/.changes/v0.8.3.md:
--------------------------------------------------------------------------------
```markdown
## v0.8.3 - 2025-09-24
### Under the Hood
* Rename SemanticLayerConfig.service_token to SemanticLayerConfig.token
### Bug Fix
* Fix Error handling as per native MCP error spec
```
--------------------------------------------------------------------------------
/.changes/v0.6.1.md:
--------------------------------------------------------------------------------
```markdown
## v0.6.1 - 2025-08-28
### Enhancement or New Feature
* Add support for --vars flag
* Allow headers in AdminApiConfig
### Under the Hood
* Remove redundant and outdated documentation
```
--------------------------------------------------------------------------------
/examples/openai_responses/pyproject.toml:
--------------------------------------------------------------------------------
```toml
[project]
name = "openai-responses"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.12"
dependencies = [
"openai>=1.95.1",
]
```
--------------------------------------------------------------------------------
/.changes/v0.10.3.md:
--------------------------------------------------------------------------------
```markdown
## v0.10.3 - 2025-10-08
### Under the Hood
* Improved retry logic and post project selection screen
* Avoid double counting in usage tracking proxied tools
* Categorizing ToolCallErrors
```
--------------------------------------------------------------------------------
/examples/pydantic_ai_agent/pyproject.toml:
--------------------------------------------------------------------------------
```toml
[project]
name = "pydantic-ai-agent"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.10"
dependencies = [
"pydantic-ai>=0.8.1",
]
```
--------------------------------------------------------------------------------
/src/dbt_mcp/errors/semantic_layer.py:
--------------------------------------------------------------------------------
```python
"""Semantic Layer tool errors."""
from dbt_mcp.errors.base import ToolCallError
class SemanticLayerToolCallError(ToolCallError):
"""Base exception for Semantic Layer tool errors."""
pass
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/args/limit.md:
--------------------------------------------------------------------------------
```markdown
Limit the number of rows that the data platform will return. Use this in place of a `LIMIT` clause in the SQL query. If no limit is passed, use the default of 5 to prevent returning a very large result set.
```
--------------------------------------------------------------------------------
/.changes/v0.2.6.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.6 - 2025-06-16
### Under the Hood
* Instructing the LLM to more likely use a selector
* Instruct LLM to add limit as an argument instead of SQL
* Fix use of limit in dbt show
* Indicate type checking
```
--------------------------------------------------------------------------------
/.changes/v0.4.2.md:
--------------------------------------------------------------------------------
```markdown
## v0.4.2 - 2025-08-13
### Enhancement or New Feature
* Add default --limit to show tool
### Under the Hood
* Define toolsets
### Bug Fix
* Fix the prompt to ensure grain is passed even for non-time group by"
```
--------------------------------------------------------------------------------
/.changes/v0.2.8.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.8 - 2025-07-02
### Enhancement or New Feature
* Raise errors if no node is selected (can also be configured)
### Bug Fix
* Fix when people provide `DBT_PROJECT_DIR` as a relative path
* Fix link in README
```
--------------------------------------------------------------------------------
/examples/openai_agent/pyproject.toml:
--------------------------------------------------------------------------------
```toml
[project]
name = "openai-agent"
version = "0.1.0"
description = "A simple example of using this MCP server with OpenAI Agents"
readme = "README.md"
requires-python = ">=3.12"
dependencies = ["openai-agents>=0.1.0"]
```
--------------------------------------------------------------------------------
/.changes/v0.2.9.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.9 - 2025-07-02
### Enhancement or New Feature
* Decrease amount of data retrieved when listing models
### Under the Hood
* OpenAI conversational analytics example
* README updates
* Move Discover headers to config
```
--------------------------------------------------------------------------------
/examples/google_adk_agent/pyproject.toml:
--------------------------------------------------------------------------------
```toml
[project]
name = "google-adk-dbt-agent"
version = "0.1.0"
description = "Google ADK agent for dbt MCP"
readme = "README.md"
requires-python = ">=3.10"
dependencies = [
"google-adk>=0.4.0",
"google-genai<=1.34.0",
]
```
--------------------------------------------------------------------------------
/.changes/v0.8.2.md:
--------------------------------------------------------------------------------
```markdown
## v0.8.2 - 2025-09-23
### Enhancement or New Feature
* Use `dbt --help` to identify binary type
* Increase dbt CLI timeout default
### Under the Hood
* Implement SemanticLayerClientProvider
### Bug Fix
* Update how we identify CLIs
```
--------------------------------------------------------------------------------
/.changes/v0.2.7.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.7 - 2025-06-30
### Under the Hood
* Timeout dbt list command
* Troubleshooting section in README on clients not finding uvx
* Update Discovery config for simpler usage
### Bug Fix
* Fixing bug when ordering SL query by a metric
```
--------------------------------------------------------------------------------
/.changes/v0.7.0.md:
--------------------------------------------------------------------------------
```markdown
## v0.7.0 - 2025-09-09
### Enhancement or New Feature
* Add tools to retrieve exposure information from Disco API
### Under the Hood
* Expect string sub in oauth JWT
* Using sync endpoints for oauth FastAPI server
* Fix release pipeline
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/compile.md:
--------------------------------------------------------------------------------
```markdown
dbt compile generates executable SQL from source model, test, and analysis files.
The compile command is useful for visually inspecting the compiled output of model files. This is useful for validating complex jinja logic or macro usage.
```
--------------------------------------------------------------------------------
/examples/langgraph_agent/pyproject.toml:
--------------------------------------------------------------------------------
```toml
[project]
name = "langgraph-agent"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.12"
dependencies = [
"langchain-mcp-adapters>=0.1.9",
"langchain[anthropic]>=0.3.27",
"langgraph>=0.6.4",
]
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/discovery/get_mart_models.md:
--------------------------------------------------------------------------------
```markdown
Get the name and description of all mart models in the environment. A mart model is part of the presentation layer of the dbt project. It's where cleaned, transformed data is organized for consumption by end-users, like analysts, dashboards, or business tools.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/show.md:
--------------------------------------------------------------------------------
```markdown
dbt show executes an arbitrary SQL statement against the database and returns the results. It is useful for debugging and inspecting data in your dbt project. If you are adding a limit be sure to use the `limit` argument and do not add a limit to the SQL query.
```
--------------------------------------------------------------------------------
/.changes/v0.8.4.md:
--------------------------------------------------------------------------------
```markdown
## v0.8.4 - 2025-09-29
### Enhancement or New Feature
* Allow doc files to skip changie requirements
### Under the Hood
* Upgrade @vitejs/plugin-react
* Add ruff lint config to enforce Python 3.9+ coding style
* Opt-out of usage tracking with standard dbt methods
```
--------------------------------------------------------------------------------
/.changes/v0.2.18.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.18 - 2025-07-22
### Enhancement or New Feature
* Move env var parsing to pydantic_settings for better validation
### Under the Hood
* Add integration test for server initialization
### Bug Fix
* Fix SL validation error message when no misspellings are found
```
--------------------------------------------------------------------------------
/.changes/v0.4.0.md:
--------------------------------------------------------------------------------
```markdown
## v0.4.0 - 2025-08-08
### Enhancement or New Feature
* Tool policies
* Added Semantic Layer tool to get compiled sql
### Under the Hood
* Fix JSON formatting in README
* Document dbt Copilot credits relationship
### Bug Fix
* Make model_name of get_model_details optional
```
--------------------------------------------------------------------------------
/src/dbt_mcp/errors/sql.py:
--------------------------------------------------------------------------------
```python
"""SQL tool errors."""
from dbt_mcp.errors.base import ToolCallError
class SQLToolCallError(ToolCallError):
"""Base exception for SQL tool errors."""
pass
class RemoteToolError(SQLToolCallError):
"""Exception raised when a remote SQL tool call fails."""
pass
```
--------------------------------------------------------------------------------
/.changes/v0.2.5.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.5 - 2025-06-06
### Under the Hood
* Small improvements to improve logging and code organization.
* Move `--selector` to the code instead of the prompt
* Cursor deeplink setup
* Fix Cursor deeplinks
* Fix Cursor env var mess up
### Bug Fix
* Fix Discovery API config enablement
```
--------------------------------------------------------------------------------
/.changes/v0.2.2.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.2 - 2025-06-02
### Under the Hood
* Update README to run the MCP server with uvx
* Logging usage events
* Improve remote tools error logging
* Move create-release-tag to release Action
* Update release process documentation
### Bug Fix
* Fix typo in GH action to create release
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/parse.md:
--------------------------------------------------------------------------------
```markdown
The dbt parse command parses and validates the contents of your dbt project. If your project contains Jinja or YAML syntax errors, the command will fail.
It will also produce an artifact with detailed timing information, which is useful to understand parsing times for large projects.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/lsp/args/model_id.md:
--------------------------------------------------------------------------------
```markdown
The fully qualified dbt model identifier (e.g., "model.my_project_name.my_model").
Do not use just the model name, always use the model full identifier. If you don't have the full identifier, the project name is the field `name:` in the `dbt_project.yml` file at the root of the dbt project.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/errors/cli.py:
--------------------------------------------------------------------------------
```python
"""dbt CLI tool errors."""
from dbt_mcp.errors.base import ToolCallError
class CLIToolCallError(ToolCallError):
"""Base exception for dbt CLI tool errors."""
pass
class BinaryExecutionError(CLIToolCallError):
"""Exception raised when dbt binary execution fails."""
pass
```
--------------------------------------------------------------------------------
/ui/index.html:
--------------------------------------------------------------------------------
```html
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>dbt MCP</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="/src/main.tsx"></script>
</body>
</html>
```
--------------------------------------------------------------------------------
/src/dbt_mcp/config/dbt_project.py:
--------------------------------------------------------------------------------
```python
from pydantic import BaseModel, ConfigDict
class DbtProjectFlags(BaseModel):
model_config = ConfigDict(extra="allow")
send_anonymous_usage_stats: bool | None = None
class DbtProjectYaml(BaseModel):
model_config = ConfigDict(extra="allow")
flags: None | DbtProjectFlags = None
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/args/resource_type.md:
--------------------------------------------------------------------------------
```markdown
It is possible to list specific resource types we want to return.
We can pick any from the following and need to return a list of all the resource types to select:
- metric
- semantic_model
- saved_query
- source
- analysis
- model
- test
- unit_test
- exposure
- snapshot
- seed
- default
- all
```
--------------------------------------------------------------------------------
/src/dbt_mcp/errors/common.py:
--------------------------------------------------------------------------------
```python
"""Common errors used across multiple tool types."""
from dbt_mcp.errors.base import ToolCallError
class InvalidParameterError(ToolCallError):
"""Exception raised when invalid or missing parameters are provided.
This is a cross-cutting error used by multiple tool types.
"""
pass
```
--------------------------------------------------------------------------------
/src/dbt_mcp/oauth/logging.py:
--------------------------------------------------------------------------------
```python
import logging
def disable_server_logs() -> None:
# Disable uvicorn, fastapi, and related loggers
loggers = (
"uvicorn",
"uvicorn.error",
"uvicorn.access",
"fastapi",
)
for logger_name in loggers:
logging.getLogger(logger_name).disabled = True
```
--------------------------------------------------------------------------------
/.changes/header.tpl.md:
--------------------------------------------------------------------------------
```markdown
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html),
and is generated by [Changie](https://github.com/miniscruff/changie).
```
--------------------------------------------------------------------------------
/.changes/v1.0.0.md:
--------------------------------------------------------------------------------
```markdown
## v1.0.0 - 2025-10-20
### Enhancement or New Feature
* Incroduce support for fusion LSP
### Under the Hood
* Add support for Python debugger
* Update pyproject.toml including development status
* Add example for aws_strands_agent
### Bug Fix
* Exclude Python 3.14 for now as pyarrow hasn't released wheels yet
```
--------------------------------------------------------------------------------
/.vscode/launch.json:
--------------------------------------------------------------------------------
```json
{
"configurations": [
{
"console": "integratedTerminal",
"env": {
"MCP_TRANSPORT": "streamable-http"
},
"name": "debug dbt-mcp",
"program": "${workspaceFolder}/src/dbt_mcp/main.py",
"request": "launch",
"type": "debugpy"
}
],
"version": "0.2.0"
}
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/run.md:
--------------------------------------------------------------------------------
```markdown
dbt run executes compiled sql model files against the current target database. dbt connects to the target database and runs the relevant SQL required to materialize all data models using the specified materialization strategies. Models are run in the order defined by the dependency graph generated during compilation.
```
--------------------------------------------------------------------------------
/.changes/v0.2.20.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.20 - 2025-07-25
### Enhancement or New Feature
* Allow for disabling CLI tools
### Under the Hood
* Update codeowners
* Improve DISABLE_TOOLS configuration
* Remote MCP example
* Add unit tests for env vars combinations
* Add instructions for Claude Code in README
* Add new example for OpenAI + HTTP Streamable MCP
```
--------------------------------------------------------------------------------
/tests/integration/tracking/test_tracking.py:
--------------------------------------------------------------------------------
```python
import pytest
from dbtlabs_vortex.producer import shutdown
from dbt_mcp.config.config import load_config
from dbt_mcp.mcp.server import create_dbt_mcp
@pytest.mark.asyncio
async def test_tracking():
config = load_config()
await (await create_dbt_mcp(config)).call_tool("list_metrics", {"foo": "bar"})
shutdown()
```
--------------------------------------------------------------------------------
/src/dbt_mcp/errors/discovery.py:
--------------------------------------------------------------------------------
```python
"""Discovery/Metadata API tool errors."""
from dbt_mcp.errors.base import ToolCallError
class DiscoveryToolCallError(ToolCallError):
"""Base exception for Discovery/Metadata API tool errors."""
pass
class GraphQLError(DiscoveryToolCallError):
"""Exception raised for GraphQL API and query errors."""
pass
```
--------------------------------------------------------------------------------
/examples/remote_mcp/pyproject.toml:
--------------------------------------------------------------------------------
```toml
[project]
name = "remote-mcp"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.12"
dependencies = ["mcp>=1.12.1"]
[build-system]
requires = ["setuptools>=61.0"]
build-backend = "setuptools.build_meta"
[tool.setuptools.packages.find]
where = ["../../src"]
include = ["remote_mcp*"]
```
--------------------------------------------------------------------------------
/.changes/v0.6.2.md:
--------------------------------------------------------------------------------
```markdown
## v0.6.2 - 2025-09-08
### Enhancement or New Feature
* Adding the ability to return the config.meta attribute from list metrics to give the LLM more context
* Oauth initial implementation
* Fix #251 - Add flag for no color + ability to detect binary type
### Under the Hood
* Add docs for using the MCP server with Pydantic AI
* Don't run mypy on examples
```
--------------------------------------------------------------------------------
/.changes/v0.3.0.md:
--------------------------------------------------------------------------------
```markdown
## v0.3.0 - 2025-08-05
### Enhancement or New Feature
* Add ToolAnnotations
* Add alias field to GET_MODEL_DETAILS GraphQL query
### Under the Hood
* Test remote tool equality
* Fix initialization integration test
* Refactor README
* Rename Remote Tools to SQL Tools
* Document Remote MCP
* Improved Remote MCP instructions
### Bug Fix
* Apply dbt_cli_timeout to all dbt commands
```
--------------------------------------------------------------------------------
/src/dbt_mcp/lsp/__init__.py:
--------------------------------------------------------------------------------
```python
"""LSP (Language Server Protocol) integration for dbt Fusion."""
from dbt_mcp.lsp.lsp_binary_manager import LspBinaryInfo
from dbt_mcp.lsp.lsp_client import LSPClient
from dbt_mcp.lsp.lsp_connection import (
LSPConnection,
LspConnectionState,
LspEventName,
)
__all__ = [
"LSPClient",
"LSPConnection",
"LspBinaryInfo",
"LspConnectionState",
"LspEventName",
]
```
--------------------------------------------------------------------------------
/.changes/v0.10.2.md:
--------------------------------------------------------------------------------
```markdown
## v0.10.2 - 2025-10-08
### Enhancement or New Feature
* Improved oauth error handling
* Remove oauth env var feature flag. Enable oauth broadly.
### Under the Hood
* Improved logging for development
* Updating prompts to include examples to avoid bad parameter generation
* Remove DBT_HOST prefix
* Update usage tracking with new fields
* Write .user.yml if it does not exist
* Changed UsageTracker to a protocol
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/discovery/get_exposures.md:
--------------------------------------------------------------------------------
```markdown
Get the id, name, description, and url of all exposures in the dbt environment. Exposures represent downstream applications or analyses that depend on dbt models.
Returns information including:
- uniqueId: The unique identifier for this exposure taht can then be used to get more details about the exposure
- name: The name of the exposure
- description: Description of the exposure
- url: URL associated with the exposure
```
--------------------------------------------------------------------------------
/src/dbt_mcp/main.py:
--------------------------------------------------------------------------------
```python
import asyncio
import os
from dbt_mcp.config.config import load_config
from dbt_mcp.config.transport import validate_transport
from dbt_mcp.mcp.server import create_dbt_mcp
def main() -> None:
config = load_config()
server = asyncio.run(create_dbt_mcp(config))
transport = validate_transport(os.environ.get("MCP_TRANSPORT", "stdio"))
server.run(transport=transport)
if __name__ == "__main__":
main()
```
--------------------------------------------------------------------------------
/src/dbt_mcp/errors/admin_api.py:
--------------------------------------------------------------------------------
```python
"""Admin API tool errors."""
from dbt_mcp.errors.base import ToolCallError
class AdminAPIToolCallError(ToolCallError):
"""Base exception for Admin API tool errors."""
pass
class AdminAPIError(AdminAPIToolCallError):
"""Exception raised for Admin API communication errors."""
pass
class ArtifactRetrievalError(AdminAPIToolCallError):
"""Exception raised when artifact retrieval fails."""
pass
```
--------------------------------------------------------------------------------
/.github/actions/setup-python/action.yml:
--------------------------------------------------------------------------------
```yaml
name: Setup Python
description: Setup Python for ai-codegen-api
runs:
using: "composite"
steps:
- name: Setup python
id: setup-python
uses: actions/setup-python@v5
with:
python-version: 3.13
- name: Setup uv
uses: astral-sh/setup-uv@v4
with:
enable-cache: true
cache-dependency-glob: "uv.lock"
- name: Install the project
shell: bash
run: uv sync
```
--------------------------------------------------------------------------------
/ui/vite.config.ts:
--------------------------------------------------------------------------------
```typescript
import { defineConfig } from "vite";
import react from "@vitejs/plugin-react";
// https://vite.dev/config/
export default defineConfig({
plugins: [react()],
// Use relative asset URLs so the app works when served from any base path
base: "./",
build: {
// Emit into the Python package so assets are included in sdist/wheels
outDir: "../src/dbt_mcp/ui/dist",
emptyOutDir: true,
assetsDir: "assets",
},
});
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/semantic_layer/list_metrics.md:
--------------------------------------------------------------------------------
```markdown
List all metrics from the dbt Semantic Layer.
If the user is asking a data-related or business-related question,
this tool should be used as a first step to get a list of metrics
that can be used with other tools to answer the question.
Examples:
- "What are the top 5 products by revenue?"
- "How many users did we have last month?"
<parameters>
search: Optional string used to filter metrics by name using partial matches
</parameters>
```
--------------------------------------------------------------------------------
/.changes/v0.5.0.md:
--------------------------------------------------------------------------------
```markdown
## v0.5.0 - 2025-08-20
### Enhancement or New Feature
* Add support for --full-refresh flag
* Adds a new tool to get model health (last run, tests, source freshness) from discovery API
* Add operational/admin tools to interact with the dbt platform
### Under the Hood
* LangGraph create_react_agent example
* Make model_name optional for more discovery tools
* Update example with OpenAI to show tool calls
### Bug Fix
* Fix for timeout on Windows
```
--------------------------------------------------------------------------------
/src/client/tools.py:
--------------------------------------------------------------------------------
```python
from openai.types.responses import (
FunctionToolParam,
)
from dbt_mcp.mcp.server import DbtMCP
async def get_tools(dbt_mcp: DbtMCP) -> list[FunctionToolParam]:
mcp_tools = await dbt_mcp.list_tools()
return [
FunctionToolParam(
type="function",
name=t.name,
description=t.description,
parameters=t.inputSchema,
strict=False,
)
for t in mcp_tools
]
```
--------------------------------------------------------------------------------
/tests/integration/initialization/test_initialization.py:
--------------------------------------------------------------------------------
```python
import asyncio
from unittest.mock import patch
from dbt_mcp.mcp.server import create_dbt_mcp
from tests.mocks.config import mock_config
def test_initialization():
with patch("dbt_mcp.config.config.load_config", return_value=mock_config):
result = asyncio.run(create_dbt_mcp(mock_config))
assert result is not None
assert hasattr(result, "usage_tracker")
tools = asyncio.run(result.list_tools())
assert isinstance(tools, list)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/tools/definitions.py:
--------------------------------------------------------------------------------
```python
from collections.abc import Callable
from dataclasses import dataclass
from mcp.types import ToolAnnotations
@dataclass
class ToolDefinition:
fn: Callable
description: str
name: str | None = None
title: str | None = None
annotations: ToolAnnotations | None = None
# We haven't strictly defined our tool contracts yet.
# So we're setting this to False by default for now.
structured_output: bool | None = False
def get_name(self) -> str:
return self.name or self.fn.__name__
```
--------------------------------------------------------------------------------
/src/dbt_mcp/semantic_layer/gql/gql_request.py:
--------------------------------------------------------------------------------
```python
import requests
from dbt_mcp.config.config_providers import SemanticLayerConfig
from dbt_mcp.gql.errors import raise_gql_error
def submit_request(
sl_config: SemanticLayerConfig,
payload: dict,
) -> dict:
if "variables" not in payload:
payload["variables"] = {}
payload["variables"]["environmentId"] = sl_config.prod_environment_id
r = requests.post(
sl_config.url, json=payload, headers=sl_config.headers_provider.get_headers()
)
result = r.json()
raise_gql_error(result)
return result
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/args/vars.md:
--------------------------------------------------------------------------------
```markdown
Variables can be passed to dbt commands using the vars parameter. Variables can be accessed in dbt code using `{{ var('variable_name') }}`.
Note: The vars parameter must be passed as a simple STRING with no special characters (i.e "\", "\n", etc). Do not pass in a dictionary object.
Supported formats:
- Single variable (curly brackets optional): `"variable_name: value"`
- Multiple variables (curly brackets needed): `"{"key1": "value1", "key2": "value2"}"`
- Mixed types: `"{"string_var": "hello", "number_var": 42, "boolean_var": true}"`
```
--------------------------------------------------------------------------------
/.github/workflows/codeowners-check.yml:
--------------------------------------------------------------------------------
```yaml
name: CODEOWNERS Coverage Check
on:
pull_request:
workflow_dispatch:
jobs:
validate-codeowners:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
- uses: mszostok/codeowners-validator@7f3f5e28c6d7b8dfae5731e54ce2272ca384592f
with:
github_access_token: "${{ secrets.OWNERS_VALIDATOR_GITHUB_SECRET }}"
checks: "duppatterns"
experimental_checks: "notowned"
```
--------------------------------------------------------------------------------
/src/dbt_mcp/config/dbt_yaml.py:
--------------------------------------------------------------------------------
```python
from pathlib import Path
import yaml
def try_read_yaml(file_path: Path) -> dict | None:
try:
suffix = file_path.suffix.lower()
if suffix not in {".yml", ".yaml"}:
return None
alternate_suffix = ".yaml" if suffix == ".yml" else ".yml"
alternate_path = file_path.with_suffix(alternate_suffix)
if file_path.exists():
return yaml.safe_load(file_path.read_text())
if alternate_path.exists():
return yaml.safe_load(alternate_path.read_text())
except Exception:
return None
return None
```
--------------------------------------------------------------------------------
/ui/tsconfig.node.json:
--------------------------------------------------------------------------------
```json
{
"compilerOptions": {
"allowImportingTsExtensions": true,
"erasableSyntaxOnly": true,
"lib": [
"ES2023"
],
"module": "ESNext",
"moduleDetection": "force",
"moduleResolution": "bundler",
"noEmit": true,
"noFallthroughCasesInSwitch": true,
"noUncheckedSideEffectImports": true,
"noUnusedLocals": true,
"noUnusedParameters": true,
"skipLibCheck": true,
"strict": true,
"target": "ES2023",
"tsBuildInfoFile": "./node_modules/.tmp/tsconfig.node.tsbuildinfo",
"verbatimModuleSyntax": true
},
"include": [
"vite.config.ts"
]
}
```
--------------------------------------------------------------------------------
/ui/eslint.config.js:
--------------------------------------------------------------------------------
```javascript
import js from '@eslint/js'
import globals from 'globals'
import reactHooks from 'eslint-plugin-react-hooks'
import reactRefresh from 'eslint-plugin-react-refresh'
import tseslint from 'typescript-eslint'
import { globalIgnores } from 'eslint/config'
export default tseslint.config([
globalIgnores(['dist']),
{
files: ['**/*.{ts,tsx}'],
extends: [
js.configs.recommended,
tseslint.configs.recommended,
reactHooks.configs['recommended-latest'],
reactRefresh.configs.vite,
],
languageOptions: {
ecmaVersion: 2020,
globals: globals.browser,
},
},
])
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/lsp/get_column_lineage.md:
--------------------------------------------------------------------------------
```markdown
Get the column-level lineage for a specific column in a dbt model.
This tool traces how a column's value is derived from upstream sources through transformations, showing the complete lineage path from source tables to the target column. It's useful for understanding data flow, debugging data quality issues, and impact analysis.
The lineage includes:
- Upstream columns that contribute to this column
- SQL transformations applied
- Intermediate models in the lineage path
- Source tables and columns
Use this when you need to understand where a column's data comes from or which upstream changes might affect it.
```
--------------------------------------------------------------------------------
/tests/integration/remote_mcp/test_remote_mcp.py:
--------------------------------------------------------------------------------
```python
from dbt_mcp.config.config import load_config
from dbt_mcp.mcp.server import create_dbt_mcp
from remote_mcp.session import session_context
async def test_remote_mcp_list_metrics_equals_local_mcp() -> None:
async with session_context() as session:
config = load_config()
dbt_mcp = await create_dbt_mcp(config)
remote_metrics = await session.call_tool(
name="list_metrics",
arguments={},
)
local_metrics = await dbt_mcp.call_tool(
name="list_metrics",
arguments={},
)
assert remote_metrics.content == local_metrics
```
--------------------------------------------------------------------------------
/src/dbt_mcp/gql/errors.py:
--------------------------------------------------------------------------------
```python
from dbt_mcp.errors import GraphQLError
def raise_gql_error(result: dict) -> None:
if result.get("errors"):
if len(result.get("errors", [])) > 0:
error_messages = [
error.get("message", "Unknown error")
for error in result.get("errors", [])
if isinstance(error, dict)
]
if error_messages:
raise GraphQLError(f"Errors calling API: {', '.join(error_messages)}")
raise GraphQLError(
"Unknown error calling API. "
+ "Check your configuration or contact support if this persists."
)
```
--------------------------------------------------------------------------------
/ui/package.json:
--------------------------------------------------------------------------------
```json
{
"dependencies": {
"react": "^19.1.1",
"react-dom": "^19.1.1"
},
"devDependencies": {
"@eslint/js": "^9.33.0",
"@types/react": "^19.1.10",
"@types/react-dom": "^19.1.7",
"@vitejs/plugin-react": "^5.0.2",
"eslint": "^9.33.0",
"eslint-plugin-react-hooks": "^5.2.0",
"eslint-plugin-react-refresh": "^0.4.20",
"globals": "^16.3.0",
"typescript": "~5.8.3",
"typescript-eslint": "^8.39.1",
"vite": "^7.1.11"
},
"name": "dbt-mcp",
"private": true,
"scripts": {
"build": "tsc -b && vite build",
"dev": "vite",
"lint": "eslint .",
"preview": "vite preview"
},
"type": "module",
"version": "0.0.0"
}
```
--------------------------------------------------------------------------------
/ui/tsconfig.app.json:
--------------------------------------------------------------------------------
```json
{
"compilerOptions": {
"allowImportingTsExtensions": true,
"erasableSyntaxOnly": true,
"jsx": "react-jsx",
"lib": [
"ES2022",
"DOM",
"DOM.Iterable"
],
"module": "ESNext",
"moduleDetection": "force",
"moduleResolution": "bundler",
"noEmit": true,
"noFallthroughCasesInSwitch": true,
"noUncheckedSideEffectImports": true,
"noUnusedLocals": true,
"noUnusedParameters": true,
"skipLibCheck": true,
"strict": true,
"target": "ES2022",
"tsBuildInfoFile": "./node_modules/.tmp/tsconfig.app.tsbuildinfo",
"useDefineForClassFields": true,
"verbatimModuleSyntax": true
},
"include": [
"src"
]
}
```
--------------------------------------------------------------------------------
/src/dbt_mcp/config/transport.py:
--------------------------------------------------------------------------------
```python
import logging
from typing import Literal
logger = logging.getLogger(__name__)
TransportType = Literal["stdio", "sse", "streamable-http"]
VALID_TRANSPORTS: set[TransportType] = {"stdio", "sse", "streamable-http"}
def validate_transport(transport: str) -> TransportType:
"""Validate and return the MCP transport type."""
transport = transport.strip().lower()
if transport not in VALID_TRANSPORTS:
valid_options = ", ".join(sorted(VALID_TRANSPORTS))
raise ValueError(
f"Invalid MCP_TRANSPORT: '{transport}'. Must be one of: {valid_options}"
)
logger.debug(f"Using MCP transport: {transport}")
return transport # type: ignore[return-value]
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/generate_model_yaml.md:
--------------------------------------------------------------------------------
```markdown
Generate YAML documentation for dbt models by introspecting their compiled SQL. This tool analyzes one or more models to produce complete schema.yml entries with all column names and optionally their data types. Can intelligently inherit column descriptions from upstream models and sources for consistent documentation. Essential for maintaining comprehensive model documentation and enabling dbt's testing framework.
Note: This is one of three dbt-codegen tools (generate_source, generate_model_yaml, generate_staging_model) that are available when dbt-codegen is enabled. These tools are opt-in and must be explicitly enabled in the configuration.
Always return the generated YAML output to the user.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/generate_source.md:
--------------------------------------------------------------------------------
```markdown
Generate lightweight YAML for dbt sources by introspecting database schemas. This tool queries your warehouse to discover tables in a schema and produces the YAML structure for a source that can be pasted into a schema.yml file. Supports selective table generation and can optionally include column definitions with data types. Perfect for bootstrapping new sources or documenting existing database schemas in your dbt project.
Note: This is one of three dbt-codegen tools (generate_source, generate_model_yaml, generate_staging_model) that are available when dbt-codegen is enabled. These tools are opt-in and must be explicitly enabled in the configuration.
Always return the generated YAML output to the user.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_codegen/generate_staging_model.md:
--------------------------------------------------------------------------------
```markdown
Generate SQL for a staging model from a source table. This creates a complete SELECT statement with all columns from the source, properly aliased and formatted according to dbt best practices. Includes optional model configuration block for materialization, column name casing preferences, and comma placement style. The generated SQL serves as the foundation for your staging layer and can be directly saved as a new model file.
Note: This is one of three dbt-codegen tools (generate_source, generate_model_yaml, generate_staging_model) that are available when dbt-codegen is enabled. These tools are opt-in and must be explicitly enabled in the configuration.
Always return the generated SQL output to the user.
```
--------------------------------------------------------------------------------
/.changes/v0.8.0.md:
--------------------------------------------------------------------------------
```markdown
## v0.8.0 - 2025-09-22
### Enhancement or New Feature
* Allow creating pre-releases
* Return compiled code in get_model_details
### Under the Hood
* Handle Claude Desktop running multiple MCP server instances
* Add docs for using the MCP server with google ADK and dbt-core
* Add search string to SL metadata queries
* Improve parameters in query_metrics examples
* Reduce token usage in `get_job_run_details` response by removing debug param and unnecessary logs
* Automatically refresh oauth token
* Improve dbt platform context mcp.yml parsing
* Add PR and issue templates
* Address claude desktop re-triggering oauth on exit
* Turning off caching for static files
### Bug Fix
* Add account id to dbt platform context
```
--------------------------------------------------------------------------------
/.github/pull_request_template.md:
--------------------------------------------------------------------------------
```markdown
## Summary
<!-- Provide a brief description of the changes in this PR -->
## What Changed
<!-- Describe the changes made in this PR -->
## Why
<!-- Explain the motivation for these changes -->
## Related Issues
<!-- Link any related issues using #issue_number -->
Closes #
Related to #
## Checklist
- [ ] I have performed a self-review of my code
- [ ] I have made corresponding changes to the documentation (in https://github.com/dbt-labs/docs.getdbt.com) if required -- Mention it here
- [ ] I have added tests that prove my fix is effective or that my feature works
- [ ] New and existing unit tests pass locally with my changes
## Additional Notes
<!-- Any additional information that would be helpful for reviewers -->
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/admin_api/list_jobs.md:
--------------------------------------------------------------------------------
```markdown
List all jobs in a dbt platform account with optional filtering.
This tool retrieves jobs from the dbt Admin API. Jobs are the configuration for scheduled or triggered dbt runs.
## Parameters
- **project_id** (optional): Filter jobs by specific project ID
- **environment_id** (optional): Filter jobs by specific environment ID
- **limit** (optional): Maximum number of results to return
- **offset** (optional): Number of results to skip for pagination
Returns a list of job objects with details like:
- Job ID, name, and description
- Environment and project information
- Schedule configuration
- Execute steps (dbt commands)
- Trigger settings
Use this tool to explore available jobs, understand job configurations, or find specific jobs to trigger.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/dbt_admin/constants.py:
--------------------------------------------------------------------------------
```python
from enum import Enum
class JobRunStatus(str, Enum):
"""Enum for job run status values."""
QUEUED = "queued"
STARTING = "starting"
RUNNING = "running"
SUCCESS = "success"
ERROR = "error"
CANCELLED = "cancelled"
class RunResultsStatus(str, Enum):
"""Enum for run_results.json status values."""
SUCCESS = "success"
ERROR = "error"
FAIL = "fail"
SKIP = "skip"
STATUS_MAP = {
JobRunStatus.QUEUED: 1,
JobRunStatus.STARTING: 2,
JobRunStatus.RUNNING: 3,
JobRunStatus.SUCCESS: 10,
JobRunStatus.ERROR: 20,
JobRunStatus.CANCELLED: 30,
}
# String match in run_results_errors/parser.py to identify source freshness step
# in run_details response
SOURCE_FRESHNESS_STEP_NAME = "source freshness"
```
--------------------------------------------------------------------------------
/tests/unit/config/test_transport.py:
--------------------------------------------------------------------------------
```python
import pytest
from dbt_mcp.config.transport import validate_transport
class TestValidateTransport:
def test_valid_transports(self):
assert validate_transport("stdio") == "stdio"
assert validate_transport("sse") == "sse"
assert validate_transport("streamable-http") == "streamable-http"
def test_case_insensitive_and_whitespace(self):
assert validate_transport(" STDIO ") == "stdio"
assert validate_transport("SSE") == "sse"
def test_invalid_transport_raises_error(self):
with pytest.raises(ValueError) as exc_info:
validate_transport("invalid")
assert "Invalid MCP_TRANSPORT: 'invalid'" in str(exc_info.value)
assert "sse, stdio, streamable-http" in str(exc_info.value)
```
--------------------------------------------------------------------------------
/tests/integration/remote_tools/test_remote_tools.py:
--------------------------------------------------------------------------------
```python
from mcp.server.fastmcp import FastMCP
from dbt_mcp.config.config import load_config
from dbt_mcp.sql.tools import register_sql_tools
async def test_sql_tool_execute_sql():
config = load_config()
dbt_mcp = FastMCP("Test")
await register_sql_tools(dbt_mcp, config.sql_config)
tools = await dbt_mcp.list_tools()
print(tools)
result = await dbt_mcp.call_tool("execute_sql", {"sql": "SELECT 1"})
assert len(result) == 1
assert "1" in result[0].text
async def test_sql_tool_text_to_sql():
config = load_config()
dbt_mcp = FastMCP("Test")
await register_sql_tools(dbt_mcp, config.sql_config)
result = await dbt_mcp.call_tool("text_to_sql", {"text": "SELECT 1"})
assert len(result) == 1
assert "SELECT 1" in result[0].text
```
--------------------------------------------------------------------------------
/src/remote_mcp/session.py:
--------------------------------------------------------------------------------
```python
import contextlib
import os
from collections.abc import AsyncGenerator
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
@contextlib.asynccontextmanager
async def session_context() -> AsyncGenerator[ClientSession, None]:
async with (
streamablehttp_client(
url=f"https://{os.environ.get('DBT_HOST')}/api/ai/v1/mcp/",
headers={
"Authorization": f"token {os.environ.get('DBT_TOKEN')}",
"x-dbt-prod-environment-id": os.environ.get("DBT_PROD_ENV_ID", ""),
},
) as (
read_stream,
write_stream,
_,
),
ClientSession(read_stream, write_stream) as session,
):
await session.initialize()
yield session
```
--------------------------------------------------------------------------------
/src/dbt_mcp/oauth/token.py:
--------------------------------------------------------------------------------
```python
from typing import Any
import jwt
from jwt import PyJWKClient
from pydantic import BaseModel
class AccessTokenResponse(BaseModel):
access_token: str
refresh_token: str
expires_in: int
scope: str
token_type: str
expires_at: int
class DecodedAccessToken(BaseModel):
access_token_response: AccessTokenResponse
decoded_claims: dict[str, Any]
def fetch_jwks_and_verify_token(
access_token: str, dbt_platform_url: str
) -> dict[str, Any]:
jwks_url = f"{dbt_platform_url}/.well-known/jwks.json"
jwks_client = PyJWKClient(jwks_url)
signing_key = jwks_client.get_signing_key_from_jwt(access_token)
claims = jwt.decode(
access_token,
signing_key.key,
algorithms=["RS256"],
options={"verify_aud": False},
)
return claims
```
--------------------------------------------------------------------------------
/src/dbt_mcp/tools/register.py:
--------------------------------------------------------------------------------
```python
from collections.abc import Sequence
from mcp.server.fastmcp import FastMCP
from dbt_mcp.tools.definitions import ToolDefinition
from dbt_mcp.tools.tool_names import ToolName
def register_tools(
dbt_mcp: FastMCP,
tool_definitions: list[ToolDefinition],
exclude_tools: Sequence[ToolName] = [],
) -> None:
for tool_definition in tool_definitions:
if tool_definition.get_name().lower() in [
tool.value.lower() for tool in exclude_tools
]:
continue
dbt_mcp.tool(
name=tool_definition.get_name(),
title=tool_definition.title,
description=tool_definition.description,
annotations=tool_definition.annotations,
structured_output=tool_definition.structured_output,
)(tool_definition.fn)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/errors/__init__.py:
--------------------------------------------------------------------------------
```python
from dbt_mcp.errors.admin_api import (
AdminAPIError,
AdminAPIToolCallError,
ArtifactRetrievalError,
)
from dbt_mcp.errors.base import ToolCallError
from dbt_mcp.errors.cli import BinaryExecutionError, CLIToolCallError
from dbt_mcp.errors.common import InvalidParameterError
from dbt_mcp.errors.discovery import DiscoveryToolCallError, GraphQLError
from dbt_mcp.errors.semantic_layer import SemanticLayerToolCallError
from dbt_mcp.errors.sql import RemoteToolError, SQLToolCallError
__all__ = [
"AdminAPIError",
"AdminAPIToolCallError",
"ArtifactRetrievalError",
"BinaryExecutionError",
"CLIToolCallError",
"DiscoveryToolCallError",
"GraphQLError",
"InvalidParameterError",
"RemoteToolError",
"SQLToolCallError",
"SemanticLayerToolCallError",
"ToolCallError",
]
```
--------------------------------------------------------------------------------
/tests/unit/discovery/conftest.py:
--------------------------------------------------------------------------------
```python
from unittest.mock import Mock
import pytest
from dbt_mcp.discovery.client import MetadataAPIClient
@pytest.fixture
def mock_api_client():
"""
Shared mock MetadataAPIClient for discovery tests.
Provides a mock API client with:
- A config_provider that returns environment_id = 123
- An async get_config() method for compatibility with async tests
Used by test_sources_fetcher.py and test_exposures_fetcher.py.
"""
mock_client = Mock(spec=MetadataAPIClient)
# Add config_provider mock that returns environment_id
mock_config_provider = Mock()
mock_config = Mock()
mock_config.environment_id = 123
# Make get_config async
async def mock_get_config():
return mock_config
mock_config_provider.get_config = mock_get_config
mock_client.config_provider = mock_config_provider
return mock_client
```
--------------------------------------------------------------------------------
/ui/src/main.tsx:
--------------------------------------------------------------------------------
```typescript
import { StrictMode } from "react";
import { createRoot } from "react-dom/client";
import "./index.css";
import App from "./App.tsx";
createRoot(document.getElementById("root")!).render(
<StrictMode>
<App />
</StrictMode>
);
// Attempt to gracefully shut down the backend server when the window/tab closes
let shutdownSent = false;
const shutdownServer = () => {
if (shutdownSent) return;
shutdownSent = true;
const url = "/shutdown";
try {
if ("sendBeacon" in navigator) {
const body = new Blob([""], { type: "text/plain" });
navigator.sendBeacon(url, body);
} else {
// Best-effort fallback; keepalive helps during unload
fetch(url, { method: "POST", keepalive: true }).catch(() => {});
}
} catch {
// noop
}
};
window.addEventListener("pagehide", shutdownServer);
window.addEventListener("beforeunload", shutdownServer);
```
--------------------------------------------------------------------------------
/src/dbt_mcp/semantic_layer/gql/gql.py:
--------------------------------------------------------------------------------
```python
GRAPHQL_QUERIES = {
"metrics": """
query GetMetrics($environmentId: BigInt!, $search: String) {
metricsPaginated(
environmentId: $environmentId, search: $search
){
items{
name
label
description
type
config {
meta
}
}
}
}
""",
"dimensions": """
query GetDimensions($environmentId: BigInt!, $metrics: [MetricInput!]!, $search: String) {
dimensionsPaginated(environmentId: $environmentId, metrics: $metrics, search: $search) {
items {
description
name
type
queryableGranularities
queryableTimeGranularities
}
}
}
""",
"entities": """
query GetEntities($environmentId: BigInt!, $metrics: [MetricInput!]!, $search: String) {
entitiesPaginated(environmentId: $environmentId, metrics: $metrics, search: $search) {
items {
description
name
type
}
}
}
""",
}
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/discovery/get_model_details.md:
--------------------------------------------------------------------------------
```markdown
<instructions>
Retrieves information about a specific dbt model, including compiled SQL, description, database, schema, alias, and column details.
IMPORTANT: Use uniqueId when available.
- Using uniqueId guarantees the correct model is retrieved
- Using only model_name may return incorrect results or fail entirely
- If you obtained models via get_all_models(), you should always use the uniqueId from those results
</instructions>
<parameters>
uniqueId: The unique identifier of the model (format: "model.project_name.model_name"). STRONGLY RECOMMENDED when available.
model_name: The name of the dbt model. Only use this when uniqueId is unavailable.
</parameters>
<examples>
1. PREFERRED METHOD - Using uniqueId (always use this when available):
get_model_details(uniqueId="model.my_project.customer_orders")
2. FALLBACK METHOD - Using only model_name (only when uniqueId is unknown):
get_model_details(model_name="customer_orders")
```
--------------------------------------------------------------------------------
/.changes/v0.2.0.md:
--------------------------------------------------------------------------------
```markdown
## v0.2.0 - 2025-05-28
### Enhancement or New Feature
* Using `--quiet` flag to reduce context saturation of coding assistants
* Add a tool `get_model_children`
* Added optional uniqueId parameter to model lookup methods for more precise model identification
* Enable remote tools in production
* Add selector for dbt commands
* Set pre-changie value to 0.1.13
### Under the Hood
* Require changelog entries for each PR
* Log Python version in install script
* Update license to full Apache 2.0 text
* Roll back installation script and instructions
* Re-enable tests in CI
* Refactor config for modularity
* Document remote tools
* Usage tracking scaffolding
* Update docs to clarify service token permissions required
* Increase remote tools timeout
* Update release process for new versions
* Point to the correct diagram in README
* Install hatch in release process
* Remove hatch from release process
### Bug Fix
* Fix diagram according to feature set
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/admin_api/list_jobs_runs.md:
--------------------------------------------------------------------------------
```markdown
List all job runs in a dbt platform account with optional filtering.
This tool retrieves runs from the dbt Admin API. Runs represent executions of dbt jobs in dbt.
## Parameters
- **job_id** (optional, integer): Filter runs by specific job ID
- **status** (optional, string): Filter runs by status. One of: `queued`, `starting`, `running`, `success`, `error`, `cancelled`
- **limit** (optional, integer): Maximum number of results to return
- **offset** (optional, integer): Number of results to skip for pagination
- **order_by** (optional, string): Field to order results by (e.g., "created_at", "finished_at", "id"). Use a `-` prefix for reverse ordering (e.g., "-created_at" for newest first)
Returns a list of run objects with details like:
- Run ID and status
- Job information
- Start and end times
- Git branch and SHA
- Artifacts and logs information
Use this tool to monitor job execution, check run history, or find specific runs for debugging.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/admin_api/get_job_run_details.md:
--------------------------------------------------------------------------------
```markdown
Get detailed information for a specific dbt job run.
This tool retrieves comprehensive run information including execution details, steps, and artifacts.
## Parameters
- **run_id** (required): The run ID to retrieve details for
## Returns
Run object with detailed execution information including:
- Run metadata (ID, status, timing information)
- Job and environment details
- Git branch and SHA information
- Execution steps and their status
- Artifacts and logs availability
- Trigger information and cause
- Performance metrics and timing
## Use Cases
- Monitor run progress and status
- Debug failed runs with detailed logs
- Review run performance and timing
- Check artifact generation status
- Audit run execution details
- Troubleshoot run failures
## Example Usage
```json
{
"run_id": 789
}
```
```json
{
"run_id": 789
}
```
## Response Information
The detailed response includes timing, status, and execution context to help with monitoring and debugging dbt job runs.
```
--------------------------------------------------------------------------------
/examples/aws_strands_agent/dbt_data_scientist/prompts.py:
--------------------------------------------------------------------------------
```python
"""Defines the prompts in the dbt data scientist agent."""
ROOT_AGENT_INSTR = """You are a senior dbt engineer. You have access to several tools.
When asked to 'find a problem' or 'compile a project' on your local dbt project, call the dbt_compile tool, inspect its JSON logs,
and then:
1) Summarize the problem(s) (file, node, message).
2) Recommend a concrete fix in 1-3 bullet points (e.g., correct ref(), add column, fix Jinja).
3) If no errors, say compile is clean and suggest next step (e.g., run build state:modified+).
When asked about dbt platform or any mcp questions use the dbt_mcp_toolset to answer the question with the correct mcp function.
If the user mentions wanting to analyze their data modeling approach, call the dbt_model_analyzer_agent.
"""
REPAIR_HINTS = """If uncertain about columns/types, call inspect catalog().
If parse is clean but tests fail, try build with --select state:modified+ and --fail-fast.
Return a structured Decision: {action, reason, unified_diff?}.
"""
```
--------------------------------------------------------------------------------
/examples/remote_mcp/main.py:
--------------------------------------------------------------------------------
```python
import asyncio
import json
from mcp.types import TextContent
from remote_mcp.session import session_context
async def main():
async with session_context() as session:
available_metrics = await session.call_tool(
name="list_metrics",
arguments={},
)
metrics_content = [
t for t in available_metrics.content if isinstance(t, TextContent)
]
metrics_names = [json.loads(m.text)["name"] for m in metrics_content]
print(f"Available metrics: {', '.join(metrics_names)}\n")
num_food_orders = await session.call_tool(
name="query_metrics",
arguments={
"metrics": [
"food_orders",
],
},
)
num_food_order_content = num_food_orders.content[0]
assert isinstance(num_food_order_content, TextContent)
print(f"Number of food orders: {num_food_order_content.text}")
if __name__ == "__main__":
asyncio.run(main())
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/discovery/get_model_children.md:
--------------------------------------------------------------------------------
```markdown
<instructions>
Retrieves the child models (downstream dependencies) of a specific dbt model. These are the models that depend on the specified model.
You can provide either a model_name or a uniqueId, if known, to identify the model. Using uniqueId is more precise and guarantees a unique match, which is especially useful when models might have the same name in different projects.
</instructions>
<parameters>
model_name: The name of the dbt model to retrieve children for.
uniqueId: The unique identifier of the model. If provided, this will be used instead of model_name for a more precise lookup. You can get the uniqueId values for all models from the get_all_models() tool.
</parameters>
<examples>
1. Getting children for a model by name:
get_model_children(model_name="customer_orders")
2. Getting children for a model by uniqueId (more precise):
get_model_children(model_name="customer_orders", uniqueId="model.my_project.customer_orders")
3. Getting children using only uniqueId:
get_model_children(uniqueId="model.my_project.customer_orders")
</examples>
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/admin_api/get_job_details.md:
--------------------------------------------------------------------------------
```markdown
Get detailed information for a specific dbt job.
This tool retrieves comprehensive job configuration including execution settings, triggers, and scheduling information.
## Parameters
- **job_id** (required): The job ID to retrieve details for
## Returns
Job object with detailed configuration including:
- Job metadata (ID, name, description, type)
- Environment and project associations
- Execute steps (dbt commands to run)
- Trigger configuration (schedule, webhooks, CI)
- Execution settings (timeout, threads, target)
- dbt version overrides
- Generate docs and sources settings
- Most recent run information (if requested)
## Use Cases
- Debug job configuration issues
- Understand job execution settings
- Review scheduling and trigger configuration
- Check dbt commands and execution steps
- Audit job settings across projects
- Get recent run status for monitoring
## Job Types
- **ci**: Continuous integration jobs
- **scheduled**: Regularly scheduled jobs
- **other**: Manual or API-triggered jobs
- **merge**: Jobs triggered on merge events
## Example Usage
```json
{
"job_id": 456
}
```
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/admin_api/cancel_job_run.md:
--------------------------------------------------------------------------------
```markdown
Cancel a currently running or queued dbt run.
This tool allows you to stop a run that is currently executing or waiting in the queue.
## Parameters
- **run_id** (required): The run ID to cancel
## Returns
Updated run object showing the cancelled status and timing information.
## Run States That Can Be Cancelled
- **Queued (1)**: Run is waiting to start
- **Starting (2)**: Run is initializing
- **Running (3)**: Run is currently executing
## Use Cases
- Stop long-running jobs that are no longer needed
- Cancel jobs that were triggered by mistake
- Free up run slots for higher priority jobs
- Stop runs that are stuck or hanging
- Emergency cancellation during incidents
## Important Notes
- Once cancelled, a run cannot be resumed
- Partial work may have been completed before cancellation
- Artifacts from cancelled runs may not be available
- Use the retry functionality if you need to re-run after cancellation
## Example Usage
```json
{
"run_id": 789
}
```
## Response
Returns the updated run object with:
- Status changed to cancelled (30)
- Cancellation timestamp
- Final execution timing
- Any artifacts that were generated before cancellation
```
--------------------------------------------------------------------------------
/examples/openai_responses/main.py:
--------------------------------------------------------------------------------
```python
# mypy: ignore-errors
import os
from openai import OpenAI
def main():
client = OpenAI()
prod_environment_id = os.environ.get("DBT_PROD_ENV_ID", os.getenv("DBT_ENV_ID"))
token = os.environ.get("DBT_TOKEN")
host = os.environ.get("DBT_HOST", "cloud.getdbt.com")
messages = []
while True:
user_message = input("User > ")
messages.append({"role": "user", "content": user_message})
response = client.responses.create(
model="gpt-4o-mini",
tools=[
{
"type": "mcp",
"server_label": "dbt",
"server_url": f"https://{host}/api/ai/v1/mcp/",
"require_approval": "never",
"headers": {
"Authorization": f"token {token}",
"x-dbt-prod-environment-id": prod_environment_id,
},
}, # type: ignore
],
input=messages,
)
messages.append({"role": "assistant", "content": response.output_text})
print(f"Assistant > {response.output_text}")
if __name__ == "__main__":
main()
```
--------------------------------------------------------------------------------
/src/dbt_mcp/semantic_layer/types.py:
--------------------------------------------------------------------------------
```python
from dataclasses import dataclass
from dbtsl.models.dimension import DimensionType
from dbtsl.models.entity import EntityType
from dbtsl.models.metric import MetricType
@dataclass
class OrderByParam:
name: str
descending: bool
@dataclass
class MetricToolResponse:
name: str
type: MetricType
label: str | None = None
description: str | None = None
metadata: str | None = None
@dataclass
class DimensionToolResponse:
name: str
type: DimensionType
description: str | None = None
label: str | None = None
granularities: list[str] | None = None
@dataclass
class EntityToolResponse:
name: str
type: EntityType
description: str | None = None
@dataclass
class QueryMetricsSuccess:
result: str
error: None = None
@dataclass
class QueryMetricsError:
error: str
result: None = None
QueryMetricsResult = QueryMetricsSuccess | QueryMetricsError
@dataclass
class GetMetricsCompiledSqlSuccess:
sql: str
error: None = None
@dataclass
class GetMetricsCompiledSqlError:
error: str
sql: None = None
GetMetricsCompiledSqlResult = GetMetricsCompiledSqlSuccess | GetMetricsCompiledSqlError
```
--------------------------------------------------------------------------------
/src/dbt_mcp/telemetry/logging.py:
--------------------------------------------------------------------------------
```python
from __future__ import annotations
import logging
from pathlib import Path
LOG_FILENAME = "dbt-mcp.log"
def _find_repo_root() -> Path:
module_path = Path(__file__).resolve().parent
home = Path.home().resolve()
for candidate in [module_path, *module_path.parents]:
if (
(candidate / ".git").exists()
or (candidate / "pyproject.toml").exists()
or candidate == home
):
return candidate
return module_path
def configure_logging(file_logging: bool) -> None:
if not file_logging:
return
repo_root = _find_repo_root()
log_path = repo_root / LOG_FILENAME
root_logger = logging.getLogger()
for handler in root_logger.handlers:
if (
isinstance(handler, logging.FileHandler)
and Path(handler.baseFilename) == log_path
):
return
file_handler = logging.FileHandler(log_path, encoding="utf-8")
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(
logging.Formatter("%(asctime)s %(levelname)s [%(name)s] %(message)s")
)
root_logger.setLevel(logging.INFO)
root_logger.addHandler(file_handler)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/discovery/get_exposure_details.md:
--------------------------------------------------------------------------------
```markdown
Get detailed information about one or more exposures by name or unique IDs.
Parameters:
- unique_ids (optional): List of unique IDs of exposures (e.g., ["exposure.project.exposure1", "exposure.project.exposure2"]) (more efficient - uses GraphQL filter)
Returns a list of detailed information dictionaries, each including:
- name: The name of the exposure
- description: Detailed description of the exposure
- exposureType: Type of exposure (application, dashboard, analysis, etc.)
- maturity: Maturity level of the exposure (high, medium, low)
- ownerName: Name of the exposure owner
- ownerEmail: Email of the exposure owner
- url: URL associated with the exposure
- label: Optional label for the exposure
- parents: List of parent models/sources that this exposure depends on
- meta: Additional metadata associated with the exposure
- freshnessStatus: Current freshness status of the exposure
- uniqueId: The unique identifier for this exposure
Example usage:
- Get single exposure by unique ID: get_exposure_details(unique_ids=["exposure.analytics.customer_dashboard"])
- Get multiple exposures by unique IDs: get_exposure_details(unique_ids=["exposure.analytics.dashboard1", "exposure.sales.report2"])
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/discovery/get_all_sources.md:
--------------------------------------------------------------------------------
```markdown
Get the name, description, and metadata of all dbt sources in the environment. Sources represent external data tables that your dbt models build upon.
Parameters (all optional):
- source_names: List of specific source names to filter by (e.g., ['raw_data', 'external_api'])
- unique_ids: List of specific source table IDs to filter by
Note:
- source_names correspond to the top-level source grouping in the source YML config
- unique_ids have the form `source.{YOUR-DBT-PROJECT}.{SOURCE-NAME}.{SOURCE-TABLE}`
Returns information including:
- name: The table name within the source
- uniqueId: The unique identifier for this source table
- identifier: The underlying table identifier in the warehouse
- description: Description of the source table
- sourceName: The source name (e.g., 'raw_data', 'external_api')
- database: Database containing the source table
- schema: Schema containing the source table
- resourceType: Will be 'source'
- freshness: Real-time freshness status from production including:
- maxLoadedAt: When the source was last loaded
- maxLoadedAtTimeAgoInS: How long ago the source was loaded (in seconds)
- freshnessStatus: Current freshness status (e.g., 'pass', 'warn', 'error')
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/discovery/get_model_parents.md:
--------------------------------------------------------------------------------
```markdown
<instructions>
Retrieves the parent models of a specific dbt model. These are the models that the specified model depends on.
You can provide either a model_name or a uniqueId, if known, to identify the model. Using uniqueId is more precise and guarantees a unique match, which is especially useful when models might have the same name in different projects.
Returned parents include `resourceType`, `name`, and `description`. For upstream sources, also provide `sourceName` and `uniqueId` so lineage can be linked back via `get_all_sources`.
</instructions>
<parameters>
model_name: The name of the dbt model to retrieve parents for.
uniqueId: The unique identifier of the model. If provided, this will be used instead of model_name for a more precise lookup. You can get the uniqueId values for all models from the get_all_models() tool.
</parameters>
<examples>
1. Getting parents for a model by name:
get_model_parents(model_name="customer_orders")
2. Getting parents for a model by uniqueId (more precise):
get_model_parents(model_name="customer_orders", uniqueId="model.my_project.customer_orders")
3. Getting parents using only uniqueId:
get_model_parents(uniqueId="model.my_project.customer_orders")
</examples>
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/admin_api/list_job_run_artifacts.md:
--------------------------------------------------------------------------------
```markdown
List all available artifacts for a completed dbt job run.
This tool retrieves the list of artifact files generated during a run execution, such as manifest.json, catalog.json, and run_results.json.
## Parameters
- **run_id** (required): The run ID to list artifacts for
## Returns
List of artifact file paths available for download. Common artifacts include:
- **manifest.json**: Complete project metadata and lineage
- **catalog.json**: Documentation and column information
- **run_results.json**: Execution results and timing
- **sources.json**: Source freshness check results
- **compiled/**: Compiled SQL files
- **run/**: SQL statements executed during the run
## Artifact Availability
Artifacts are only available for:
- Successfully completed runs
- Failed runs that progressed beyond compilation
- Runs where `artifacts_saved` is true
## Use Cases
- Discover available artifacts before downloading
- Check if specific artifacts were generated
- Audit artifact generation across runs
- Integrate with external systems that consume dbt artifacts
- Validate run completion and output generation
## Example Usage
```json
{
"run_id": 789
}
```
## Next Steps
Use `get_run_artifact` to download specific artifacts from this list for analysis or integration with other tools.
```
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/feature_request.yml:
--------------------------------------------------------------------------------
```yaml
name: Feature Request
description: Suggest an idea for this project
title: "[Feature]: "
labels: ["enhancement"]
body:
- type: markdown
attributes:
value: |
Thanks for taking the time to suggest a new feature!
- type: textarea
id: problem
attributes:
label: Is your feature request related to a problem?
description: A clear and concise description of what the problem is.
placeholder: I am having trouble...
validations:
required: false
- type: textarea
id: solution
attributes:
label: Describe the solution you'd like
description: A clear and concise description of what you want to happen.
placeholder: I would like to see...
validations:
required: true
- type: textarea
id: alternatives
attributes:
label: Describe alternatives you've considered
description: A clear and concise description of any alternative solutions or features you've considered.
placeholder: Alternative approaches could be...
validations:
required: false
- type: textarea
id: additional-context
attributes:
label: Additional context
description: Add any other context, screenshots, or examples about the feature request here.
validations:
required: false
```
--------------------------------------------------------------------------------
/tests/env_vars.py:
--------------------------------------------------------------------------------
```python
import os
from contextlib import contextmanager
@contextmanager
def env_vars_context(env_vars: dict[str, str]):
"""Temporarily set environment variables and restore them afterward."""
# Store original env vars
original_env = {}
# Save original and set new values
for key, value in env_vars.items():
if key in os.environ:
original_env[key] = os.environ[key]
os.environ[key] = value
try:
yield
finally:
# Restore original values
for key in env_vars:
if key in original_env:
os.environ[key] = original_env[key]
else:
del os.environ[key]
@contextmanager
def default_env_vars_context(override_env_vars: dict[str, str] | None = None):
with env_vars_context(
{
"DBT_HOST": "http://localhost:8000",
"DBT_PROD_ENV_ID": "1234",
"DBT_TOKEN": "5678",
"DBT_PROJECT_DIR": "tests/fixtures/dbt_project",
"DBT_PATH": "dbt",
"DBT_DEV_ENV_ID": "5678",
"DBT_USER_ID": "9012",
"DBT_CLI_TIMEOUT": "10",
"DBT_ACCOUNT_ID": "12345",
"DISABLE_TOOLS": "",
"DISABLE_DBT_CODEGEN": "false",
}
| (override_env_vars or {})
):
yield
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/semantic_layer/get_dimensions.md:
--------------------------------------------------------------------------------
```markdown
<instructions>
Get the dimensions for specified metrics
Dimensions are the attributes, features, or characteristics
that describe or categorize data.
</instructions>
<examples>
<example>
Question: "I want to analyze revenue trends - what dimensions are available?"
Thinking step-by-step:
- Using list_metrics(), I find "revenue" is available
- Now I can get the dimensions for this metric
- The search parameter is not needed here since the user is interested in all available dimensions.
Parameters:
metrics=["revenue"]
search=null
</example>
<example>
Question: "Are there any time-related dimensions for my sales metrics?"
Thinking step-by-step:
- Using list_metrics(), I find "total_sales" and "average_order_value" are available
- The user is interested in time dimensions specifically
- I should use the search parameter to filter for dimensions with "time" in the name
- This will narrow down the results to just time-related dimensions
Parameters:
metrics=["total_sales", "average_order_value"]
search="time"
</example>
</examples>
<parameters>
metrics: List of metric names
search: Optional string used to filter dimensions by name using partial matches (only use when absolutely necessary as some dimensions might be missed due to specific naming styles)
</parameters>
```
--------------------------------------------------------------------------------
/src/dbt_mcp/config/headers.py:
--------------------------------------------------------------------------------
```python
from abc import ABC, abstractmethod
from typing import Protocol
from dbt_mcp.oauth.token_provider import TokenProvider
class HeadersProvider(Protocol):
def get_headers(self) -> dict[str, str]: ...
class TokenHeadersProvider(ABC):
def __init__(self, token_provider: TokenProvider):
self.token_provider = token_provider
@abstractmethod
def headers_from_token(self, token: str) -> dict[str, str]: ...
def get_headers(self) -> dict[str, str]:
return self.headers_from_token(self.token_provider.get_token())
class AdminApiHeadersProvider(TokenHeadersProvider):
def headers_from_token(self, token: str) -> dict[str, str]:
return {"Authorization": f"Bearer {token}"}
class DiscoveryHeadersProvider(TokenHeadersProvider):
def headers_from_token(self, token: str) -> dict[str, str]:
return {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json",
}
class SemanticLayerHeadersProvider(TokenHeadersProvider):
def headers_from_token(self, token: str) -> dict[str, str]:
return {
"Authorization": f"Bearer {token}",
"x-dbt-partner-source": "dbt-mcp",
}
class SqlHeadersProvider(TokenHeadersProvider):
def headers_from_token(self, token: str) -> dict[str, str]:
return {"Authorization": f"Bearer {token}"}
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/semantic_layer/get_entities.md:
--------------------------------------------------------------------------------
```markdown
<instructions>
Get the entities for specified metrics
Entities are real-world concepts in a business such as customers,
transactions, and ad campaigns. Analysis is often focused around
specific entities, such as customer churn or
annual recurring revenue modeling.
</instructions>
<examples>
<example>
Question: "I want to analyze revenue - what entities are available?"
Thinking step-by-step:
- Using list_metrics(), I find "revenue" is available
- Now I can get the entities for this metric
- The search parameter is not needed here since the user is interested in all available entities.
Parameters:
metrics=["revenue"]
search=null
</example>
<example>
Question: "Are there any customer-related entities for my sales metrics?"
Thinking step-by-step:
- Using list_metrics(), I find "total_sales" and "average_order_value" are available
- The user is interested in customer entities specifically
- I should use the search parameter to filter for entities with "customer" in the name
- This will narrow down the results to just customer-related entities
Parameters:
metrics=["total_sales", "average_order_value"]
search="customer"
</example>
</examples>
<parameters>
metrics: List of metric names
search: Optional string used to filter entities by name using partial matches (only use when absolutely necessary as some entities might be missed due to specific naming styles)
</parameters>
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/admin_api/retry_job_run.md:
--------------------------------------------------------------------------------
```markdown
Retry a failed dbt job run from the point of failure.
This tool allows you to restart a failed run, continuing from where it failed rather than starting completely over.
## Parameters
- **run_id** (required): The run ID to retry
## Returns
New run object for the retry attempt with a new run ID and execution details.
## Requirements for Retry
- Original run must have failed (status 20)
- Run must be the most recent run for the job
- dbt version must support retry functionality
- Run must have generated run_results.json
## Retry Behavior
- Continues from the failed step
- Skips successfully completed models
- Uses the same configuration as the original run
- Creates a new run with a new run ID
- Maintains the same Git SHA and branch
## Use Cases
- Recover from transient infrastructure failures
- Continue after warehouse connectivity issues
- Resume after temporary resource constraints
- Avoid re-running expensive successful steps
- Quick recovery from known, fixable issues
## Retry Not Supported Reasons
If retry fails, possible reasons include:
- **RETRY_UNSUPPORTED_CMD**: Command type doesn't support retry
- **RETRY_UNSUPPORTED_VERSION**: dbt version too old
- **RETRY_NOT_LATEST_RUN**: Not the most recent run for the job
- **RETRY_NOT_FAILED_RUN**: Run didn't fail
- **RETRY_NO_RUN_RESULTS**: Missing run results for retry logic
## Example Usage
```json
{
"run_id": 789
}
```
This creates a new run that continues from the failure point of run 789.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/dbt_cli/args/selectors.md:
--------------------------------------------------------------------------------
```markdown
A selector needs be used when we need to select specific nodes or are asking to do actions on specific nodes. A node can be a model, a test, a seed or a snapshot. It is strongly preferred to provide a selector, especially on large projects. Always provide a selector initially.
- to select all models, just do not provide a selector
- to select a particular model, use the selector `<model_name>`
## Graph operators
- to select a particular model and all the downstream ones (also known as children), use the selector `<model_name>+`
- to select a particular model and all the upstream ones (also known as parents), use the selector `+<model_name>`
- to select a particular model and all the downstream and upstream ones, use the selector `+<model_name>+`
- to select the union of different selectors, separate them with a space like `selector1 selector2`
- to select the intersection of different selectors, separate them with a comma like `selector1,selector2`
## Matching nodes based on parts of their name
When looking to select nodes based on parts of their names, the selector needs to be `fqn:<pattern>`. The fqn is the fully qualified name, it starts with the project or package name followed by the subfolder names and finally the node name.
### Examples
- to select a node from any package that contains `stg_`, we would have the selector `fqn:*stg_*`
- to select a node from the current project that contains `stg_`, we would have the selector `fqn:project_name.*stg_*`
```
--------------------------------------------------------------------------------
/examples/aws_strands_agent/dbt_data_scientist/quick_mcp_test.py:
--------------------------------------------------------------------------------
```python
#!/usr/bin/env python3
"""Quick MCP connection test - minimal version."""
import os
import sys
from dotenv import load_dotenv
def quick_test():
"""Quick test of MCP connectivity."""
print("🧪 Quick MCP Connection Test")
print("-" * 30)
# Load environment
load_dotenv()
# Check basic env vars
url = os.environ.get("DBT_MCP_URL")
token = os.environ.get("DBT_TOKEN")
if not url or not token:
print("❌ Missing DBT_MCP_URL or DBT_TOKEN")
return False
print(f"✅ URL: {url}")
print(f"✅ Token: {'*' * len(token)}")
try:
# Import and test
from tools.dbt_mcp import dbt_mcp_client
print("🔌 Testing connection...")
with dbt_mcp_client:
tools = dbt_mcp_client.list_tools_sync()
print(f"✅ Connected! Found {len(tools)} tools")
if tools:
print("📋 Available tools:")
for tool in tools[:5]: # Show first 3 tools
print(f" - {tool.tool_name}")
if len(tools) > 3:
print(f" ... and {len(tools) - 3} more")
return True
except Exception as e:
print(f"❌ Connection failed: {e}")
return False
if __name__ == "__main__":
success = quick_test()
if success:
print("\n🎉 MCP connection is working!")
else:
print("\n💥 MCP connection failed!")
sys.exit(0 if success else 1)
```
--------------------------------------------------------------------------------
/.github/workflows/changelog-check.yml:
--------------------------------------------------------------------------------
```yaml
name: Check CHANGELOG
on:
pull_request:
branches:
- main
jobs:
check-changelog:
permissions:
contents: read
pull-requests: write
runs-on: ubuntu-latest
if: "!startsWith(github.event.head_commit.message, 'Release: v')"
steps:
- name: checkout code
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
with:
fetch-depth: 0
- name: setup python
uses: ./.github/actions/setup-python
id: setup-python
- name: Check for changes
run: |
BASE=$(git merge-base HEAD origin/main)
ALL_CHANGES=$(git diff --name-only "$BASE"...HEAD)
# only ignore docs/ and .md files in root
IGNORE_REGEX='(^docs/|^[^/]+\.md$)'
NON_IGNORED_CHANGES=$(echo "$ALL_CHANGES" | grep -Ev "$IGNORE_REGEX" || true)
if [ "$NON_IGNORED_CHANGES" == "" ]; then
echo "No relevant changes detected. Skipping changelog check."
exit 0
fi
CHANGIE=$(echo "$ALL_CHANGES" | grep -E "\.changes/unreleased/.*\.yaml" || true)
if [ "$CHANGIE" == "" ]; then
echo "No files added to '.changes/unreleased/'. Make sure you run 'changie new'."
exit 1
fi
CHANGELOG=$(echo "$ALL_CHANGES" | grep -E "CHANGELOG\.md" || true)
if [ "$CHANGELOG" != "" ]; then
echo "Don't edit 'CHANGELOG.md' manually nor run 'changie merge'."
exit 1
fi
```
--------------------------------------------------------------------------------
/.github/workflows/run-checks-pr.yaml:
--------------------------------------------------------------------------------
```yaml
name: PR pipeline
on:
pull_request:
types: [opened, reopened, synchronize, labeled]
jobs:
# checks the code for styling and type errors
check:
name: Check styling
runs-on: ubuntu-24.04
permissions:
contents: read
pull-requests: write
steps:
- name: checkout code
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
- name: setup python
uses: ./.github/actions/setup-python
id: setup-python
- uses: pnpm/action-setup@a7487c7e89a18df4991f7f222e4898a00d66ddda
with:
version: 10
- name: Install go-task
run: sh -c "$(curl --location https://taskfile.dev/install.sh)" -- -d -b /usr/local/bin
- name: Install dependencies
run: task install
- name: Run check
run: task check
# runs the unit tests
unit-test:
name: Unit test
runs-on: ubuntu-24.04
permissions:
contents: read
pull-requests: write
needs:
- check
steps:
- name: checkout code
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
- name: setup python
uses: ./.github/actions/setup-python
id: setup-python
- uses: pnpm/action-setup@a7487c7e89a18df4991f7f222e4898a00d66ddda
with:
version: 10
- name: Install go-task
run: sh -c "$(curl --location https://taskfile.dev/install.sh)" -- -d -b /usr/local/bin
- name: Run tests
run: task test:unit
```
--------------------------------------------------------------------------------
/src/dbt_mcp/tools/annotations.py:
--------------------------------------------------------------------------------
```python
from mcp.types import ToolAnnotations
def create_tool_annotations(
title: str | None = None,
read_only_hint: bool = False,
destructive_hint: bool = True,
idempotent_hint: bool = False,
open_world_hint: bool = True,
) -> ToolAnnotations:
"""
Creates tool annotations. Defaults to the most cautious option,
i.e destructive, non-idempotent, and open-world.
Args:
- title: Human-readable title for the tool
- read_only_hint: If true, the tool does not modify its environment.
- destructive_hint:
If true, the tool may perform destructive updates to its environment.
If false, the tool performs only additive updates.
This property is meaningful only when `readOnlyHint == false`.
- idempotent_hint: Whether repeated calls have the same effect
If true, calling the tool repeatedly with the same arguments will have no additional effect on the its environment.
This property is meaningful only when `readOnlyHint == false`.
- open_world_hint: Whether the tool interacts with external systems
If true, this tool may interact with an "open world" of external entities.
If false, the tool's domain of interaction is closed.
For example, the world of a web search tool is open, whereas that of a memory tool is not.
"""
return ToolAnnotations(
title=title,
readOnlyHint=read_only_hint,
destructiveHint=destructive_hint,
idempotentHint=idempotent_hint,
openWorldHint=open_world_hint,
)
```
--------------------------------------------------------------------------------
/examples/openai_agent/main.py:
--------------------------------------------------------------------------------
```python
# mypy: ignore-errors
import asyncio
from pathlib import Path
from agents import Agent, Runner, trace
from agents.mcp import create_static_tool_filter
from agents.mcp.server import MCPServerStdio
async def main():
dbt_mcp_dir = Path(__file__).parent.parent.parent
async with MCPServerStdio(
name="dbt",
params={
"command": "uvx",
"args": [
"--env-file",
# This file should contain config described in the root README.md
f"{dbt_mcp_dir}/.env",
"dbt-mcp",
],
},
client_session_timeout_seconds=20,
cache_tools_list=True,
tool_filter=create_static_tool_filter(
allowed_tool_names=[
"list_metrics",
"get_dimensions",
"get_entities",
"query_metrics",
],
),
) as server:
agent = Agent(
name="Assistant",
instructions="Use the tools to answer the user's questions",
mcp_servers=[server],
)
with trace(workflow_name="Conversation"):
conversation = []
result = None
while True:
if result:
conversation = result.to_input_list()
conversation.append({"role": "user", "content": input("User > ")})
result = await Runner.run(agent, conversation)
print(result.final_output)
if __name__ == "__main__":
try:
asyncio.run(main())
except KeyboardInterrupt:
print("\nExiting.")
```
--------------------------------------------------------------------------------
/tests/unit/tools/test_disable_tools.py:
--------------------------------------------------------------------------------
```python
from unittest.mock import patch
from dbt_mcp.config.config import load_config
from dbt_mcp.dbt_cli.binary_type import BinaryType
from dbt_mcp.mcp.server import create_dbt_mcp
from tests.env_vars import default_env_vars_context
async def test_disable_tools():
"""Test that the ToolName enum matches the tools registered in the server."""
disable_tools = {"get_mart_models", "list_metrics"}
with (
default_env_vars_context(
override_env_vars={"DISABLE_TOOLS": ",".join(disable_tools)}
),
patch(
"dbt_mcp.config.config.detect_binary_type", return_value=BinaryType.DBT_CORE
),
):
config = load_config()
dbt_mcp = await create_dbt_mcp(config)
# Get all tools from the server
server_tools = await dbt_mcp.list_tools()
server_tool_names = {tool.name for tool in server_tools}
assert not disable_tools.intersection(server_tool_names)
async def test_disable_cli_tools():
disable_tools = {"build", "compile", "docs", "list"}
with (
default_env_vars_context(
override_env_vars={"DISABLE_TOOLS": ",".join(disable_tools)}
),
patch(
"dbt_mcp.config.config.detect_binary_type", return_value=BinaryType.DBT_CORE
),
):
config = load_config()
dbt_mcp = await create_dbt_mcp(config)
# Get all tools from the server
server_tools = await dbt_mcp.list_tools()
server_tool_names = {tool.name for tool in server_tools}
assert not disable_tools.intersection(server_tool_names)
assert "show" in server_tool_names
```
--------------------------------------------------------------------------------
/tests/unit/tools/test_toolsets.py:
--------------------------------------------------------------------------------
```python
from unittest.mock import patch
from dbt_mcp.config.config import load_config
from dbt_mcp.dbt_cli.binary_type import BinaryType
from dbt_mcp.lsp.lsp_binary_manager import LspBinaryInfo
from dbt_mcp.mcp.server import create_dbt_mcp
from dbt_mcp.tools.toolsets import proxied_tools, toolsets
from tests.env_vars import default_env_vars_context
async def test_toolsets_match_server_tools():
"""Test that the defined toolsets match the tools registered in the server."""
with (
default_env_vars_context(),
patch(
"dbt_mcp.config.config.detect_binary_type", return_value=BinaryType.DBT_CORE
),
patch(
"dbt_mcp.lsp.tools.dbt_lsp_binary_info",
return_value=LspBinaryInfo(path="/path/to/lsp", version="1.0.0"),
),
):
config = load_config()
dbt_mcp = await create_dbt_mcp(config)
# Get all tools from the server
server_tools = await dbt_mcp.list_tools()
# Manually adding SQL tools here because the server doesn't get them
# in this unit test.
server_tool_names = {tool.name for tool in server_tools} | {
p.value for p in proxied_tools
}
defined_tools = set()
for toolset_tools in toolsets.values():
defined_tools.update({t.value for t in toolset_tools})
if server_tool_names != defined_tools:
raise ValueError(
f"Tool name mismatch:\n"
f"In server but not in enum: {server_tool_names - defined_tools}\n"
f"In enum but not in server: {defined_tools - server_tool_names}"
)
```
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/bug_report.yml:
--------------------------------------------------------------------------------
```yaml
name: Bug Report
description: File a bug report to help us improve
title: "[Bug]: "
labels: ["bug"]
body:
- type: markdown
attributes:
value: |
Thanks for taking the time to fill out this bug report!
- type: textarea
id: what-happened
attributes:
label: What happened?
description: Also tell us, what did you expect to happen?
placeholder: Tell us what you see!
value: "A bug happened!"
validations:
required: true
- type: textarea
id: reproduce
attributes:
label: Steps to Reproduce
description: Please provide detailed steps to reproduce the issue
placeholder: |
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
validations:
required: true
- type: dropdown
id: deployment
attributes:
label: Deployment
description: Are you using the local MCP server or the remote MCP server?
options:
- Local MCP server
- Remote MCP server
validations:
required: true
- type: textarea
id: environment
attributes:
label: Environment
description: Please provide details about your environment
placeholder: |
- OS: [e.g. macOS, Linux, Windows]
- dbt CLI executable (for CLI tools): [e.g. dbt Core, Fusion, Cloud CLI]
- MCP client: [e.g. Cursor, Claude Desktop, OpenAI SDK...]
validations:
required: false
- type: textarea
id: logs
attributes:
label: Relevant log output
description: Please copy and paste any relevant log output. This will be automatically formatted into code, so no need for backticks.
render: shell
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/admin_api/trigger_job_run.md:
--------------------------------------------------------------------------------
```markdown
# Trigger Job Run
Trigger a dbt job run with optional parameter overrides.
This tool starts a new run for a specified job with the ability to override default settings like Git branch, schema, or other execution parameters.
## Parameters
- **job_id** (required): The job ID to trigger
- **cause** (required): Description of why the job is being triggered
- **git_branch** (optional): Override the Git branch to checkout
- **git_sha** (optional): Override the Git SHA to checkout
- **schema_override** (optional): Override the destination schema
## Additional Override Options
The API supports additional overrides (can be added to the implementation):
- **dbt_version_override**: Override the dbt version
- **threads_override**: Override the number of threads
- **target_name_override**: Override the target name
- **generate_docs_override**: Override docs generation setting
- **timeout_seconds_override**: Override the timeout
- **steps_override**: Override the dbt commands to execute
## Returns
Run object with information about the newly triggered run including:
- Run ID and status
- Job and environment information
- Git branch and SHA being used
- Trigger information and cause
- Execution queue position
## Use Cases
- Trigger ad-hoc job runs for testing
- Run jobs with different Git branches for feature testing
- Execute jobs with schema overrides for development
- Trigger jobs via API automation or external systems
- Run jobs with custom parameters for specific scenarios
## Example Usage
```json
{
"job_id": 456,
"cause": "Manual trigger for testing"
}
```
```json
{
"job_id": 456,
"cause": "Testing feature branch",
"git_branch": "feature/new-models",
"schema_override": "dev_testing"
}
```
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/admin_api/get_job_run_artifact.md:
--------------------------------------------------------------------------------
```markdown
Download a specific artifact file from a dbt job run.
This tool retrieves the content of a specific artifact file generated during run execution, such as manifest.json, catalog.json, or compiled SQL files.
## Parameters
- **run_id** (required): The run ID containing the artifact
- **artifact_path** (required): The path to the specific artifact file
- **step** (optional): The step index to retrieve artifacts from (default: last step)
## Common Artifact Paths
- **manifest.json**: Complete dbt project metadata, models, and lineage
- **catalog.json**: Table and column documentation with statistics
- **run_results.json**: Execution results, timing, and status information
- **sources.json**: Source freshness check results
- **compiled/[model_path].sql**: Individual compiled SQL files
- **logs/dbt.log**: Complete execution logs
## Returns
The artifact content in its original format:
- JSON files return parsed JSON objects
- SQL files return text content
- Log files return text content
## Use Cases
- Download manifest.json for lineage analysis
- Get catalog.json for documentation systems
- Retrieve run_results.json for execution monitoring
- Access compiled SQL for debugging
- Download logs for troubleshooting failures
- Integration with external tools and systems
## Step Selection
- By default, artifacts from the last step are returned
- Use the `step` parameter to get artifacts from earlier steps
- Step indexing starts at 1 for the first step
## Example Usage
```json
{
"run_id": 789,
"artifact_path": "manifest.json"
}
```
```json
{
"run_id": 789,
"artifact_path": "compiled/analytics/models/staging/stg_users.sql"
}
```
```json
{
"run_id": 789,
"artifact_path": "run_results.json",
"step": 2
}
```
```
--------------------------------------------------------------------------------
/src/dbt_mcp/dbt_admin/run_results_errors/config.py:
--------------------------------------------------------------------------------
```python
from typing import Any
from pydantic import BaseModel
class RunStepSchema(BaseModel):
"""Schema for individual "run_step" key from get_job_run_details()."""
name: str
status: int # 20 = error
index: int
finished_at: str | None = None
logs: str | None = None
class Config:
extra = "allow"
class RunDetailsSchema(BaseModel):
"""Schema for get_job_run_details() response."""
is_cancelled: bool
run_steps: list[RunStepSchema]
finished_at: str | None = None
class Config:
extra = "allow"
class RunResultSchema(BaseModel):
"""Schema for individual result in "results" key of run_results.json."""
unique_id: str
status: str # "success", "error", "fail", "skip"
message: str | None = None
relation_name: str | None = None
compiled_code: str | None = None
class Config:
extra = "allow"
class RunResultsArgsSchema(BaseModel):
"""Schema for "args" key in run_results.json."""
target: str | None = None
class Config:
extra = "allow"
class RunResultsArtifactSchema(BaseModel):
"""Schema for get_job_run_artifact() response (run_results.json)."""
results: list[RunResultSchema]
args: RunResultsArgsSchema | None = None
metadata: dict[str, Any] | None = None
class Config:
extra = "allow"
class ErrorResultSchema(BaseModel):
"""Schema for individual error result."""
unique_id: str | None = None
relation_name: str | None = None
message: str
compiled_code: str | None = None
truncated_logs: str | None = None
class ErrorStepSchema(BaseModel):
"""Schema for a single failed step with its errors."""
target: str | None = None
step_name: str | None = None
finished_at: str | None = None
errors: list[ErrorResultSchema]
```
--------------------------------------------------------------------------------
/src/dbt_mcp/semantic_layer/levenshtein.py:
--------------------------------------------------------------------------------
```python
from dataclasses import dataclass
@dataclass
class Misspelling:
word: str
similar_words: list[str]
def levenshtein(s1: str, s2: str) -> int:
len_s1, len_s2 = len(s1), len(s2)
dp = [[0] * (len_s2 + 1) for _ in range(len_s1 + 1)]
for i in range(len_s1 + 1):
dp[i][0] = i
for j in range(len_s2 + 1):
dp[0][j] = j
for i in range(1, len_s1 + 1):
for j in range(1, len_s2 + 1):
cost = 0 if s1[i - 1] == s2[j - 1] else 1
dp[i][j] = min(
dp[i - 1][j] + 1, # Deletion
dp[i][j - 1] + 1, # Insertion
dp[i - 1][j - 1] + cost, # Substitution
)
return dp[len_s1][len_s2]
def get_closest_words(
target: str,
words: list[str],
top_k: int | None = None,
threshold: int | None = None,
) -> list[str]:
distances = [(word, levenshtein(target, word)) for word in words]
# Filter by threshold if provided
if threshold is not None:
distances = [(word, dist) for word, dist in distances if dist <= threshold]
# Sort by distance
distances.sort(key=lambda x: x[1])
# Limit by top_k if provided
if top_k is not None:
distances = distances[:top_k]
return [word for word, _ in distances]
def get_misspellings(
targets: list[str],
words: list[str],
top_k: int | None = None,
) -> list[Misspelling]:
misspellings = []
for target in targets:
if target not in words:
misspellings.append(
Misspelling(
word=target,
similar_words=get_closest_words(
target=target,
words=words,
top_k=top_k,
threshold=max(1, len(target) // 2),
),
)
)
return misspellings
```
--------------------------------------------------------------------------------
/src/dbt_mcp/dbt_cli/binary_type.py:
--------------------------------------------------------------------------------
```python
import subprocess
from enum import Enum
from dbt_mcp.errors import BinaryExecutionError
class BinaryType(Enum):
DBT_CORE = "dbt_core"
FUSION = "fusion"
DBT_CLOUD_CLI = "dbt_cloud_cli"
def detect_binary_type(file_path: str) -> BinaryType:
"""
Detect the type of dbt binary (dbt Core, Fusion, or dbt Cloud CLI) by running --help.
Args:
file_path: Path to the dbt executable
Returns:
BinaryType: The detected binary type
Raises:
Exception: If the binary cannot be executed or accessed
"""
try:
result = subprocess.run(
[file_path, "--help"],
check=False,
capture_output=True,
text=True,
timeout=10,
)
help_output = result.stdout
except Exception as e:
raise BinaryExecutionError(f"Cannot execute binary {file_path}: {e}")
if not help_output:
# Default to dbt Core if no output
return BinaryType.DBT_CORE
first_line = help_output.split("\n")[0] if help_output else ""
# Check for dbt-fusion
if "dbt-fusion" in first_line:
return BinaryType.FUSION
# Check for dbt Core
if "Usage: dbt [OPTIONS] COMMAND [ARGS]..." in first_line:
return BinaryType.DBT_CORE
# Check for dbt Cloud CLI
if "The dbt Cloud CLI" in first_line:
return BinaryType.DBT_CLOUD_CLI
# Default to dbt Core - We could move to Fusion in the future
return BinaryType.DBT_CORE
def get_color_disable_flag(binary_type: BinaryType) -> str:
"""
Get the appropriate color disable flag for the given binary type.
Args:
binary_type: The type of dbt binary
Returns:
str: The color disable flag to use
"""
if binary_type == BinaryType.DBT_CLOUD_CLI:
return "--no-color"
else: # DBT_CORE or FUSION
return "--no-use-colors"
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/discovery/get_model_health.md:
--------------------------------------------------------------------------------
```markdown
<instructions>
Retrieves information about the health of a dbt model, including the last time it ran, the last test execution status, and whether the upstream data for the model is fresh.
IMPORTANT: Use uniqueId when available.
- Using uniqueId guarantees the correct model is retrieved
- Using only model_name may return incorrect results or fail entirely
- If you obtained models via get_all_models(), you should always use the uniqueId from those results
ASSESSING MODEL HEALTH:
For all of the below, summarize whether the model is healthy, questionable, or unhealthy. Only provide more details when asked.
- for the model executionInfo, if the lastRunStatus is "success" consider the model healthy
- for the test executionInfo, if the lastRunStatus is "success" consider the model healthy
- for the models parents:
-- check the modelexecutionInfo, snapshotExecutionInfo, and seedExecutionInfo. If the lastRunStatus is "success" consider the model healthy. If the lastRunStatus is "error" consider the model unhealthy.
-- if the parent node is a SourceAppliedStateNestedNode:
--- If the freshnessStatus is "pass", consider the model healthy
--- If the freshnessStatus is "fail", consider the model unhealthy
--- If the freshnessStatus is null, consider the model health questionable
--- If the freshnessStatus is "warn", consider the model health questionable
</instructions>
<parameters>
uniqueId: The unique identifier of the model (format: "model.project_name.model_name"). STRONGLY RECOMMENDED when available.
model_name: The name of the dbt model. Only use this when uniqueId is unavailable.
</parameters>
<examples>
1. PREFERRED METHOD - Using uniqueId (always use this when available):
get_model_details(uniqueId="model.my_project.customer_orders")
2. FALLBACK METHOD - Using only model_name (only when uniqueId is unknown):
get_model_details(model_name="customer_orders")
</examples>
```
--------------------------------------------------------------------------------
/src/dbt_mcp/tools/toolsets.py:
--------------------------------------------------------------------------------
```python
from enum import Enum
from typing import Literal
from dbt_mcp.tools.tool_names import ToolName
class Toolset(Enum):
SQL = "sql"
SEMANTIC_LAYER = "semantic_layer"
DISCOVERY = "discovery"
DBT_CLI = "dbt_cli"
ADMIN_API = "admin_api"
DBT_CODEGEN = "dbt_codegen"
DBT_LSP = "dbt_lsp"
proxied_tools: set[Literal[ToolName.TEXT_TO_SQL, ToolName.EXECUTE_SQL]] = set(
[
ToolName.TEXT_TO_SQL,
ToolName.EXECUTE_SQL,
]
)
toolsets = {
Toolset.SQL: {
ToolName.TEXT_TO_SQL,
ToolName.EXECUTE_SQL,
},
Toolset.SEMANTIC_LAYER: {
ToolName.LIST_METRICS,
ToolName.GET_DIMENSIONS,
ToolName.GET_ENTITIES,
ToolName.QUERY_METRICS,
ToolName.GET_METRICS_COMPILED_SQL,
},
Toolset.DISCOVERY: {
ToolName.GET_MART_MODELS,
ToolName.GET_ALL_MODELS,
ToolName.GET_MODEL_DETAILS,
ToolName.GET_MODEL_PARENTS,
ToolName.GET_MODEL_CHILDREN,
ToolName.GET_MODEL_HEALTH,
ToolName.GET_ALL_SOURCES,
ToolName.GET_EXPOSURES,
ToolName.GET_EXPOSURE_DETAILS,
},
Toolset.DBT_CLI: {
ToolName.BUILD,
ToolName.COMPILE,
ToolName.DOCS,
ToolName.LIST,
ToolName.PARSE,
ToolName.RUN,
ToolName.TEST,
ToolName.SHOW,
},
Toolset.ADMIN_API: {
ToolName.LIST_JOBS,
ToolName.GET_JOB_DETAILS,
ToolName.TRIGGER_JOB_RUN,
ToolName.LIST_JOBS_RUNS,
ToolName.GET_JOB_RUN_DETAILS,
ToolName.CANCEL_JOB_RUN,
ToolName.RETRY_JOB_RUN,
ToolName.LIST_JOB_RUN_ARTIFACTS,
ToolName.GET_JOB_RUN_ARTIFACT,
ToolName.GET_JOB_RUN_ERROR,
},
Toolset.DBT_CODEGEN: {
ToolName.GENERATE_SOURCE,
ToolName.GENERATE_MODEL_YAML,
ToolName.GENERATE_STAGING_MODEL,
},
Toolset.DBT_LSP: {
ToolName.GET_COLUMN_LINEAGE,
},
}
```
--------------------------------------------------------------------------------
/examples/aws_strands_agent/requirements.txt:
--------------------------------------------------------------------------------
```
aiohappyeyeballs==2.6.1
aiohttp==3.12.15
aiosignal==1.4.0
annotated-types==0.7.0
anyio==4.10.0
attrs==25.3.0
autopep8==2.3.2
aws-requests-auth==0.4.3
beautifulsoup4==4.13.5
bedrock-agentcore==0.1.4
bedrock-agentcore-starter-toolkit==0.1.12
boto3==1.40.34
botocore==1.40.34
certifi==2025.8.3
chardet==5.2.0
charset-normalizer==3.4.3
click==8.3.0
dill==0.4.0
docstring_parser==0.17.0
dotenv==0.9.9
frozenlist==1.7.0
h11==0.16.0
html5lib==1.1
httpcore==1.0.9
httpx==0.28.1
httpx-sse==0.4.1
idna==3.10
importlib_metadata==8.7.0
Jinja2==3.1.6
jmespath==1.0.1
jsonschema==4.25.1
jsonschema-path==0.3.4
jsonschema-specifications==2025.9.1
lazy-object-proxy==1.12.0
lxml==6.0.2
markdown-it-py==4.0.0
markdownify==1.2.0
MarkupSafe==3.0.2
mcp==1.14.1
mdurl==0.1.2
mpmath==1.3.0
multidict==6.6.4
openapi-schema-validator==0.6.3
openapi-spec-validator==0.7.2
opentelemetry-api==1.37.0
opentelemetry-instrumentation==0.58b0
opentelemetry-instrumentation-threading==0.58b0
opentelemetry-sdk==1.37.0
opentelemetry-semantic-conventions==0.58b0
packaging==25.0
pathable==0.4.4
pillow==11.3.0
prance==25.4.8.0
prompt_toolkit==3.0.52
propcache==0.3.2
py-openapi-schema-to-json-schema==0.0.3
pycodestyle==2.14.0
pydantic==2.11.9
pydantic-settings==2.10.1
pydantic_core==2.33.2
Pygments==2.19.2
PyJWT==2.10.1
python-dateutil==2.9.0.post0
python-dotenv==1.1.1
python-multipart==0.0.20
PyYAML==6.0.2
questionary==2.1.1
readabilipy==0.3.0
referencing==0.36.2
regex==2025.9.18
requests==2.32.5
rfc3339-validator==0.1.4
rich==14.1.0
rpds-py==0.27.1
ruamel.yaml==0.18.15
ruamel.yaml.clib==0.2.12
s3transfer==0.14.0
shellingham==1.5.4
six==1.17.0
slack_bolt==1.25.0
slack_sdk==3.36.0
sniffio==1.3.1
soupsieve==2.8
sse-starlette==3.0.2
starlette==0.49.1
strands-agents==1.9.0
strands-agents-tools==0.2.8
sympy==1.14.0
tenacity==9.1.2
toml==0.10.2
typer==0.17.4
typing-inspection==0.4.1
typing_extensions==4.15.0
urllib3==2.5.0
uvicorn==0.35.0
watchdog==6.0.0
wcwidth==0.2.13
webencodings==0.5.1
wrapt==1.17.3
yarl==1.20.1
zipp==3.23.0
```
--------------------------------------------------------------------------------
/examples/langgraph_agent/main.py:
--------------------------------------------------------------------------------
```python
# mypy: ignore-errors
import asyncio
import os
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.prebuilt import create_react_agent
def print_stream_item(item):
if "agent" in item:
content = [
part
for message in item["agent"]["messages"]
for part in (
message.content
if isinstance(message.content, list)
else [message.content]
)
]
for c in content:
if isinstance(c, str):
print(f"Agent > {c}")
elif "text" in c:
print(f"Agent > {c['text']}")
elif c["type"] == "tool_use":
print(f" using tool: {c['name']}")
async def main():
url = f"https://{os.environ.get('DBT_HOST')}/api/ai/v1/mcp/"
headers = {
"x-dbt-user-id": os.environ.get("DBT_USER_ID"),
"x-dbt-prod-environment-id": os.environ.get("DBT_PROD_ENV_ID"),
"x-dbt-dev-environment-id": os.environ.get("DBT_DEV_ENV_ID"),
"Authorization": f"token {os.environ.get('DBT_TOKEN')}",
}
client = MultiServerMCPClient(
{
"dbt": {
"url": url,
"headers": headers,
"transport": "streamable_http",
}
}
)
tools = await client.get_tools()
agent = create_react_agent(
model="anthropic:claude-3-7-sonnet-latest",
tools=tools,
# This allows the agent to have conversational memory.
checkpointer=InMemorySaver(),
)
# This config maintains the conversation thread.
config = {"configurable": {"thread_id": "1"}}
while True:
user_input = input("User > ")
async for item in agent.astream(
{"messages": {"role": "user", "content": user_input}},
config,
):
print_stream_item(item)
if __name__ == "__main__":
asyncio.run(main())
```
--------------------------------------------------------------------------------
/src/dbt_mcp/tools/tool_names.py:
--------------------------------------------------------------------------------
```python
from enum import Enum
class ToolName(Enum):
"""Tool names available in the FastMCP server.
This enum provides type safety and autocompletion for tool names.
The validate_server_tools() function should be used to ensure
this enum stays in sync with the actual server tools.
"""
# dbt CLI tools
BUILD = "build"
COMPILE = "compile"
DOCS = "docs"
LIST = "list"
PARSE = "parse"
RUN = "run"
TEST = "test"
SHOW = "show"
# Semantic Layer tools
LIST_METRICS = "list_metrics"
GET_DIMENSIONS = "get_dimensions"
GET_ENTITIES = "get_entities"
QUERY_METRICS = "query_metrics"
GET_METRICS_COMPILED_SQL = "get_metrics_compiled_sql"
# Discovery tools
GET_MART_MODELS = "get_mart_models"
GET_ALL_MODELS = "get_all_models"
GET_MODEL_DETAILS = "get_model_details"
GET_MODEL_PARENTS = "get_model_parents"
GET_MODEL_CHILDREN = "get_model_children"
GET_MODEL_HEALTH = "get_model_health"
GET_ALL_SOURCES = "get_all_sources"
GET_EXPOSURES = "get_exposures"
GET_EXPOSURE_DETAILS = "get_exposure_details"
# SQL tools
TEXT_TO_SQL = "text_to_sql"
EXECUTE_SQL = "execute_sql"
# Admin API tools
LIST_JOBS = "list_jobs"
GET_JOB_DETAILS = "get_job_details"
TRIGGER_JOB_RUN = "trigger_job_run"
LIST_JOBS_RUNS = "list_jobs_runs"
GET_JOB_RUN_DETAILS = "get_job_run_details"
CANCEL_JOB_RUN = "cancel_job_run"
RETRY_JOB_RUN = "retry_job_run"
LIST_JOB_RUN_ARTIFACTS = "list_job_run_artifacts"
GET_JOB_RUN_ARTIFACT = "get_job_run_artifact"
GET_JOB_RUN_ERROR = "get_job_run_error"
# dbt-codegen tools
GENERATE_SOURCE = "generate_source"
GENERATE_MODEL_YAML = "generate_model_yaml"
GENERATE_STAGING_MODEL = "generate_staging_model"
# dbt LSP tools
GET_COLUMN_LINEAGE = "get_column_lineage"
@classmethod
def get_all_tool_names(cls) -> set[str]:
"""Returns a set of all tool names as strings."""
return {member.value for member in cls}
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/semantic_layer/get_metrics_compiled_sql.md:
--------------------------------------------------------------------------------
```markdown
<instructions>
Gets compiled SQL for given metrics and dimensions/entities from the dbt Semantic Layer.
This tool generates the underlying SQL that would be executed for a given metric query by the `query_metrics` tool,
without actually running the query. This is useful for understanding what SQL is being
generated, debugging query issues, or getting SQL to run elsewhere.
To use this tool, you must first know about specific metrics, dimensions and
entities to provide. You can call the list_metrics, get_dimensions,
and get_entities tools to get information about which metrics, dimensions,
and entities to use.
When using the `group_by` parameter, ensure that the dimensions and entities
you specify are valid for the given metrics. Time dimensions can include
grain specifications (e.g., MONTH, DAY, YEAR).
The tool will return the compiled SQL that the dbt Semantic Layer would generate
to calculate the specified metrics with the given groupings.
Don't call this tool if the user's question cannot be answered with the provided
metrics, dimensions, and entities. Instead, clarify what metrics, dimensions,
and entities are available and suggest a new question that can be answered
and is approximately the same as the user's question.
This tool is particularly useful when:
- Users want to see the underlying SQL for a metric calculation
- Debugging complex metric definitions
- Understanding how grouping affects the generated SQL
- Getting SQL to run in other tools or systems
</instructions>
Returns the compiled SQL as a string, or an error message if the compilation fails.
<parameters>
metrics: List of metric names (strings) to query for.
group_by: Optional list of objects with name (string), type ("dimension" or "time_dimension"), and grain (string or null for time dimensions only).
order_by: Optional list of objects with name (string) and descending (boolean, default false).
where: Optional SQL WHERE clause (string) to filter results.
limit: Optional limit (integer) for number of results.
</parameters>
```
--------------------------------------------------------------------------------
/tests/unit/tools/test_tool_names.py:
--------------------------------------------------------------------------------
```python
from unittest.mock import patch
import pytest
from dbt_mcp.config.config import load_config
from dbt_mcp.dbt_cli.binary_type import BinaryType
from dbt_mcp.lsp.lsp_binary_manager import LspBinaryInfo
from dbt_mcp.mcp.server import create_dbt_mcp
from dbt_mcp.tools.tool_names import ToolName
from dbt_mcp.tools.toolsets import proxied_tools
from tests.env_vars import default_env_vars_context
@pytest.mark.asyncio
async def test_tool_names_match_server_tools():
"""Test that the ToolName enum matches the tools registered in the server."""
with (
default_env_vars_context(),
patch(
"dbt_mcp.config.config.detect_binary_type", return_value=BinaryType.DBT_CORE
),
patch(
"dbt_mcp.lsp.tools.dbt_lsp_binary_info",
return_value=LspBinaryInfo(path="/path/to/lsp", version="1.0.0"),
),
):
config = load_config()
dbt_mcp = await create_dbt_mcp(config)
# Get all tools from the server
server_tools = await dbt_mcp.list_tools()
# Manually adding SQL tools here because the server doesn't get them
# in this unit test.
server_tool_names = {tool.name for tool in server_tools} | {
p.value for p in proxied_tools
}
enum_names = {n for n in ToolName.get_all_tool_names()}
# This should not raise any errors if the enum is in sync
if server_tool_names != enum_names:
raise ValueError(
f"Tool name mismatch:\n"
f"In server but not in enum: {server_tool_names - enum_names}\n"
f"In enum but not in server: {enum_names - server_tool_names}"
)
# Double check that all enum values are strings
for tool in ToolName:
assert isinstance(tool.value, str), (
f"Tool {tool.name} value should be a string"
)
def test_tool_names_no_duplicates():
"""Test that there are no duplicate tool names in the enum."""
assert len(ToolName.get_all_tool_names()) == len(set(ToolName.get_all_tool_names()))
```
--------------------------------------------------------------------------------
/examples/aws_strands_agent/dbt_data_scientist/agent.py:
--------------------------------------------------------------------------------
```python
"""Main application entry point for dbt AWS agentcore multi-agent."""
from dotenv import load_dotenv
from bedrock_agentcore import BedrockAgentCoreApp
from strands import Agent
import prompts
from tools import (
dbt_compile,
dbt_mcp_tool,
dbt_model_analyzer_agent
)
# Load environment variables
load_dotenv()
# Initialize the Bedrock Agent Core App
app = BedrockAgentCoreApp()
# Initialize the main agent
dbt_agent = Agent(
system_prompt=prompts.ROOT_AGENT_INSTR,
callback_handler=None,
tools=[dbt_compile, dbt_mcp_tool, dbt_model_analyzer_agent]
)
@app.entrypoint
def invoke(payload):
"""Main AI agent function with access to dbt tools."""
user_message = payload.get("prompt", "Hello! How can I help you today?")
try:
# Process the user message with the dbt agent
result = dbt_agent(user_message)
# Extract the response content
response_content = str(result)
return {"result": response_content}
except Exception as e:
return {"result": f"Error processing your request: {str(e)}"}
# Example usage for local testing
if __name__ == "__main__":
print("\ndbt's Assistant Strands Agent\n")
print("Ask a question about our dbt mcp server, our local fusion compiler, or our data model analyzer and I'll route it to the appropriate specialist.")
print("Type 'exit' to quit.")
# Interactive loop for local testing
while True:
try:
user_input = input("\n> ")
if user_input.lower() == "exit":
print("\nGoodbye! 👋")
break
response = dbt_agent(user_input)
# Extract and print only the relevant content from the specialized agent's response
content = str(response)
print(content)
except KeyboardInterrupt:
print("\n\nExecution interrupted. Exiting...")
break
except Exception as e:
print(f"\nAn error occurred: {str(e)}")
print("Please try asking a different question.")
```
--------------------------------------------------------------------------------
/tests/unit/tools/test_tool_policies.py:
--------------------------------------------------------------------------------
```python
from unittest.mock import patch
from dbt_mcp.config.config import load_config
from dbt_mcp.dbt_cli.binary_type import BinaryType
from dbt_mcp.lsp.lsp_binary_manager import LspBinaryInfo
from dbt_mcp.mcp.server import create_dbt_mcp
from dbt_mcp.tools.policy import tool_policies
from dbt_mcp.tools.tool_names import ToolName
from dbt_mcp.tools.toolsets import proxied_tools
from tests.env_vars import default_env_vars_context
async def test_tool_policies_match_server_tools():
"""Test that the ToolPolicy enum matches the tools registered in the server."""
with (
default_env_vars_context(),
patch(
"dbt_mcp.config.config.detect_binary_type", return_value=BinaryType.DBT_CORE
),
patch(
"dbt_mcp.lsp.tools.dbt_lsp_binary_info",
return_value=LspBinaryInfo(path="/path/to/lsp", version="1.0.0"),
),
):
config = load_config()
dbt_mcp = await create_dbt_mcp(config)
# Get all tools from the server
server_tools = await dbt_mcp.list_tools()
# Manually adding SQL tools here because the server doesn't get them
# in this unit test.
server_tool_names = {tool.name for tool in server_tools} | {
p.value for p in proxied_tools
}
policy_names = {policy_name for policy_name in tool_policies}
if server_tool_names != policy_names:
raise ValueError(
f"Tool name mismatch:\n"
f"In server but not in enum: {server_tool_names - policy_names}\n"
f"In enum but not in server: {policy_names - server_tool_names}"
)
def test_tool_policies_match_tool_names():
policy_names = {policy.upper() for policy in tool_policies}
tool_names = {tool.name for tool in ToolName}
if tool_names != policy_names:
raise ValueError(
f"Tool name mismatch:\n"
f"In tool names but not in policy: {tool_names - policy_names}\n"
f"In policy but not in tool names: {policy_names - tool_names}"
)
def test_tool_policies_no_duplicates():
"""Test that there are no duplicate tool names in the policy."""
assert len(tool_policies) == len(set(tool_policies.keys()))
```
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
```toml
[project]
name = "dbt-mcp"
description = "A MCP (Model Context Protocol) server for interacting with dbt resources."
authors = [{ name = "dbt Labs" }]
readme = "README.md"
license = { file = "LICENSE" }
# until pyarrow releases wheels for 3.14 https://github.com/apache/arrow/issues/47438
requires-python = ">=3.12,<3.14"
dynamic = ["version"]
keywords = [
"dbt",
"mcp",
"model-context-protocol",
"data",
"analytics",
"ai-agent",
"llm",
]
classifiers = [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Information Technology",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Information Analysis",
"Typing :: Typed",
]
dependencies = [
# Pinning all dependencies because this app is installed with uvx
# and we want to have a consistent install as much as possible.
"authlib==1.6.5",
"dbt-protos==1.0.382",
"dbt-sl-sdk[sync]==0.13.0",
"dbtlabs-vortex==0.2.0",
"fastapi==0.116.1",
"uvicorn==0.30.6",
"mcp[cli]==1.10.1",
"pandas==2.2.3",
"pydantic-settings==2.10.1",
"pyjwt==2.10.1",
"pyyaml==6.0.2",
"requests==2.32.4",
"filelock>=3.18.0",
]
[dependency-groups]
dev = [
"ruff>=0.11.2",
"types-requests>=2.32.0.20250328",
"mypy>=1.12.1",
"pre-commit>=4.2.0",
"pytest-asyncio>=0.26.0",
"pytest>=8.3.5",
"openai>=1.71.0",
"pyarrow-stubs>=19.1",
"types-pyyaml>=6.0.12.20250516",
"types-authlib>=1.6.4.20250920",
]
[project.urls]
Documentation = "https://docs.getdbt.com/docs/dbt-ai/about-mcp"
Issues = "https://github.com/dbt-labs/dbt-mcp/issues"
Source = "https://github.com/dbt-labs/dbt-mcp"
Changelog = "https://github.com/dbt-labs/dbt-mcp/blob/main/CHANGELOG.md"
[project.scripts]
dbt-mcp = "dbt_mcp.main:main"
[build-system]
requires = ["hatchling", "hatch-vcs"]
build-backend = "hatchling.build"
[tool.hatch.build.targets.sdist]
include = ["src/dbt_mcp/**/*", "README.md", "LICENSE"]
[tool.hatch.version]
source = "vcs"
[tool.pytest.ini_options]
asyncio_mode = "auto"
asyncio_default_fixture_loop_scope = "function"
pythonpath = [".", "src"]
[tool.ruff.lint]
extend-select = ["UP"] # UP=pyupgrade
```
--------------------------------------------------------------------------------
/src/dbt_mcp/prompts/admin_api/get_job_run_error.md:
--------------------------------------------------------------------------------
```markdown
Get focused error information for a failed dbt job run.
This tool retrieves and analyzes job run failures to provide concise, actionable error details optimized for troubleshooting. Instead of verbose run details, it returns structured error information with minimal token usage.
## Parameters
- run_id (required): The run ID to analyze for error information
## Returns
Structured error information with `failed_steps` containing a list of failed step details:
- failed_steps: List of failed steps, each containing:
- target: The dbt target environment where the failure occurred
- step_name: The failed step that caused the run to fail
- finished_at: Timestamp when the failed step completed
- errors: List of specific error details, each with:
- unique_id: Model/test unique identifier (nullable)
- relation_name: Database relation name or "No database relation"
- message: Error message
- compiled_code: Raw compiled SQL code (nullable)
- truncated_logs: Raw truncated debug log output (nullable)
NOTE: The "truncated_logs" key only populates if there is no `run_results.json` artifact to parse after a job run error.
## Error Types Handled
- Model execution
- Data and unit tests
- Source freshness
- Snapshot
- Data constraints / contracts
- Cancelled runs (with and without executed steps)
## Use Cases
- Quick failure diagnosis
- LLM-optimized troubleshooting
- Automated monitoring
- Failure pattern analysis
- Rapid incident response
## Advantages over get_job_run_details
- Reduced token usage by filreting for relevant error information
- Returns errors in a structured format
- Handles source freshness errors in addition to model/test errors
## Example Usage
```json
{
"run_id": 789
}
```
## Example Response
```json
{
"failed_steps": [
{
"target": "prod",
"step_name": "Invoke dbt with `dbt run --models staging`",
"finished_at": "2025-09-17 14:32:15.123456+00:00",
"errors": [
{
"unique_id": "model.analytics.stg_users",
"relation_name": "analytics_staging.stg_users",
"message": "Syntax error: Expected end of input but got keyword SELECT at line 15",
"compiled_code": "SELECT\n id,\n name\nFROM raw_users\nSELECT -- duplicate SELECT causes error",
"truncated_logs": null
}
]
}
]
}
```
## Response Information
The focused response provides only the essential error context needed for quick diagnosis and resolution of dbt job failures.
```
--------------------------------------------------------------------------------
/src/dbt_mcp/oauth/context_manager.py:
--------------------------------------------------------------------------------
```python
import logging
from pathlib import Path
import yaml
from dbt_mcp.oauth.dbt_platform import DbtPlatformContext
logger = logging.getLogger(__name__)
class DbtPlatformContextManager:
"""
Manages dbt platform context files and context creation.
"""
def __init__(self, config_location: Path):
self.config_location = config_location
def read_context(self) -> DbtPlatformContext | None:
"""Read the current context from file with proper locking."""
if not self.config_location.exists():
return None
try:
content = self.config_location.read_text()
if not content.strip():
return None
parsed_content = yaml.safe_load(content)
if parsed_content is None or not isinstance(parsed_content, dict):
logger.warning("dbt Platform Context YAML file is invalid")
return None
return DbtPlatformContext(**parsed_content)
except yaml.YAMLError as e:
logger.error(f"Failed to parse YAML from {self.config_location}: {e}")
except Exception as e:
logger.error(f"Failed to read context from {self.config_location}: {e}")
return None
def update_context(
self, new_dbt_platform_context: DbtPlatformContext
) -> DbtPlatformContext:
"""
Update the existing context by merging with new context data.
Reads existing context, merges with new data, and writes back to file.
"""
existing_dbt_platform_context = self.read_context()
if existing_dbt_platform_context is None:
existing_dbt_platform_context = DbtPlatformContext()
next_dbt_platform_context = existing_dbt_platform_context.override(
new_dbt_platform_context
)
self.write_context_to_file(next_dbt_platform_context)
return next_dbt_platform_context
def _ensure_config_location_exists(self) -> None:
"""Ensure the config file location and its parent directories exist."""
self.config_location.parent.mkdir(parents=True, exist_ok=True)
if not self.config_location.exists():
self.config_location.touch()
def write_context_to_file(self, context: DbtPlatformContext) -> None:
"""Write context to file with proper locking."""
self._ensure_config_location_exists()
self.config_location.write_text(
yaml.dump(context.model_dump(), default_flow_style=False)
)
```
--------------------------------------------------------------------------------
/src/dbt_mcp/oauth/dbt_platform.py:
--------------------------------------------------------------------------------
```python
from __future__ import annotations
from typing import Any
from pydantic import BaseModel
from dbt_mcp.oauth.token import (
AccessTokenResponse,
DecodedAccessToken,
fetch_jwks_and_verify_token,
)
class DbtPlatformAccount(BaseModel):
id: int
name: str
locked: bool
state: int
static_subdomain: str | None
vanity_subdomain: str | None
@property
def host_prefix(self) -> str | None:
if self.static_subdomain:
return self.static_subdomain
if self.vanity_subdomain:
return self.vanity_subdomain
return None
class DbtPlatformProject(BaseModel):
id: int
name: str
account_id: int
account_name: str
class DbtPlatformEnvironmentResponse(BaseModel):
id: int
name: str
deployment_type: str | None
class DbtPlatformEnvironment(BaseModel):
id: int
name: str
deployment_type: str
class SelectedProjectRequest(BaseModel):
account_id: int
project_id: int
def dbt_platform_context_from_token_response(
token_response: dict[str, Any], dbt_platform_url: str
) -> DbtPlatformContext:
new_access_token_response = AccessTokenResponse(**token_response)
decoded_claims = fetch_jwks_and_verify_token(
new_access_token_response.access_token, dbt_platform_url
)
decoded_access_token = DecodedAccessToken(
access_token_response=new_access_token_response,
decoded_claims=decoded_claims,
)
return DbtPlatformContext(
decoded_access_token=decoded_access_token,
)
class DbtPlatformContext(BaseModel):
decoded_access_token: DecodedAccessToken | None = None
host_prefix: str | None = None
dev_environment: DbtPlatformEnvironment | None = None
prod_environment: DbtPlatformEnvironment | None = None
account_id: int | None = None
@property
def user_id(self) -> int | None:
return (
int(self.decoded_access_token.decoded_claims["sub"])
if self.decoded_access_token
else None
)
def override(self, other: DbtPlatformContext) -> DbtPlatformContext:
return DbtPlatformContext(
dev_environment=other.dev_environment or self.dev_environment,
prod_environment=other.prod_environment or self.prod_environment,
decoded_access_token=other.decoded_access_token
or self.decoded_access_token,
host_prefix=other.host_prefix or self.host_prefix,
account_id=other.account_id or self.account_id,
)
```
--------------------------------------------------------------------------------
/examples/google_adk_agent/main.py:
--------------------------------------------------------------------------------
```python
import asyncio
import os
from pathlib import Path
from google.adk.agents import LlmAgent
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
from google.adk.tools.mcp_tool.mcp_toolset import McpToolset
from google.adk.tools.mcp_tool.mcp_session_manager import (
StdioConnectionParams,
StdioServerParameters,
)
from google.genai import types
async def main():
if not os.environ.get("GOOGLE_GENAI_API_KEY"):
print("Missing GOOGLE_GENAI_API_KEY environment variable.")
print("Get your API key from: https://aistudio.google.com/apikey")
return
dbt_mcp_dir = Path(__file__).parent.parent.parent
toolset = McpToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command="uvx",
args=["--env-file", f"{dbt_mcp_dir}/.env", "dbt-mcp"],
env=os.environ.copy(),
)
)
)
agent = LlmAgent(
name="dbt_assistant",
model=os.environ.get("ADK_MODEL", "gemini-2.0-flash"),
instruction="You are a helpful dbt assistant with access to dbt tools via MCP Tools.",
tools=[toolset],
)
runner = Runner(
agent=agent,
app_name="dbt_adk_agent",
session_service=InMemorySessionService(),
)
await runner.session_service.create_session(
app_name="dbt_adk_agent", user_id="user", session_id="session_1"
)
print("Google ADK + dbt MCP Agent ready! Type 'quit' to exit.\n")
while True:
try:
user_input = input("User > ").strip()
if user_input.lower() in {"quit", "exit", "q"}:
print("Goodbye!")
break
if not user_input:
continue
events = runner.run(
user_id="user",
session_id="session_1",
new_message=types.Content(
role="user", parts=[types.Part(text=user_input)]
),
)
for event in events:
if hasattr(event, "content") and hasattr(event.content, "parts"):
for part in event.content.parts:
if hasattr(part, "text") and part.text:
print(f"Assistant: {part.text}")
except (EOFError, KeyboardInterrupt):
print("\nGoodbye!")
break
except Exception as e:
print(f"Error: {e}")
if __name__ == "__main__":
try:
asyncio.run(main())
except KeyboardInterrupt:
print("\nExiting.")
```
--------------------------------------------------------------------------------
/examples/pydantic_ai_agent/main.py:
--------------------------------------------------------------------------------
```python
import asyncio
import os
from pydantic_ai import Agent, RunContext # type: ignore
from pydantic_ai.mcp import MCPServerStreamableHTTP # type: ignore
from pydantic_ai.messages import ( # type: ignore
FunctionToolCallEvent,
)
async def main():
"""Start a conversation using PydanticAI with an HTTP MCP server."""
prod_environment_id = os.environ.get("DBT_PROD_ENV_ID", os.getenv("DBT_ENV_ID"))
token = os.environ.get("DBT_TOKEN")
host = os.environ.get("DBT_HOST", "cloud.getdbt.com")
# Configure MCP server connection
mcp_server_url = f"https://{host}/api/ai/v1/mcp/"
mcp_server_headers = {
"Authorization": f"token {token}",
"x-dbt-prod-environment-id": prod_environment_id,
}
server = MCPServerStreamableHTTP(url=mcp_server_url, headers=mcp_server_headers)
# Initialize the agent with OpenAI model and MCP tools
# PydanticAI also supports Anthropic models, Google models, and more
agent = Agent(
"openai:gpt-5",
toolsets=[server],
system_prompt="You are a helpful AI assistant with access to MCP tools.",
)
print("Starting conversation with PydanticAI + MCP server...")
print("Type 'quit' to exit\n")
async with agent:
while True:
try:
user_input = input("You: ").strip()
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
if not user_input:
continue
# Event handler for real-time tool call detection
async def event_handler(ctx: RunContext, event_stream):
async for event in event_stream:
if isinstance(event, FunctionToolCallEvent):
print(f"\n🔧 Tool called: {event.part.tool_name}")
print(f" Arguments: {event.part.args}")
print("Assistant: ", end="", flush=True)
# Stream the response with real-time events
print("Assistant: ", end="", flush=True)
async with agent.run_stream(
user_input, event_stream_handler=event_handler
) as result:
async for text in result.stream_text(delta=True):
print(text, end="", flush=True)
print() # New line after response
except KeyboardInterrupt:
print("\nGoodbye!")
break
except Exception as e:
print(f"Error: {e}")
if __name__ == "__main__":
asyncio.run(main())
```
--------------------------------------------------------------------------------
/tests/unit/lsp/test_lsp_client.py:
--------------------------------------------------------------------------------
```python
"""Tests for the DbtLspClient class."""
from unittest.mock import MagicMock
import pytest
from dbt_mcp.lsp.lsp_client import LSPClient
from dbt_mcp.lsp.lsp_connection import LSPConnection, LspConnectionState
@pytest.fixture
def mock_lsp_connection() -> LSPConnection:
"""Create a mock LSP connection manager."""
connection = MagicMock(spec=LSPConnection)
connection.state = LspConnectionState(initialized=True, compiled=True)
return connection
@pytest.fixture
def lsp_client(mock_lsp_connection: LSPConnection):
"""Create an LSP client with a mock connection manager."""
return LSPClient(mock_lsp_connection)
@pytest.mark.asyncio
async def test_get_column_lineage_success(lsp_client, mock_lsp_connection):
"""Test successful column lineage request."""
# Setup mock
mock_result = {
"nodes": [
{"model": "upstream_model", "column": "id"},
{"model": "current_model", "column": "customer_id"},
]
}
mock_lsp_connection.send_request.return_value = mock_result
# Execute
result = await lsp_client.get_column_lineage(
model_id="model.my_project.my_model",
column_name="customer_id",
)
# Verify
assert result == mock_result
mock_lsp_connection.send_request.assert_called_once_with(
"workspace/executeCommand",
{
"command": "dbt.listNodes",
"arguments": ["+column:model.my_project.my_model.CUSTOMER_ID+"],
},
)
@pytest.mark.asyncio
async def test_list_nodes_success(lsp_client, mock_lsp_connection):
"""Test successful list nodes request."""
# Setup mock
mock_result = {
"nodes": ["model.my_project.upstream1", "model.my_project.upstream2"],
}
mock_lsp_connection.send_request.return_value = mock_result
# Execute
result = await lsp_client._list_nodes(
model_selector="+model.my_project.my_model+",
)
# Verify
assert result == mock_result
mock_lsp_connection.send_request.assert_called_once_with(
"workspace/executeCommand",
{"command": "dbt.listNodes", "arguments": ["+model.my_project.my_model+"]},
)
@pytest.mark.asyncio
async def test_get_column_lineage_error(lsp_client, mock_lsp_connection):
"""Test column lineage request with LSP error."""
# Setup mock to raise an error
mock_lsp_connection.send_request.return_value = {"error": "LSP server error"}
# Execute and verify exception is raised
result = await lsp_client.get_column_lineage(
model_id="model.my_project.my_model",
column_name="customer_id",
)
assert result == {"error": "LSP server error"}
```
--------------------------------------------------------------------------------
/src/dbt_mcp/oauth/login.py:
--------------------------------------------------------------------------------
```python
import errno
import logging
import secrets
import webbrowser
from importlib import resources
from authlib.integrations.requests_client import OAuth2Session
from uvicorn import Config, Server
from dbt_mcp.oauth.client_id import OAUTH_CLIENT_ID
from dbt_mcp.oauth.context_manager import DbtPlatformContextManager
from dbt_mcp.oauth.dbt_platform import DbtPlatformContext
from dbt_mcp.oauth.fastapi_app import create_app
from dbt_mcp.oauth.logging import disable_server_logs
logger = logging.getLogger(__name__)
async def login(
*,
dbt_platform_url: str,
port: int,
dbt_platform_context_manager: DbtPlatformContextManager,
) -> DbtPlatformContext:
"""Start OAuth login flow with PKCE using authlib and return
the decoded access token
"""
# 'offline_access' scope indicates that we want to request a refresh token
# 'user_access' is equivalent to a PAT
scope = "user_access offline_access"
# Create OAuth2Session with PKCE support
client = OAuth2Session(
client_id=OAUTH_CLIENT_ID,
redirect_uri=f"http://localhost:{port}",
scope=scope,
code_challenge_method="S256",
)
# Generate code_verifier
code_verifier = secrets.token_urlsafe(32)
# Generate authorization URL with PKCE
authorization_url, state = client.create_authorization_url(
url=f"{dbt_platform_url}/oauth/authorize",
code_verifier=code_verifier,
)
try:
# Resolve static assets directory from package
package_root = resources.files("dbt_mcp")
packaged_dist = package_root / "ui" / "dist"
if not packaged_dist.is_dir():
raise FileNotFoundError(f"{packaged_dist} not found in packaged resources")
static_dir = str(packaged_dist)
# Create FastAPI app and Uvicorn server
app = create_app(
oauth_client=client,
state_to_verifier={state: code_verifier},
dbt_platform_url=dbt_platform_url,
static_dir=static_dir,
dbt_platform_context_manager=dbt_platform_context_manager,
)
config = Config(
app=app,
host="127.0.0.1",
port=port,
)
server = Server(config)
app.state.server_ref = server
logger.info("Opening authorization URL")
webbrowser.open(authorization_url)
# Logs have to be disabled because they mess up stdio MCP communication
disable_server_logs()
await server.serve()
if not app.state.dbt_platform_context:
raise ValueError("Undefined login state")
logger.info("Login successful")
return app.state.dbt_platform_context
except OSError as e:
if e.errno == errno.EADDRINUSE:
logger.error(f"Error: Port {port} is already in use.")
raise
```
--------------------------------------------------------------------------------
/examples/aws_strands_agent/dbt_data_scientist/tools/dbt_compile.py:
--------------------------------------------------------------------------------
```python
from strands import Agent, tool
from strands_tools import python_repl, shell, file_read, file_write, editor
import os, json, subprocess
from dotenv import load_dotenv
DBT_COMPILE_ASSISTANT_SYSTEM_PROMPT = """
You are a dbt pipeline expert, a specialized assistant for dbt pipeline analysis and troubleshooting. Your capabilities include:
When asked to 'find a problem' or 'compile a project' on your local dbt project, inspect its JSON logs,
and then:
1) Summarize the problem(s) (file, node, message).
2) Recommend a concrete fix in 1-3 bullet points (e.g., correct ref(), add column, fix Jinja).
3) If no errors, say compile is clean and suggest next step (e.g., run build state:modified+).
"""
@tool
def dbt_compile(query: str) -> str:
"""
Runs `dbt compile --log-format json` in the DBT_ROOT and returns:
returncode
logs: list of compiled JSON events (dbt emits JSON per line)
"""
# Load environment variables from .env file
load_dotenv()
# Get the DBT_ROOT environment variable, default to current directory
dbt_project_location = os.getenv("DBT_PROJECT_LOCATION", os.getcwd())
dbt_executable = os.getenv("DBT_EXECUTABLE")
print(f"Running dbt compile in: {dbt_project_location}")
print(f"Running dbt executable located here: {dbt_executable}")
proc = subprocess.run(
[dbt_executable, "compile", "--log-format", "json"],
cwd=dbt_project_location,
text=True,
capture_output=True
)
print(proc)
logs: List[Dict] = []
for stream in (proc.stdout, proc.stderr):
for line in stream.splitlines():
try:
logs.append(json.loads(line))
except json.JSONDecodeError:
# ignore non-JSON lines quietly
pass
output_of_compile = {"returncode": proc.returncode, "logs": logs}
# Format the query for the compile agent with clear instructions
formatted_query = f"User will have asked to compile a dbt project. Summarize the results of the compile command output: {output_of_compile}"
try:
print("Routed to dbt compile agent")
# Create the dbt compile agent with relevant tools
dbt_compile_agent = Agent(
system_prompt=DBT_COMPILE_ASSISTANT_SYSTEM_PROMPT,
tools=[],
)
agent_response = dbt_compile_agent(formatted_query)
text_response = str(agent_response)
if len(text_response) > 0:
return text_response
return "I apologize, but I couldn't process your dbt compile question. Please try rephrasing or providing more specific details about what you're trying to learn or accomplish."
except Exception as e:
# Return specific error message for dbt compile processing
return f"Error processing your dbt compile query: {str(e)}"
```
--------------------------------------------------------------------------------
/.github/workflows/release.yml:
--------------------------------------------------------------------------------
```yaml
name: Release dbt-mcp
permissions:
contents: write
on:
push:
branches:
- main
paths:
- CHANGELOG.md
jobs:
create-release-tag:
runs-on: ubuntu-latest
outputs:
changie-latest: ${{ steps.changie-latest.outputs.output }}
if: "startsWith(github.event.head_commit.message, 'version:')"
steps:
- uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
- uses: ./.github/actions/setup-python
- name: Get the latest version
id: changie-latest
uses: miniscruff/changie-action@6dcc2533cac0495148ed4046c438487e4dceaa23
with:
version: latest
args: latest
- name: Create tag
run: |
TAG="${{ steps.changie-latest.outputs.output }}"
git config user.name "release-bot"
git config user.email "[email protected]"
git tag "$TAG"
git push origin "$TAG"
pypi-publish:
runs-on: ubuntu-latest
needs: create-release-tag
environment:
name: pypi
permissions:
id-token: write
steps:
- name: checkout code
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
with:
ref: ${{ needs.create-release-tag.outputs.changie-latest }}
fetch-tags: true
- name: setup python
uses: ./.github/actions/setup-python
id: setup-python
- uses: pnpm/action-setup@a7487c7e89a18df4991f7f222e4898a00d66ddda
with:
version: 10
- name: Install go-task
run: sh -c "$(curl --location https://taskfile.dev/install.sh)" -- -d -b /usr/local/bin
- name: Run tests
run: task test:unit
- name: Build
run: task build
- name: Publish package distributions to PyPI
uses: pypa/gh-action-pypi-publish@76f52bc884231f62b9a034ebfe128415bbaabdfc
with:
packages-dir: ./dist
create-github-release:
runs-on: ubuntu-latest
needs: create-release-tag
permissions:
contents: write # required to create a release
steps:
- name: Checkout code
uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
with:
fetch-depth: 0 # Fetches all history for changie to work correctly
- name: Get the latest version
id: changie-latest
uses: miniscruff/changie-action@6dcc2533cac0495148ed4046c438487e4dceaa23
with:
version: latest
args: latest
- name: Create GitHub Release
env:
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
VERSION: ${{ steps.changie-latest.outputs.output }}
run: |
echo "Creating release for version: $VERSION"
gh release create "$VERSION" \
--notes-file ".changes/$VERSION.md" \
--title "$VERSION"
```
--------------------------------------------------------------------------------
/src/dbt_mcp/oauth/refresh_strategy.py:
--------------------------------------------------------------------------------
```python
import asyncio
import time
from typing import Protocol
class RefreshStrategy(Protocol):
"""Protocol for handling token refresh timing and waiting."""
async def wait_until_refresh_needed(self, expires_at: int) -> None:
"""
Wait until token refresh is needed, then return.
Args:
expires_at: Token expiration time as Unix timestamp
"""
...
async def wait_after_error(self) -> None:
"""
Wait an appropriate amount of time after an error before retrying.
"""
...
class DefaultRefreshStrategy:
"""Default strategy that refreshes tokens with a buffer before expiry."""
def __init__(self, buffer_seconds: int = 300, error_retry_delay: float = 5.0):
"""
Initialize with timing configuration.
Args:
buffer_seconds: How many seconds before expiry to refresh
(default: 5 minutes)
error_retry_delay: How many seconds to wait before retrying after an error
(default: 5 seconds)
"""
self.buffer_seconds = buffer_seconds
self.error_retry_delay = error_retry_delay
async def wait_until_refresh_needed(self, expires_at: int) -> None:
"""Wait until refresh is needed (buffer seconds before expiry)."""
current_time = time.time()
refresh_time = expires_at - self.buffer_seconds
time_until_refresh = max(refresh_time - current_time, 0)
if time_until_refresh > 0:
await asyncio.sleep(time_until_refresh)
async def wait_after_error(self) -> None:
"""Wait the configured error retry delay before retrying."""
await asyncio.sleep(self.error_retry_delay)
class MockRefreshStrategy:
"""Mock refresh strategy for testing that allows controlling all timing behavior."""
def __init__(self, wait_seconds: float = 1.0):
"""
Initialize mock refresh strategy.
Args:
wait_seconds: Number of seconds to wait for testing simulations
"""
self.wait_seconds = wait_seconds
self.wait_calls: list[int] = []
self.wait_durations: list[float] = []
self.error_wait_calls: int = 0
async def wait_until_refresh_needed(self, expires_at: int) -> None:
"""Record the call and simulate waiting for the configured duration."""
self.wait_calls.append(expires_at)
self.wait_durations.append(self.wait_seconds)
await asyncio.sleep(self.wait_seconds)
async def wait_after_error(self) -> None:
"""Record the error wait call and simulate waiting for configured duration."""
self.error_wait_calls += 1
await asyncio.sleep(self.wait_seconds)
def reset(self) -> None:
"""Reset all recorded calls."""
self.wait_calls.clear()
self.wait_durations.clear()
self.error_wait_calls = 0
@property
def call_count(self) -> int:
"""Get the number of times wait_until_refresh_needed was called."""
return len(self.wait_calls)
```
--------------------------------------------------------------------------------
/.github/workflows/create-release-pr.yml:
--------------------------------------------------------------------------------
```yaml
name: Create release PR
permissions:
contents: write
pull-requests: write
on:
workflow_dispatch:
inputs:
bump:
type: choice
description: The version bump type.
default: minor
options:
- major
- minor
- patch
prerelease:
type: string
description: Optional pre-release tag (e.g. alpha.1, beta.1, rc.1). Leave empty for stable.
default: ""
jobs:
create-release-pr:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@08eba0b27e820071cde6df949e0beb9ba4906955 # actions/checkout@v4
- uses: ./.github/actions/setup-python
- name: Compute next dir for bump
id: changie-next
uses: miniscruff/changie-action@6dcc2533cac0495148ed4046c438487e4dceaa23
with:
version: latest
args: next ${{ inputs.bump }}
- name: Prepare batch args
id: prepare-batch
shell: bash
run: |
PR="${{ inputs.prerelease }}"
BUMP="${{ inputs.bump }}"
NEXT_DIR="${{ steps.changie-next.outputs.output }}"
if [[ -n "$PR" ]]; then
if [[ ! "$PR" =~ ^(alpha|beta|rc)\.[0-9]+$ ]]; then
echo "Invalid prerelease format: $PR (expected alpha.N, beta.N, rc.N)" >&2
exit 1
fi
echo "args=batch $BUMP --move-dir $NEXT_DIR --prerelease $PR" >> "$GITHUB_OUTPUT"
else
if [[ -d "$NEXT_DIR" ]]; then
echo "args=batch $BUMP --include $NEXT_DIR --remove-prereleases" >> "$GITHUB_OUTPUT"
else
echo "args=batch $BUMP" >> "$GITHUB_OUTPUT"
fi
fi
- name: Batch changes
uses: miniscruff/changie-action@6dcc2533cac0495148ed4046c438487e4dceaa23
with:
version: latest
args: ${{ steps.prepare-batch.outputs.args }}
- name: Merge
uses: miniscruff/changie-action@6dcc2533cac0495148ed4046c438487e4dceaa23
with:
version: latest
args: merge
- name: Get the latest version
id: changie-latest
uses: miniscruff/changie-action@6dcc2533cac0495148ed4046c438487e4dceaa23
with:
version: latest
args: latest
- name: Set latest package version
id: package-version
run: |
VERSION="${{ steps.changie-latest.outputs.output }}"
VERSION_NO_V=$(echo "$VERSION" | cut -c 2-)
MESSAGE=$(cat ".changes/$VERSION.md")
{
echo "version=$VERSION_NO_V"
echo "message<<EOF"
echo "$MESSAGE"
echo "EOF"
} >> "$GITHUB_OUTPUT"
- name: Create Pull Request
uses: peter-evans/create-pull-request@271a8d0340265f705b14b6d32b9829c1cb33d45e
with:
title: "version: ${{ steps.package-version.outputs.version }}"
branch: release/${{ steps.package-version.outputs.version }}
commit-message: |
version: ${{ steps.package-version.outputs.version }}
${{ steps.package-version.outputs.message }}
body: |
## version: ${{ steps.package-version.outputs.version }}
${{ steps.package-version.outputs.message }}
```
--------------------------------------------------------------------------------
/Taskfile.yml:
--------------------------------------------------------------------------------
```yaml
# https://taskfile.dev
version: '3'
# Environment Variables will be set with the following precedence (from high to low):
# .env.local.<env>
# Local environment variables that are specific to an environment have the highest priority.
# For example, to test a staging environment, put any staging-specific variables in
# .env.local.stg. These variables will be set first and will not be overridden by
# variables set in other .env files. A common use case for this is to set specific
# variables used for testing personal staging sites in a provider/consumer configuration.
#
# .env
# Local environment variables that should be common across all environments when doing local
# development. In the most common case, this will have the full 'dev' configuration.
#
# envs/.env.<env>
# Default environment variables for each of the dev, stg and prod environments. If an
# environment variable is not set in any of the local .env files, the default value from this
# file will be used. These default values are the non-secret values that will be used for
# configuration of the shared stg and prod apps managed through CI/CD.
dotenv: [".env.local.{{.ENV}}", ".env", "envs/.env.{{.ENV}}"]
tasks:
default:
desc: "List tasks"
cmds:
- task --list
silent: true
install:
desc: Install dependencies
cmds:
- (cd ui && pnpm install && pnpm build)
- uv sync
- uv pip install -e .
install-pre-commit:
desc: Install pre-commit hooks
cmds:
- uv run pre-commit install
check:
desc: Run linting and type checking
cmds:
- (cd ui && pnpm run lint)
- uv run pre-commit run --all-files
fmt:
desc: Format code
cmds:
- uv run pre-commit run ruff --all-files
run:
desc: "Run the dbt-mcp server"
cmds:
- (cd ui && pnpm install && pnpm build)
- uv run src/dbt_mcp/main.py
dev:
desc: "Run the dbt-mcp server in development mode (with debugger support)"
env:
MCP_TRANSPORT: streamable-http
cmds:
- (cd ui && pnpm install && pnpm build)
- ./.venv/bin/python ./src/dbt_mcp/main.py
inspector:
desc: "Run the dbt-mcp server with MCP inspector"
cmds:
- (cd ui && pnpm install && pnpm build)
- npx @modelcontextprotocol/inspector ./.venv/bin/python src/dbt_mcp/main.py
test:
desc: "Run the tests"
cmds:
- uv run pytest tests {{.CLI_ARGS}}
test:integration:
desc: "Run the integration tests"
cmds:
- uv run pytest tests/integration {{.CLI_ARGS}}
test:unit:
desc: "Run the unit tests"
cmds:
- uv run pytest tests/unit {{.CLI_ARGS}}
eval:
desc: "Run the evals"
cmds:
- uv run pytest evals {{.CLI_ARGS}}
build:
desc: "Build the package"
cmds:
- (cd ui && pnpm install && pnpm build)
- uv build
client:
desc: "Run the test client"
cmds:
- (cd ui && pnpm install && pnpm build)
- uv run src/client/main.py
d2:
desc: "Update d2 diagram from the config"
preconditions:
- sh: command -v d2 &> /dev/null
msg: "Error: d2 command not found. You can install it with 'brew install d2'"
sources:
- docs/diagram.d2
generates:
- docs/d2.png
cmds:
- d2 docs/diagram.d2 docs/d2.png --pad 20
```