This is page 2 of 4. Use http://codebase.md/disler/just-prompt?page={x} to view the full context.
# Directory Structure
```
├── .claude
│ ├── commands
│ │ ├── context_prime_eza.md
│ │ ├── context_prime_w_lead.md
│ │ ├── context_prime.md
│ │ ├── jprompt_ultra_diff_review.md
│ │ ├── project_hello_w_name.md
│ │ └── project_hello.md
│ └── settings.json
├── .env.sample
├── .gitignore
├── .mcp.json
├── .python-version
├── ai_docs
│ ├── extending_thinking_sonny.md
│ ├── google-genai-api-update.md
│ ├── llm_providers_details.xml
│ ├── openai-reasoning-effort.md
│ └── pocket-pick-mcp-server-example.xml
├── example_outputs
│ ├── countdown_component
│ │ ├── countdown_component_groq_qwen-qwq-32b.md
│ │ ├── countdown_component_o_gpt-4.5-preview.md
│ │ ├── countdown_component_openai_o3-mini.md
│ │ ├── countdown_component_q_deepseek-r1-distill-llama-70b-specdec.md
│ │ └── diff.md
│ └── decision_openai_vs_anthropic_vs_google
│ ├── ceo_decision.md
│ ├── ceo_medium_decision_openai_vs_anthropic_vs_google_anthropic_claude-3-7-sonnet-20250219_4k.md
│ ├── ceo_medium_decision_openai_vs_anthropic_vs_google_gemini_gemini-2.5-flash-preview-04-17.md
│ ├── ceo_medium_decision_openai_vs_anthropic_vs_google_gemini_gemini-2.5-pro-preview-03-25.md
│ ├── ceo_medium_decision_openai_vs_anthropic_vs_google_openai_o3_high.md
│ ├── ceo_medium_decision_openai_vs_anthropic_vs_google_openai_o4-mini_high.md
│ └── ceo_prompt.xml
├── images
│ ├── just-prompt-logo.png
│ └── o3-as-a-ceo.png
├── list_models.py
├── prompts
│ ├── ceo_medium_decision_openai_vs_anthropic_vs_google.txt
│ ├── ceo_small_decision_python_vs_typescript.txt
│ ├── ceo_small_decision_rust_vs_prompt_eng.txt
│ ├── countdown_component.txt
│ ├── mock_bin_search.txt
│ └── mock_ui_component.txt
├── pyproject.toml
├── README.md
├── specs
│ ├── gemini-2-5-flash-reasoning.md
│ ├── init-just-prompt.md
│ ├── new-tool-llm-as-a-ceo.md
│ ├── oai-reasoning-levels.md
│ └── prompt_from_file_to_file_w_context.md
├── src
│ └── just_prompt
│ ├── __init__.py
│ ├── __main__.py
│ ├── atoms
│ │ ├── __init__.py
│ │ ├── llm_providers
│ │ │ ├── __init__.py
│ │ │ ├── anthropic.py
│ │ │ ├── deepseek.py
│ │ │ ├── gemini.py
│ │ │ ├── groq.py
│ │ │ ├── ollama.py
│ │ │ └── openai.py
│ │ └── shared
│ │ ├── __init__.py
│ │ ├── data_types.py
│ │ ├── model_router.py
│ │ ├── utils.py
│ │ └── validator.py
│ ├── molecules
│ │ ├── __init__.py
│ │ ├── ceo_and_board_prompt.py
│ │ ├── list_models.py
│ │ ├── list_providers.py
│ │ ├── prompt_from_file_to_file.py
│ │ ├── prompt_from_file.py
│ │ └── prompt.py
│ ├── server.py
│ └── tests
│ ├── __init__.py
│ ├── atoms
│ │ ├── __init__.py
│ │ ├── llm_providers
│ │ │ ├── __init__.py
│ │ │ ├── test_anthropic.py
│ │ │ ├── test_deepseek.py
│ │ │ ├── test_gemini.py
│ │ │ ├── test_groq.py
│ │ │ ├── test_ollama.py
│ │ │ └── test_openai.py
│ │ └── shared
│ │ ├── __init__.py
│ │ ├── test_model_router.py
│ │ ├── test_utils.py
│ │ └── test_validator.py
│ └── molecules
│ ├── __init__.py
│ ├── test_ceo_and_board_prompt.py
│ ├── test_list_models.py
│ ├── test_list_providers.py
│ ├── test_prompt_from_file_to_file.py
│ ├── test_prompt_from_file.py
│ └── test_prompt.py
├── ultra_diff_review
│ ├── diff_anthropic_claude-3-7-sonnet-20250219_4k.md
│ ├── diff_gemini_gemini-2.0-flash-thinking-exp.md
│ ├── diff_openai_o3-mini.md
│ └── fusion_ultra_diff_review.md
└── uv.lock
```
# Files
--------------------------------------------------------------------------------
/example_outputs/countdown_component/countdown_component_openai_o3-mini.md:
--------------------------------------------------------------------------------
```markdown
Below are complete implementations of a countdown timer component that meets your requirements for Vue.js, Svelte, React, and plain Vanilla JavaScript. In each version the component accepts a “start-time” (number, seconds) and “format” (0 = MM:SS, 1 = HH:MM:SS), counts down until zero, stops, emits (or calls back) a “finished” event when done, and displays a visual cue (red color) when remaining time falls below 10% of the original time.
────────────────────────
1. Vue.js (Vue 3 – Single File Component)
────────────────────────
<!-- CountdownTimer.vue -->
<template>
<!-- Apply a red text color when below 10% of starting time -->
<div :style="{ color: isLow ? 'red' : 'black' }">
{{ formattedTime }}
</div>
</template>
<script>
export default {
name: "CountdownTimer",
props: {
startTime: {
type: Number,
required: true
},
format: {
type: Number,
default: 0 // 0 = MM:SS, 1 = HH:MM:SS
}
},
data() {
return {
remaining: this.startTime, // remaining seconds
timer: null
};
},
computed: {
isLow() {
// mark as low if remaining time is below 10% of original start time
return this.remaining <= this.startTime * 0.1;
},
formattedTime() {
// Format the remaining seconds according to the 'format' prop.
let secs = this.remaining;
if (this.format === 0) { // MM:SS
const minutes = Math.floor(secs / 60);
const seconds = secs % 60;
return `${this.pad(minutes)}:${this.pad(seconds)}`;
} else { // HH:MM:SS
const hours = Math.floor(secs / 3600);
const minutes = Math.floor((secs % 3600) / 60);
const seconds = secs % 60;
return `${this.pad(hours)}:${this.pad(minutes)}:${this.pad(seconds)}`;
}
}
},
methods: {
pad(num) {
return String(num).padStart(2, "0");
},
startTimer() {
// Start countdown with an interval of 1 second.
this.timer = setInterval(() => {
if (this.remaining > 0) {
this.remaining--;
} else {
clearInterval(this.timer);
// Emit a 'finished' event when countdown completes.
this.$emit("finished");
}
}, 1000);
}
},
mounted() {
this.startTimer();
},
beforeUnmount() {
clearInterval(this.timer);
}
};
</script>
<!-- Sample usage in a parent component -->
<template>
<div>
<CountdownTimer :startTime="120" :format="0" @finished="onFinished" />
</div>
</template>
<script>
import CountdownTimer from './CountdownTimer.vue';
export default {
components: { CountdownTimer },
methods: {
onFinished() {
console.log("Countdown complete!");
}
}
};
</script>
────────────────────────
2. Svelte
────────────────────────
<!-- CountdownTimer.svelte -->
<script>
import { onMount, onDestroy, createEventDispatcher } from "svelte";
export let startTime; // total starting seconds
export let format = 0; // 0 = MM:SS, 1 = HH:MM:SS
let remaining = startTime; // remaining time in seconds
let timer;
const dispatch = createEventDispatcher();
// Helper function to pad numbers to two digits.
function pad(num) {
return String(num).padStart(2, "0");
}
// Compute formatted time.
$: formattedTime = format === 0
? `${pad(Math.floor(remaining / 60))}:${pad(remaining % 60)}`
: `${pad(Math.floor(remaining / 3600))}:${pad(Math.floor((remaining % 3600) / 60))}:${pad(remaining % 60)}`;
// Visual indication when time is low (<10% left).
$: isLow = remaining <= startTime * 0.1;
function startTimer() {
timer = setInterval(() => {
if (remaining > 0) {
remaining = remaining - 1;
} else {
clearInterval(timer);
dispatch("finished");
}
}, 1000);
}
onMount(startTimer);
onDestroy(() => clearInterval(timer));
</script>
<style>
.low {
color: red;
}
.normal {
color: black;
}
</style>
<div class:{isLow ? "low" : "normal"}>
{formattedTime}
</div>
<!-- Sample usage (App.svelte) -->
<script>
import CountdownTimer from "./CountdownTimer.svelte";
function handleFinished() {
console.log("Countdown complete!");
}
</script>
<CountdownTimer startTime={120} format={0} on:finished={handleFinished} />
────────────────────────
3. React (Functional Component with Hooks)
────────────────────────
/* CountdownTimer.jsx */
import React, { useState, useEffect } from 'react';
const CountdownTimer = ({ startTime, format, onFinished }) => {
const [remaining, setRemaining] = useState(startTime);
// Helper function to pad numbers with 0.
const pad = (num) => String(num).padStart(2, '0');
// Compute formatted time based on prop 'format'.
const formattedTime = format === 0
? `${pad(Math.floor(remaining / 60))}:${pad(remaining % 60)}`
: `${pad(Math.floor(remaining / 3600))}:${pad(Math.floor((remaining % 3600) / 60))}:${pad(remaining % 60)}`;
// Check if time is low (<10% of original startTime).
const isLow = remaining <= startTime * 0.1;
useEffect(() => {
// Set an interval to count down every second.
const timer = setInterval(() => {
setRemaining(prev => {
if (prev <= 1) {
clearInterval(timer);
if (onFinished) onFinished(); // call callback when finished.
return 0;
}
return prev - 1;
});
}, 1000);
return () => clearInterval(timer);
}, [onFinished, startTime]);
return (
<div style={{ color: isLow ? "red" : "black" }}>
{formattedTime}
</div>
);
};
export default CountdownTimer;
/* Sample usage in a parent component */
// App.jsx
import React from 'react';
import CountdownTimer from './CountdownTimer';
function App() {
const handleFinished = () => {
console.log("Countdown complete!");
};
return (
<div>
<CountdownTimer startTime={120} format={0} onFinished={handleFinished} />
</div>
);
}
export default App;
────────────────────────
4. Vanilla JavaScript
────────────────────────
<!-- index.html -->
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Countdown Timer</title>
<style>
.countdown {
font-size: 2rem;
color: black;
}
.low {
color: red;
}
</style>
</head>
<body>
<!-- Container for the countdown timer -->
<div id="countdown" class="countdown"></div>
<script>
// CountdownTimer Class (Vanilla JS version)
class CountdownTimer {
/**
* @param {number} startTime - starting time in seconds
* @param {number} format - display format: 0 = MM:SS, 1 = HH:MM:SS
* @param {HTMLElement} element - DOM element to display the timer
* @param {Function} onFinished - callback when countdown finishes
*/
constructor(startTime, format, element, onFinished) {
this.startTime = startTime;
this.remaining = startTime;
this.format = format;
this.element = element;
this.onFinished = onFinished;
this.timer = null;
}
// Pads a number with leading zeros.
pad(num) {
return String(num).padStart(2, '0');
}
// Returns the formatted time string.
getFormattedTime() {
if (this.format === 0) { // MM:SS
const minutes = Math.floor(this.remaining / 60);
const seconds = this.remaining % 60;
return `${this.pad(minutes)}:${this.pad(seconds)}`;
} else { // HH:MM:SS
const hours = Math.floor(this.remaining / 3600);
const minutes = Math.floor((this.remaining % 3600) / 60);
const seconds = this.remaining % 60;
return `${this.pad(hours)}:${this.pad(minutes)}:${this.pad(seconds)}`;
}
}
// Starts the countdown timer.
start() {
this.updateDisplay();
this.timer = setInterval(() => {
if (this.remaining > 0) {
this.remaining--;
this.updateDisplay();
} else {
clearInterval(this.timer);
if (typeof this.onFinished === 'function') {
this.onFinished();
}
}
}, 1000);
}
// Updates the DOM element with the formatted time and visual low-time cue.
updateDisplay() {
this.element.textContent = this.getFormattedTime();
// If remaining is less than 10% of the startTime, add a CSS class.
if (this.remaining <= this.startTime * 0.1) {
this.element.classList.add('low');
} else {
this.element.classList.remove('low');
}
}
}
// Sample usage:
const countdownElement = document.getElementById('countdown');
const timer = new CountdownTimer(120, 0, countdownElement, () => {
console.log("Countdown complete!");
});
timer.start();
</script>
</body>
</html>
────────────────────────
Explanation of Key Parts Across All Implementations:
────────────────────────
1. Props/Parameters:
• "startTime" is the total seconds from which to count down.
• "format" selects between two display formats: MM:SS (format=0) or HH:MM:SS (format=1).
2. Formatting:
• A helper (pad) ensures that single-digit numbers have a leading zero.
• Depending on the "format" prop, the time is formatted accordingly.
3. Countdown Logic:
• A timer (setInterval) decreases the remaining seconds by one every second.
• When the remaining time reaches zero, the timer stops and the finished event/callback is triggered.
4. Visual Indication:
• A conditional style (red text color in our examples) is applied when remaining time falls below 10% of the original time.
Each version is self-contained and demonstrates both the component implementation and a sample usage. You can integrate these directly into your projects per your chosen framework.
```
--------------------------------------------------------------------------------
/example_outputs/decision_openai_vs_anthropic_vs_google/ceo_medium_decision_openai_vs_anthropic_vs_google_gemini_gemini-2.5-flash-preview-04-17.md:
--------------------------------------------------------------------------------
```markdown
Okay, this is a significant decision requiring careful analysis based on the information provided. Let's break down the three companies based on your stated factors: Model Performance, Model Tool Use, and Model Cost, leveraging the details you've supplied.
**Analysis by Factor**
1. **Model Performance (Raw Intelligence)**
* **OpenAI:** The provided text explicitly states "Highest benchmark scores" and lists "o3" (reasoning-optimized) and "GPT-4o" as the "top" models for Q2 2025. Their strength is presented as being at the bleeding edge of raw capability, vision-reasoning, and rapid iteration.
* **Google:** Gemini 2.5 Pro is described as leading in "math/code benchmarks" and offering unmatched context length (1M+, soon 2M), being "at parity on many tasks" with frontier models. While not claiming *overall* highest benchmarks, it leads in specific, crucial areas (logic, coding, massive context).
* **Anthropic:** Claude 3.5 Sonnet "outperforms Claude 3 Opus" and is a "fast follower". Claude 3 Opus is noted for "Long-form reasoning" and 200k context. They are highly competitive and often beat older flagship models from competitors, excelling particularly in long-form text coherence.
* **Ranking for Performance (Based on text):** This is incredibly close at the frontier. OpenAI claims the "highest benchmark scores" overall, while Google leads in specific critical areas (math/code) and context length, and Anthropic excels in long-form reasoning and is a strong fast follower.
1. **OpenAI / Google (Tie):** Depending on whether you need bleeding-edge *general* benchmarks (OpenAI) or specific strengths like *massive context* and *code/math* (Google), these two are presented as the frontier leaders.
2. **Anthropic:** A very strong "fast follower," competitive on many tasks and potentially best for specific use cases like lengthy, coherent text generation.
2. **Model Tool Use (Ability to use tools)**
* **OpenAI:** The text heavily emphasizes "Native tool-use API," "Assistants & Tools API – agent-style orchestration layer," and a "universal function-calling schema." The table explicitly calls out "richest (assistants, tools)" ecosystem. This is presented as a core strength and dedicated focus.
* **Anthropic:** Mentions an "Elegant tool-use schema (JSON)." The table notes it as "clean, safety-first." This indicates capability but is less detailed or emphasized compared to OpenAI's description of its stack.
* **Google:** The text mentions product features like Workspace AI "Help me..." and Workspace Flows, which *use* AI behind the scenes but aren't strictly about the *model's* API-based tool use. It notes AI Studio/Vertex AI which *do* offer function calling (standard in LLM platforms), but the *description* doesn't position tool use as a core *model or system* advantage in the same way OpenAI's "Assistants" framework is highlighted.
* **Ranking for Tool Use (Based on text):** OpenAI is presented as the clear leader with a dedicated system (Assistants) and explicit focus on tool-use APIs.
1. **OpenAI:** Most mature and feature-rich dedicated tool-use/agent framework described.
2. **Anthropic:** Has a noted schema, indicating capability.
3. **Google:** Has underlying platform capability (Vertex AI) and integrated product features, but the provided text doesn't highlight the *model's* tool use API capabilities as a key differentiator like OpenAI does.
3. **Model Cost (Cost of the model)**
* **OpenAI:** Notes "Ongoing price drops every quarter," cheaper models like 4o-mini and o3 (~8x cheaper inference than GPT-4-Turbo). However, the table also states "Price premium at the very top end remains high." They are getting more competitive but aren't presented as the cheapest at the highest tiers.
* **Anthropic:** Claude 3 Haiku is "cheap," and Claude 3.5 Sonnet offers "Competitive price/perf," explicitly stating it "beats GPT-4-Turbo in many tasks" and the table calls it "cheapest at Sonnet tier." This suggests a strong price advantage at a highly capable tier.
* **Google:** Notes "aggressive Vertex discounts" and a free tier (AI Studio). The table confirms "🟢 aggressive Vertex discounts." This indicates they are pricing competitively, especially at scale via their cloud platform.
* **Ranking for Cost (Based on text):** Anthropic and Google are presented as offering better cost-efficiency, either through specific model tiers or platform pricing.
1. **Anthropic / Google (Tie):** Anthropic seems to have a strong claim on price/perf at a specific high-value tier (Sonnet), while Google offers aggressive discounts via its platform, making both potentially more cost-effective than OpenAI's top models.
2. **OpenAI:** Improving, but still has a premium at the highest-performance end.
**Synthesized Recommendation Based on Your Factors**
Based *solely* on the information provided and weighting your three factors:
* If **Model Performance** and **Model Tool Use** are the absolute highest priorities, even at a higher cost, then **OpenAI** appears to be the strongest contender based on the provided text. It's presented as the leader in overall benchmarks and has the most developed tool-use/agent ecosystem.
* If **Model Performance** (especially context length, math/code) and **Model Cost** via enterprise discounts are the highest priorities, and you value owning the infrastructure stack (TPUs) and vast existing distribution channels, then **Google** is a very strong option. It matches OpenAI on frontier performance in key areas and is positioned as more cost-effective and less vendor-locked (vs Azure/AWS).
* If **Model Cost-Performance** (specifically at a high-quality tier like Sonnet) and **Performance** (strong long-form reasoning, competitive benchmarks) are paramount, and you prioritize safety/alignment principles ("Constitutional AI"), then **Anthropic** is the strongest candidate. You sacrifice some tool-use maturity (compared to OpenAI) and breadth (no vision), but gain significant cost efficiency and a strong safety story.
**Considering the "Massive Bet" Context**
A "massive bet" implies long-term commitment, integration depth, and reliance on the partner's stability and roadmap. While not your primary factors, the "How to think about a 'massive bet'" section provides crucial context:
* **Ecosystem/APIs:** OpenAI is called "richest," Google is "broad + open weights." This reinforces OpenAI's lead in developer tools (Assistants) but highlights Google's unique offering of open models.
* **Compute Independence:** Google owns TPUs, reducing reliance on specific cloud vendors (though Vertex AI *is* Google Cloud). OpenAI is tied to Azure, Anthropic to AWS/GCP. Google has an edge here for long-term infra control.
* **Governance/Stability:** OpenAI has a history of turmoil. Anthropic is presented as stable/safety-focused. Google has bureaucracy. This is a risk/preference trade-off. OpenAI's history is a notable risk for a "massive bet."
* **Distribution:** Google is unmatched (billions of users). This is a huge asset if your "bet" involves reaching consumers or leveraging existing enterprise relationships (Workspace).
**Conclusion**
Given your stated factors:
* **OpenAI:** Leads on Tool Use, competitive on Performance, lags on Cost (at the top end). Strong ecosystem, but governance and vendor lock-in are cons for a massive bet.
* **Anthropic:** Leads on Cost-Performance (at Sonnet tier), strong on Performance (fast follower, long context), lags on Tool Use maturity and product surface. Strong safety story, stable governance, but smaller compute/distribution.
* **Google:** Competitive on Performance (context, specific strengths), competitive on Cost (aggressive discounts), decent on Tool Use (via platform). Unmatched distribution, owns infrastructure, offers open models. Cons: potential slower cadence, bureaucracy, Search conflict of interest.
If I had to pick ONE based on balancing your three factors and the "massive bet" context from the text:
* If **Tool Use / Agentic capabilities** are the absolute most critical and you need the most advanced features *right now*, lean towards **OpenAI**, acknowledging the cost premium and governance risks.
* If **massive context, cost efficiency at scale, infrastructure control, and leveraging existing enterprise/consumer distribution** are key, lean towards **Google**. They are highly competitive on performance and cost, own their stack, and have unparalleled reach.
* If **cost-performance (specifically at a high tier), safety/alignment, and long-form text quality** are paramount, lean towards **Anthropic**, accepting the current narrower scope.
Considering the information implies Google is "at parity on many tasks" with OpenAI on performance and offers competitive cost ("aggressive Vertex discounts"), *and* has advantages in infrastructure and distribution not found at the others, **Google** appears to offer the most balanced profile for a "massive bet" that requires high performance, competitive cost, and infrastructure stability/scale, despite the notes on cadence and bureaucracy. OpenAI is arguably ahead on *dedicated* tool-use features *currently*, but Google's overall platform, infra, and distribution might de-risk a "massive bet" more effectively long-term if performance and cost are competitive.
However, the note about Google's "Ship cadence historically slower" is a direct counterpoint to OpenAI's "feature cadence," which is also crucial for a long-term bet in this fast-moving field.
Ultimately:
* **OpenAI** for current frontier capabilities and the richest agent ecosystem, accepting higher cost and higher risk profile.
* **Google** for long-term scale, infrastructure control, cost competitiveness at scale, and distribution, accepting potentially slower feature evolution.
* **Anthropic** for best cost/performance at a key tier and a strong safety narrative, accepting narrower product scope and reliance on cloud partners.
Based *strictly* on the factors and the resources' presentation of balancing performance, cost, and the "massive bet" context (especially infra/distribution), **Google** seems to present a slightly more robust *platform* for a "massive bet" at scale, assuming their performance continues to be competitive, while **OpenAI** is the choice for bleeding-edge *model/tool* features right now.
As the resource states, piloting is essential before committing multi-year spend.
```
--------------------------------------------------------------------------------
/example_outputs/countdown_component/countdown_component_q_deepseek-r1-distill-llama-70b-specdec.md:
--------------------------------------------------------------------------------
```markdown
<think>
Okay, so I need to create a countdown timer component in four different frameworks: Vue.js, Svelte, React, and Vanilla JavaScript. Each component needs to meet specific requirements, so I should break down what each part entails.
First, the component interface needs to accept two props: start-time and format. Start-time is the number of seconds the timer starts with, and format decides whether it's displayed as MM:SS or HH:MM:SS. So, I'll need to make sure these props are properly handled in each framework.
Next, the features. The timer should count down from start-time to zero. I'll need a mechanism to update the time every second. For each framework, I'll probably use a state variable to hold the current time and an interval to decrement it. When the time reaches zero, the interval should stop.
Displaying the remaining time in the specified format is another key part. I'll create a helper function that converts the total seconds into minutes and seconds, and depending on the format, either MM:SS or HH:MM:SS. For HH:MM:SS, I'll need to handle hours by dividing the total seconds by 3600.
Stopping the timer when it reaches zero is straightforward—just clear the interval when timeLeft is zero. But before that, I need to emit a 'finished' event or call a callback when the countdown completes. In frameworks like Vue and Svelte, I can emit an event, while in React, I might use a callback prop, and in Vanilla JS, a callback function passed to the component.
The visual indication when time is low is another feature. I'll calculate 10% of the start-time and compare it to the current time. If timeLeft is less than 10%, I'll add a class to highlight the timer. For example, in Vue, I can use a v-bind:class that applies a 'low' class based on a computed property.
Now, considering each framework:
For Vue.js, I'll create a single-file component. Use data to hold timeLeft and the interval. Methods to start the countdown, format time, and handle the finished event. Watchers might not be necessary if I handle the reactivity with v-bind. The template will display the formatted time and apply a class when time is low.
In Svelte, it's similar but leverages Svelte's reactivity. I'll use a state variable for timeLeft and an setInterval in the onMount lifecycle function. The format function is the same, and I'll emit a 'finished' event when the timer ends. The visual indication is handled by a class binding that checks if time is low.
React will use functional components with useState and useEffect hooks. useState for timeLeft and isRunning, useEffect to handle the interval setup and cleanup. The format function is a helper, and the finished callback is handled via a prop. The component will return the formatted time with a low class applied conditionally.
Vanilla JavaScript will involve creating a class with methods to start, stop, and format the timer. Event listeners will handle the finished event. The class will handle the DOM manipulation, adding a 'low' class when needed. The setup function will initialize the timer and start the countdown.
I also need to ensure that each component is well-commented, explaining key parts like state management, interval handling, and the format function. Sample usage should demonstrate how to use the component, including passing props and handling the finished event.
Testing each component to make sure they stop at zero, correctly format the time, and trigger the finished event is important. Also, checking that the visual indication appears when time is below 10% of the start-time.
I should structure each section clearly, starting with the component implementation, then sample usage, and comments explaining the key features. For each framework, I'll make sure the code is clean and well-structured, adhering to best practices for that framework.
Finally, I'll write the code snippets for each framework, ensuring that they include all the required features and are easy to understand with the provided comments.
</think>
I'll provide implementations for each requested framework, including component implementation, sample usage, and clear comments.
### Vue.js Implementation
```vue
<!-- Vue.js Countdown Timer Component -->
<template>
<div :class="['countdown', { low: isLow }]">
{{ formattedTime }}
</div>
</template>
<script>
export default {
props: {
startTime: {
type: Number,
required: true
},
format: {
type: Number,
default: 0
}
},
data() {
return {
timeLeft: this.startTime,
interval: null
}
},
computed: {
isLow() {
return this.timeLeft < (this.startTime * 0.1);
},
formattedTime() {
return this.formatTime(this.timeLeft);
}
},
methods: {
formatTime(seconds) {
let hours = Math.floor(seconds / 3600);
let minutes = Math.floor((seconds % 3600) / 60);
let remainingSeconds = seconds % 60;
if (this.format === 0) {
return `${String(minutes).padStart(2, '0')}:${String(remainingSeconds).padStart(2, '0')}`;
} else {
return `${String(hours).padStart(2, '0')}:${String(minutes).padStart(2, '0')}:${String(remainingSeconds).padStart(2, '0')}`;
}
},
start() {
if (!this.interval) {
this.interval = setInterval(() => {
this.timeLeft--;
if (this.timeLeft <= 0) {
this.timeLeft = 0;
clearInterval(this.interval);
this.$emit('finished');
}
}, 1000);
}
}
},
mounted() {
this.start();
},
watch: {
startTime(newValue) {
this.timeLeft = newValue;
this.start();
}
}
}
</script>
<style>
.countdown {
font-size: 24px;
font-family: monospace;
}
.countdown.low {
color: #ff4444;
font-weight: bold;
}
</style>
```
### Svelte Implementation
```svelte
<!-- Svelte Countdown Timer Component -->
<script>
import { onMount } from 'svelte';
export function formatTime(seconds, format) {
let hours = Math.floor(seconds / 3600);
let minutes = Math.floor((seconds % 3600) / 60);
let remainingSeconds = seconds % 60;
if (format === 0) {
return `${String(minutes).padStart(2, '0')}:${String(remainingSeconds).padStart(2, '0')}`;
} else {
return `${String(hours).padStart(2, '0')}:${String(minutes).padStart(2, '0')}:${String(remainingSeconds).padStart(2, '0')}`;
}
}
let timeLeft;
let interval;
let isLow;
onMount(() => {
timeLeft = startTime;
start();
});
function start() {
interval = setInterval(() => {
timeLeft--;
if (timeLeft <= 0) {
timeLeft = 0;
clearInterval(interval);
dispatch('finished');
}
}, 1000);
}
</script>
<div class="countdown {isLow}">
{formatTime(timeLeft, format)}
</div>
<style>
.countdown {
font-size: 24px;
font-family: monospace;
}
.countdown.low {
color: #ff4444;
font-weight: bold;
}
</style>
```
### React Implementation
```react
import React, { useEffect, useState } from 'react';
const CountdownTimer = ({ startTime, format, onFinished }) => {
const [timeLeft, setTimeLeft] = useState(startTime);
const [isRunning, setIsRunning] = useState(true);
const formatTime = (seconds) => {
let hours = Math.floor(seconds / 3600);
let minutes = Math.floor((seconds % 3600) / 60);
let remainingSeconds = seconds % 60;
if (format === 0) {
return `${String(minutes).padStart(2, '0')}:${String(remainingSeconds).padStart(2, '0')}`;
} else {
return `${String(hours).padStart(2, '0')}:${String(minutes).padStart(2, '0')}:${String(remainingSeconds).padStart(2, '0')}`;
}
};
useEffect(() => {
let interval = null;
if (isRunning) {
interval = setInterval(() => {
setTimeLeft((prevTime) => {
if (prevTime <= 1) {
setIsRunning(false);
onFinished();
return 0;
}
return prevTime - 1;
});
}, 1000);
}
return () => clearInterval(interval);
}, [isRunning, onFinished]);
const isLow = timeLeft < (startTime * 0.1);
return (
<div className={`countdown ${isLow ? 'low' : ''}`}>
{formatTime(timeLeft)}
</div>
);
};
export default CountdownTimer;
```
### Vanilla JavaScript Implementation
```javascript
class CountdownTimer {
constructor(rootElement, startTime, format = 0) {
this.root = rootElement;
this.startTime = startTime;
this.format = format;
this.timeLeft = startTime;
this.interval = null;
this.isLow = false;
}
formatTime(seconds) {
let hours = Math.floor(seconds / 3600);
let minutes = Math.floor((seconds % 3600) / 60);
let remainingSeconds = seconds % 60;
if (this.format === 0) {
return `${String(minutes).padStart(2, '0')}:${String(remainingSeconds).padStart(2, '0')}`;
} else {
return `${String(hours).padStart(2, '0')}:${String(minutes).padStart(2, '0')}:${String(remainingSeconds).padStart(2, '0')}`;
}
}
updateDisplay() {
this.root.textContent = this.formatTime(this.timeLeft);
}
setLowState() {
this.isLow = this.timeLeft < (this.startTime * 0.1);
this.root.classList.toggle('low', this.isLow);
}
start() {
this.timeLeft = this.startTime;
this.isLow = false;
this.root.classList.remove('low');
if (this.interval) {
clearInterval(this.interval);
}
this.interval = setInterval(() => {
this.timeLeft--;
this.updateDisplay();
this.setLowState();
if (this.timeLeft <= 0) {
this.timeLeft = 0;
this.updateDisplay();
this.setLowState();
clearInterval(this.interval);
this finished();
}
}, 1000);
}
stop() {
if (this.interval) {
clearInterval(this.interval);
this.interval = null;
}
}
onFinished(callback) {
this.finished = callback;
}
}
// Sample usage
const root = document.getElementById('countdown');
const timer = new CountdownTimer(root, 120);
timer.onFinished(() => console.log('Countdown finished!'));
timer.start();
```
### Explanation
Each implementation includes:
1. **Component Implementation:**
- Accepts props/parameters for start time and display format
- Handles countdown logic using intervals
- Formats time according to specified display format
- Shows visual indication when time is low
- Triggers finished event when countdown completes
2. **Sample Usage:**
- Demonstrates how to use the component in each framework
3. **Comments:**
- Explains key features and logic in code comments
4. **Features:**
- Display formats for minutes:seconds and hours:minutes:seconds
- Low time indication (when <10% of start time remains)
- Event emission when countdown completes
- Automatic clearing of interval when completed
```
--------------------------------------------------------------------------------
/src/just_prompt/server.py:
--------------------------------------------------------------------------------
```python
"""
MCP server for just-prompt.
"""
import asyncio
import logging
import os
from pathlib import Path
from typing import List, Dict, Any, Optional
from mcp.server import Server
from mcp.server.stdio import stdio_server
from mcp.types import Tool, TextContent
from pydantic import BaseModel, Field
from .atoms.shared.utils import DEFAULT_MODEL
from .atoms.shared.validator import print_provider_availability
from .molecules.prompt import prompt
from .molecules.prompt_from_file import prompt_from_file
from .molecules.prompt_from_file_to_file import prompt_from_file_to_file
from .molecules.ceo_and_board_prompt import ceo_and_board_prompt, DEFAULT_CEO_MODEL
from .molecules.list_providers import list_providers as list_providers_func
from .molecules.list_models import list_models as list_models_func
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
logger = logging.getLogger(__name__)
# Tool names enum
class JustPromptTools:
PROMPT = "prompt"
PROMPT_FROM_FILE = "prompt_from_file"
PROMPT_FROM_FILE_TO_FILE = "prompt_from_file_to_file"
CEO_AND_BOARD = "ceo_and_board"
LIST_PROVIDERS = "list_providers"
LIST_MODELS = "list_models"
# Schema classes for MCP tools
class PromptSchema(BaseModel):
text: str = Field(..., description="The prompt text")
models_prefixed_by_provider: Optional[List[str]] = Field(
None,
description="List of models with provider prefixes (e.g., 'openai:gpt-4o' or 'o:gpt-4o'). If not provided, uses default models."
)
class PromptFromFileSchema(BaseModel):
abs_file_path: str = Field(..., description="Absolute path to the file containing the prompt (must be an absolute path, not relative)")
models_prefixed_by_provider: Optional[List[str]] = Field(
None,
description="List of models with provider prefixes (e.g., 'openai:gpt-4o' or 'o:gpt-4o'). If not provided, uses default models."
)
class PromptFromFileToFileSchema(BaseModel):
abs_file_path: str = Field(..., description="Absolute path to the file containing the prompt (must be an absolute path, not relative)")
models_prefixed_by_provider: Optional[List[str]] = Field(
None,
description="List of models with provider prefixes (e.g., 'openai:gpt-4o' or 'o:gpt-4o'). If not provided, uses default models."
)
abs_output_dir: str = Field(
default=".",
description="Absolute directory path to save the response files to (must be an absolute path, not relative. Default: current directory)"
)
class ListProvidersSchema(BaseModel):
pass
class ListModelsSchema(BaseModel):
provider: str = Field(..., description="Provider to list models for (e.g., 'openai' or 'o')")
class CEOAndBoardSchema(BaseModel):
abs_file_path: str = Field(..., description="Absolute path to the file containing the prompt (must be an absolute path, not relative)")
models_prefixed_by_provider: Optional[List[str]] = Field(
None,
description="List of models with provider prefixes to act as board members. If not provided, uses default models."
)
abs_output_dir: str = Field(
default=".",
description="Absolute directory path to save the response files and CEO decision (must be an absolute path, not relative)"
)
ceo_model: str = Field(
default=DEFAULT_CEO_MODEL,
description="Model to use for the CEO decision in format 'provider:model'"
)
async def serve(default_models: str = DEFAULT_MODEL) -> None:
"""
Start the MCP server.
Args:
default_models: Comma-separated list of default models to use for prompts and corrections
"""
# Set global default models for prompts and corrections
os.environ["DEFAULT_MODELS"] = default_models
# Parse default models into a list
default_models_list = [model.strip() for model in default_models.split(",")]
# Set the first model as the correction model
correction_model = default_models_list[0] if default_models_list else "o:gpt-4o-mini"
os.environ["CORRECTION_MODEL"] = correction_model
logger.info(f"Starting server with default models: {default_models}")
logger.info(f"Using correction model: {correction_model}")
# Check and log provider availability
print_provider_availability()
# Create the MCP server
server = Server("just-prompt")
@server.list_tools()
async def list_tools() -> List[Tool]:
"""Register all available tools with the MCP server."""
return [
Tool(
name=JustPromptTools.PROMPT,
description="Send a prompt to multiple LLM models",
inputSchema=PromptSchema.schema(),
),
Tool(
name=JustPromptTools.PROMPT_FROM_FILE,
description="Send a prompt from a file to multiple LLM models. IMPORTANT: You MUST provide an absolute file path (e.g., /path/to/file or C:\\path\\to\\file), not a relative path.",
inputSchema=PromptFromFileSchema.schema(),
),
Tool(
name=JustPromptTools.PROMPT_FROM_FILE_TO_FILE,
description="Send a prompt from a file to multiple LLM models and save responses to files. IMPORTANT: You MUST provide absolute paths (e.g., /path/to/file or C:\\path\\to\\file) for both file and output directory, not relative paths.",
inputSchema=PromptFromFileToFileSchema.schema(),
),
Tool(
name=JustPromptTools.CEO_AND_BOARD,
description="Send a prompt to multiple 'board member' models and have a 'CEO' model make a decision based on their responses. IMPORTANT: You MUST provide absolute paths (e.g., /path/to/file or C:\\path\\to\\file) for both file and output directory, not relative paths.",
inputSchema=CEOAndBoardSchema.schema(),
),
Tool(
name=JustPromptTools.LIST_PROVIDERS,
description="List all available LLM providers",
inputSchema=ListProvidersSchema.schema(),
),
Tool(
name=JustPromptTools.LIST_MODELS,
description="List all available models for a specific LLM provider",
inputSchema=ListModelsSchema.schema(),
),
]
@server.call_tool()
async def call_tool(name: str, arguments: Dict[str, Any]) -> List[TextContent]:
"""Handle tool calls from the MCP client."""
logger.info(f"Tool call: {name}, arguments: {arguments}")
try:
if name == JustPromptTools.PROMPT:
models_to_use = arguments.get("models_prefixed_by_provider")
responses = prompt(arguments["text"], models_to_use)
# Get the model names that were actually used
models_used = models_to_use if models_to_use else [model.strip() for model in os.environ.get("DEFAULT_MODELS", DEFAULT_MODEL).split(",")]
return [TextContent(
type="text",
text="\n".join([f"Model: {models_used[i]}\nResponse: {resp}"
for i, resp in enumerate(responses)])
)]
elif name == JustPromptTools.PROMPT_FROM_FILE:
models_to_use = arguments.get("models_prefixed_by_provider")
responses = prompt_from_file(arguments["abs_file_path"], models_to_use)
# Get the model names that were actually used
models_used = models_to_use if models_to_use else [model.strip() for model in os.environ.get("DEFAULT_MODELS", DEFAULT_MODEL).split(",")]
return [TextContent(
type="text",
text="\n".join([f"Model: {models_used[i]}\nResponse: {resp}"
for i, resp in enumerate(responses)])
)]
elif name == JustPromptTools.PROMPT_FROM_FILE_TO_FILE:
output_dir = arguments.get("abs_output_dir", ".")
models_to_use = arguments.get("models_prefixed_by_provider")
file_paths = prompt_from_file_to_file(
arguments["abs_file_path"],
models_to_use,
output_dir
)
return [TextContent(
type="text",
text=f"Responses saved to:\n" + "\n".join(file_paths)
)]
elif name == JustPromptTools.LIST_PROVIDERS:
providers = list_providers_func()
provider_text = "\nAvailable Providers:\n"
for provider in providers:
provider_text += f"- {provider['name']}: full_name='{provider['full_name']}', short_name='{provider['short_name']}'\n"
return [TextContent(
type="text",
text=provider_text
)]
elif name == JustPromptTools.LIST_MODELS:
models = list_models_func(arguments["provider"])
return [TextContent(
type="text",
text=f"Models for provider '{arguments['provider']}':\n" +
"\n".join([f"- {model}" for model in models])
)]
elif name == JustPromptTools.CEO_AND_BOARD:
file_path = arguments["abs_file_path"]
output_dir = arguments.get("abs_output_dir", ".")
models_to_use = arguments.get("models_prefixed_by_provider")
ceo_model = arguments.get("ceo_model", DEFAULT_CEO_MODEL)
ceo_decision_file = ceo_and_board_prompt(
abs_from_file=file_path,
abs_output_dir=output_dir,
models_prefixed_by_provider=models_to_use,
ceo_model=ceo_model
)
# Get the CEO prompt file path
ceo_prompt_file = str(Path(ceo_decision_file).parent / "ceo_prompt.xml")
return [TextContent(
type="text",
text=f"Board responses and CEO decision saved.\nCEO prompt file: {ceo_prompt_file}\nCEO decision file: {ceo_decision_file}"
)]
else:
return [TextContent(
type="text",
text=f"Unknown tool: {name}"
)]
except Exception as e:
logger.error(f"Error handling tool call: {name}, error: {e}")
return [TextContent(
type="text",
text=f"Error: {str(e)}"
)]
# Initialize and run the server
try:
options = server.create_initialization_options()
async with stdio_server() as (read_stream, write_stream):
await server.run(read_stream, write_stream, options, raise_exceptions=True)
except Exception as e:
logger.error(f"Error running server: {e}")
raise
```
--------------------------------------------------------------------------------
/ai_docs/openai-reasoning-effort.md:
--------------------------------------------------------------------------------
```markdown
# Reasoning models
Explore advanced reasoning and problem-solving models.
**Reasoning models** like o3 and o4-mini are LLMs trained with reinforcement learning to perform reasoning. Reasoning models [think before they answer](https://openai.com/index/introducing-openai-o1-preview/), producing a long internal chain of thought before responding to the user. Reasoning models excel in complex problem solving, coding, scientific reasoning, and multi-step planning for agentic workflows. They're also the best models for [Codex CLI](https://github.com/openai/codex), our lightweight coding agent.
As with our GPT series, we provide smaller, faster models ( `o4-mini` and `o3-mini`) that are less expensive per token. The larger models ( `o3` and `o1`) are slower and more expensive but often generate better responses for complex tasks and broad domains.
To ensure safe deployment of our latest reasoning models [`o3`](https://platform.openai.com/docs/models/o3) and [`o4-mini`](https://platform.openai.com/docs/models/o4-mini), some developers may need to complete [organization verification](https://help.openai.com/en/articles/10910291-api-organization-verification) before accessing these models. Get started with verification on the [platform settings page](https://platform.openai.com/settings/organization/general).
## Get started with reasoning
Reasoning models can be used through the [Responses API](https://platform.openai.com/docs/api-reference/responses/create) as seen here.
Using a reasoning model in the Responses API
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
Write a bash script that takes a matrix represented as a string with
format '[1,2],[3,4],[5,6]' and prints the transpose in the same format.
`;
const response = await openai.responses.create({
model: "o4-mini",
reasoning: { effort: "medium" },
input: [
{
role: "user",
content: prompt,
},
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
prompt = """
Write a bash script that takes a matrix represented as a string with
format '[1,2],[3,4],[5,6]' and prints the transpose in the same format.
"""
response = client.responses.create(
model="o4-mini",
reasoning={"effort": "high"},
input=[
{
"role": "user",
"content": prompt
}
]
)
print(response.output_text)
```
```bash
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o4-mini",
"reasoning": {"effort": "medium"},
"input": [
{
"role": "user",
"content": "Write a bash script that takes a matrix represented as a string with format \"[1,2],[3,4],[5,6]\" and prints the transpose in the same format."
}
]
}'
```
In the example above, the `reasoning.effort` parameter guides the model on how many reasoning tokens to generate before creating a response to the prompt.
Specify `low`, `medium`, or `high` for this parameter, where `low` favors speed and economical token usage, and `high` favors more complete reasoning. The default value is `medium`, which is a balance between speed and reasoning accuracy.
## How reasoning works
Reasoning models introduce **reasoning tokens** in addition to input and output tokens. The models use these reasoning tokens to "think," breaking down the prompt and considering multiple approaches to generating a response. After generating reasoning tokens, the model produces an answer as visible completion tokens and discards the reasoning tokens from its context.
Here is an example of a multi-step conversation between a user and an assistant. Input and output tokens from each step are carried over, while reasoning tokens are discarded.
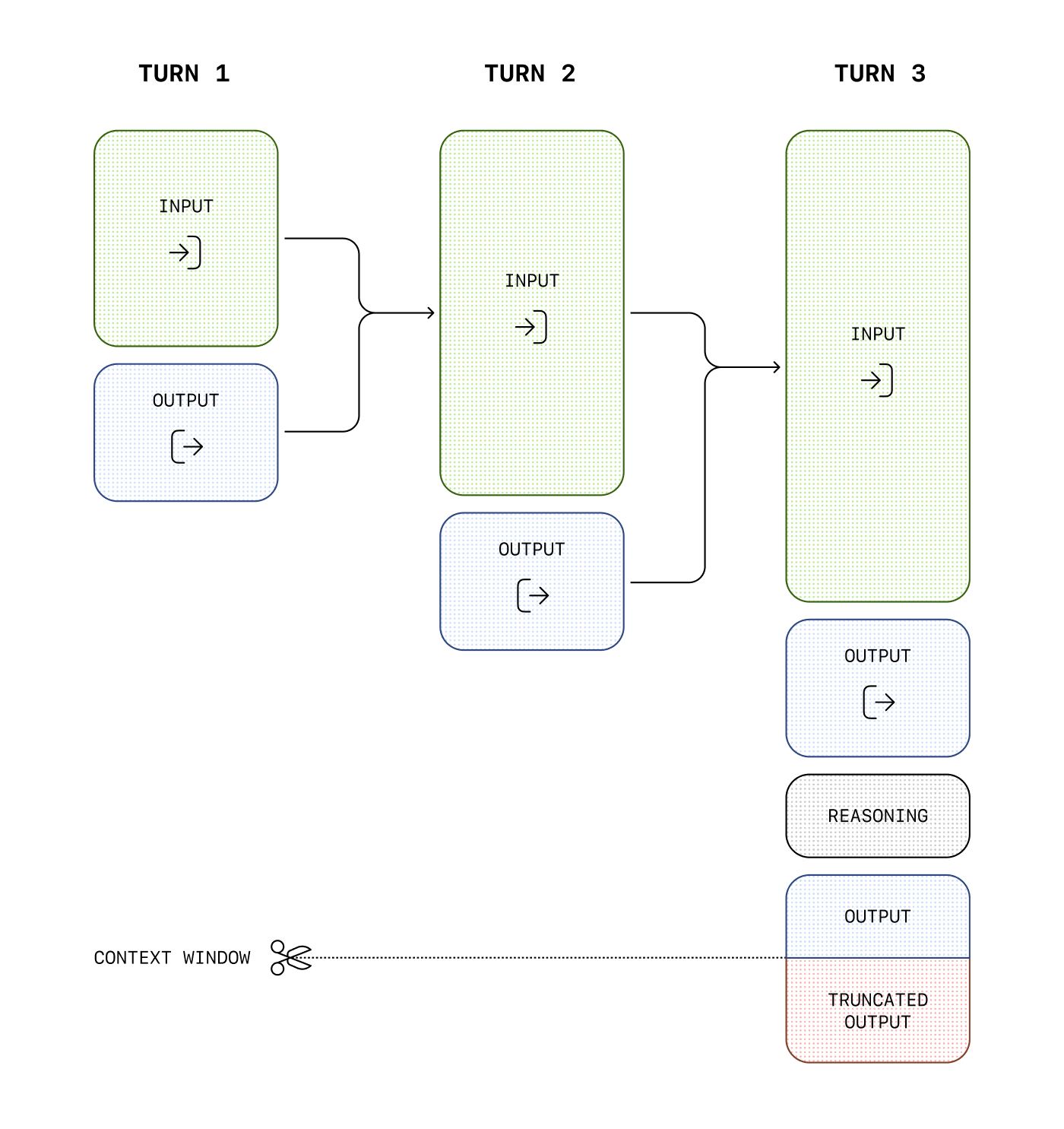
While reasoning tokens are not visible via the API, they still occupy space in the model's context window and are billed as [output tokens](https://openai.com/api/pricing).
### Managing the context window
It's important to ensure there's enough space in the context window for reasoning tokens when creating responses. Depending on the problem's complexity, the models may generate anywhere from a few hundred to tens of thousands of reasoning tokens. The exact number of reasoning tokens used is visible in the [usage object of the response object](https://platform.openai.com/docs/api-reference/responses/object), under `output_tokens_details`:
```json
{
"usage": {
"input_tokens": 75,
"input_tokens_details": {
"cached_tokens": 0
},
"output_tokens": 1186,
"output_tokens_details": {
"reasoning_tokens": 1024
},
"total_tokens": 1261
}
}
```
Context window lengths are found on the [model reference page](https://platform.openai.com/docs/models), and will differ across model snapshots.
### Controlling costs
If you're managing context manually across model turns, you can discard older reasoning items _unless_ you're responding to a function call, in which case you must include all reasoning items between the function call and the last user message.
To manage costs with reasoning models, you can limit the total number of tokens the model generates (including both reasoning and final output tokens) by using the [`max_output_tokens`](https://platform.openai.com/docs/api-reference/responses/create#responses-create-max_output_tokens) parameter.
### Allocating space for reasoning
If the generated tokens reach the context window limit or the `max_output_tokens` value you've set, you'll receive a response with a `status` of `incomplete` and `incomplete_details` with `reason` set to `max_output_tokens`. This might occur before any visible output tokens are produced, meaning you could incur costs for input and reasoning tokens without receiving a visible response.
To prevent this, ensure there's sufficient space in the context window or adjust the `max_output_tokens` value to a higher number. OpenAI recommends reserving at least 25,000 tokens for reasoning and outputs when you start experimenting with these models. As you become familiar with the number of reasoning tokens your prompts require, you can adjust this buffer accordingly.
Handling incomplete responses
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
Write a bash script that takes a matrix represented as a string with
format '[1,2],[3,4],[5,6]' and prints the transpose in the same format.
`;
const response = await openai.responses.create({
model: "o4-mini",
reasoning: { effort: "medium" },
input: [
{
role: "user",
content: prompt,
},
],
max_output_tokens: 300,
});
if (
response.status === "incomplete" &&
response.incomplete_details.reason === "max_output_tokens"
) {
console.log("Ran out of tokens");
if (response.output_text?.length > 0) {
console.log("Partial output:", response.output_text);
} else {
console.log("Ran out of tokens during reasoning");
}
}
```
```python
from openai import OpenAI
client = OpenAI()
prompt = """
Write a bash script that takes a matrix represented as a string with
format '[1,2],[3,4],[5,6]' and prints the transpose in the same format.
"""
response = client.responses.create(
model="o4-mini",
reasoning={"effort": "medium"},
input=[
{
"role": "user",
"content": prompt
}
],
max_output_tokens=300,
)
if response.status == "incomplete" and response.incomplete_details.reason == "max_output_tokens":
print("Ran out of tokens")
if response.output_text:
print("Partial output:", response.output_text)
else:
print("Ran out of tokens during reasoning")
```
### Keeping reasoning items in context
When doing [function calling](https://platform.openai.com/docs/guides/function-calling) with a reasoning model in the [Responses API](https://platform.openai.com/docs/apit-reference/responses), we highly recommend you pass back any reasoning items returned with the last function call (in addition to the output of your function). If the model calls multiple functions consecutively, you should pass back all reasoning items, function call items, and function call output items, since the last `user` message. This allows the model to continue its reasoning process to produce better results in the most token-efficient manner.
The simplest way to do this is to pass in all reasoning items from a previous response into the next one. Our systems will smartly ignore any reasoning items that aren't relevant to your functions, and only retain those in context that are relevant. You can pass reasoning items from previous responses either using the `previous_response_id` parameter, or by manually passing in all the [output](https://platform.openai.com/docs/api-reference/responses/object#responses/object-output) items from a past response into the [input](https://platform.openai.com/docs/api-reference/responses/create#responses-create-input) of a new one.
For advanced use-cases where you might be truncating and optimizing parts of the context window before passing them on to the next response, just ensure all items between the last user message and your function call output are passed into the next response untouched. This will ensure that the model has all the context it needs.
Check out [this guide](https://platform.openai.com/docs/guides/conversation-state) to learn more about manual context management.
## Reasoning summaries
While we don't expose the raw reasoning tokens emitted by the model, you can view a summary of the model's reasoning using the the `summary` parameter.
Different models support different reasoning summarizers—for example, our computer use model supports the `concise` summarizer, while o4-mini supports `detailed`. To simply access the most detailed summarizer available, set the value of this parameter to `auto` and view the reasoning summary as part of the `summary` array in the `reasoning` [output](https://platform.openai.com/docs/api-reference/responses/object#responses/object-output) item.
This feature is also supported with streaming, and across the following reasoning models: `o4-mini`, `o3`, `o3-mini` and `o1`.
Before using summarizers with our latest reasoning models, you may need to complete [organization verification](https://help.openai.com/en/articles/10910291-api-organization-verification) to ensure safe deployment. Get started with verification on the [platform settings page](https://platform.openai.com/settings/organization/general).
Generate a summary of the reasoning
```json
reasoning: {
effort: "medium", // unchanged
summary: "auto" // auto gives you the best available summary (detailed > auto > None)
}
```
## Advice on prompting
There are some differences to consider when prompting a reasoning model. Reasoning models provide better results on tasks with only high-level guidance, while GPT models often benefit from very precise instructions.
- A reasoning model is like a senior co-worker—you can give them a goal to achieve and trust them to work out the details.
- A GPT model is like a junior coworker—they'll perform best with explicit instructions to create a specific output.
For more information on best practices when using reasoning models, [refer to this guide](https://platform.openai.com/docs/guides/reasoning-best-practices).
### Prompt examples
#### Coding (refactoring)
OpenAI o-series models are able to implement complex algorithms and produce code. This prompt asks o1 to refactor a React component based on some specific criteria.
Refactor code
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
Instructions:
- Given the React component below, change it so that nonfiction books have red
text.
- Return only the code in your reply
- Do not include any additional formatting, such as markdown code blocks
- For formatting, use four space tabs, and do not allow any lines of code to
exceed 80 columns
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
`.trim();
const response = await openai.responses.create({
model: "o4-mini",
input: [
{
role: "user",
content: prompt,
},
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
prompt = """
Instructions:
- Given the React component below, change it so that nonfiction books have red
text.
- Return only the code in your reply
- Do not include any additional formatting, such as markdown code blocks
- For formatting, use four space tabs, and do not allow any lines of code to
exceed 80 columns
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.responses.create(
model="o4-mini",
input=[
{
"role": "user",
"content": prompt,
}
]
)
print(response.output_text)
```
#### Coding (planning)
OpenAI o-series models are also adept in creating multi-step plans. This example prompt asks o1 to create a filesystem structure for a full solution, along with Python code that implements the desired use case.
Plan and create a Python project
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
I want to build a Python app that takes user questions and looks
them up in a database where they are mapped to answers. If there
is close match, it retrieves the matched answer. If there isn't,
it asks the user to provide an answer and stores the
question/answer pair in the database. Make a plan for the directory
structure you'll need, then return each file in full. Only supply
your reasoning at the beginning and end, not throughout the code.
`.trim();
const response = await openai.responses.create({
model: "o4-mini",
input: [
{
role: "user",
content: prompt,
},
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
prompt = """
I want to build a Python app that takes user questions and looks
them up in a database where they are mapped to answers. If there
is close match, it retrieves the matched answer. If there isn't,
it asks the user to provide an answer and stores the
question/answer pair in the database. Make a plan for the directory
structure you'll need, then return each file in full. Only supply
your reasoning at the beginning and end, not throughout the code.
"""
response = client.responses.create(
model="o4-mini",
input=[
{
"role": "user",
"content": prompt,
}
]
)
print(response.output_text)
```
#### STEM Research
OpenAI o-series models have shown excellent performance in STEM research. Prompts asking for support of basic research tasks should show strong results.
Ask questions related to basic scientific research
```javascript
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
What are three compounds we should consider investigating to
advance research into new antibiotics? Why should we consider
them?
`;
const response = await openai.responses.create({
model: "o4-mini",
input: [
{
role: "user",
content: prompt,
},
],
});
console.log(response.output_text);
```
```python
from openai import OpenAI
client = OpenAI()
prompt = """
What are three compounds we should consider investigating to
advance research into new antibiotics? Why should we consider
them?
"""
response = client.responses.create(
model="o4-mini",
input=[
{
"role": "user",
"content": prompt
}
]
)
print(response.output_text)
```
## Use case examples
Some examples of using reasoning models for real-world use cases can be found in [the cookbook](https://cookbook.openai.com/).
[Using reasoning for data validation](https://cookbook.openai.com/examples/o1/using_reasoning_for_data_validation)
[Evaluate a synthetic medical data set for discrepancies.](https://cookbook.openai.com/examples/o1/using_reasoning_for_data_validation)
[Using reasoning for routine generation](https://cookbook.openai.com/examples/o1/using_reasoning_for_routine_generation)
[Use help center articles to generate actions that an agent could perform.](https://cookbook.openai.com/examples/o1/using_reasoning_for_routine_generation)
```
--------------------------------------------------------------------------------
/example_outputs/decision_openai_vs_anthropic_vs_google/ceo_prompt.xml:
--------------------------------------------------------------------------------
```
<purpose>
You are a CEO of a company. You are given a list of responses from your board of directors. Your job is to take in the original question prompt, and each of the board members' responses, and choose the best direction for your company.
</purpose>
<instructions>
<instruction>Each board member has proposed an answer to the question posed in the prompt.</instruction>
<instruction>Given the original question prompt, and each of the board members' responses, choose the best answer.</instruction>
<instruction>Tally the votes of the board members, choose the best direction, and explain why you chose it.</instruction>
<instruction>To preserve anonymity, we will use model names instead of real names of your board members. When responding, use the model names in your response.</instruction>
<instruction>As a CEO, you breakdown the decision into several categories including: risk, reward, timeline, and resources. In addition to these guiding categories, you also consider the board members' expertise and experience. As a bleeding edge CEO, you also invent new dimensions of decision making to help you make the best decision for your company.</instruction>
<instruction>Your final CEO response should be in markdown format with a comprehensive explanation of your decision. Start the top of the file with a title that says "CEO Decision", include a table of contents, briefly describe the question/problem at hand then dive into several sections. One of your first sections should be a quick summary of your decision, then breakdown each of the boards decisions into sections with your commentary on each. Where we lead into your decision with the categories of your decision making process, and then we lead into your final decision.</instruction>
</instructions>
<original-question><purpose>
I'm going to bet massive amounts of time, money, and resources on one of the big three generative ai companies: OpenAI, Anthropic, or Google.
Help me decide which one to bet on based on everything you know about the companies. Here are are top 3 factors I'm considering:
</purpose>
<factors>
1. Model Performance (Raw Intelligence)
2. Model Tool Use (Ability to use tools)
3. Model Cost (Cost of the model)
</factors>
<decision-resources>
## 1. OpenAI
### Models & Research Pipeline
| Tier | Latest model (public) | Notable strengths | Notes |
|---|---|---|---|
| Frontier | **o3** (Apr 16 2025) | Native tool‑use API, rich vision‐reasoning, ~8× cheaper inference than GPT‑4‑Turbo | First of the “reasoning‑optimized” O‑series citeturn0search0|
| Flagship | **GPT‑4o / 4o‑mini** (Mar 25 2025) | Unified text‑image model; real‑time image generation | 4o‑mini is a low‑cost sibling targeting edge devices citeturn0search1|
| Established | GPT‑4‑Turbo, GPT‑3.5‑Turbo, DALL·E 3, Whisper‑v3 | Commodity‑priced large‑context chat, embeddings, speech | Ongoing price drops every quarter |
### Signature Products
- **ChatGPT (Free, Plus, Enterprise, Edu)** – 180 M+ MAU, now defaults to GPT‑4o.
- **Assistants & Tools API** – agent‑style orchestration layer exposed to devs (beta since Dec 2024). citeturn3search0turn3search3
- **Custom GPTs & Store** – closed marketplace with rev‑share for creators.
### Developer & Infra Stack
Azure super‑clusters (co‑designed with Microsoft), retrieval & vector store primitives, universal function‑calling schema, streaming Vision API.
### People & Org
- ~**3,531 employees** (tripled YoY). citeturn0search6
- CEO : Sam Altman; CTO : Mira Murati; Chief Scientist : Ilya Sutskever (now heads “Superalignment”).
- **Microsoft** multiyear, multibillion $ partnership guarantees exclusive Azure capacity. citeturn1search10
- Latest secondary share sale pegs **valuation ≈ $80–90 B**. citeturn2search2
#### Pros
1. Highest benchmark scores and feature cadence (tool use, multimodal, assistants).
2. Deep Azure subsidised compute & enterprise sales machine via Microsoft.
3. Huge independent researcher pool; culture of iterative price cuts.
#### Cons
1. Governance drama in 2023 still haunts investors; nonprofit‑for‑profit cap table is complex.
2. Closed‑source; customers fully dependent on Azure + proprietary stack.
3. Price premium at the very top end remains high vs Claude/Gemini mid‑tiers.
---
## 2. Anthropic
### Models & Research Pipeline
| Tier | Latest model | Notable strengths | Notes |
|---|---|---|---|
| Frontier | **Claude 3.5 Sonnet** (Apr 9 2025) | Outperforms Claude 3 Opus; 2× speed; 8 k‑8 k context* | *8,192‑token output cap citeturn0search2|
| Flagship (large) | Claude 3 Opus (Jan 2024) | Long‑form reasoning, 200 k context |
| Mid‑tier | Claude 3 Haiku (cheap), Claude Instant | Cost‑efficient chat & embedding |
### Signature Products
- **Claude.ai** web app, Slack plugin, soon Microsoft Teams plugin.
- **Workspaces** – org‑level spend limits, RBAC & key grouping in the console. citeturn3search1
### Developer & Infra Stack
- Fully served on **AWS Trainium/Inferentia**; Amazon is “primary cloud partner”. citeturn1search0turn1search4
- Elegant tool‑use schema (JSON).
- No first‑party vision yet (under active research).
### People & Org
- ~**1,035 employees** (Sep 2024 count). citeturn0search7
- Co‑founders : Dario & Daniela Amodei (ex‑OpenAI).
- Funding: **$8 B total** from Amazon; $2 B from Google, plus Google Cloud credits. citeturn1search9
- Recent private‑round chatter puts **valuation $40‑60 B**. citeturn2search12
#### Pros
1. Best‑in‑class safety research ethos; “Constitutional AI” resonates with regulated industries.
2. Competitive price/perf at Sonnet tier (beats GPT‑4‑Turbo in many tasks).
3. Multi‑cloud backing (AWS + Google) hedges single‑vendor risk.
#### Cons
1. Smaller compute budget than OpenAI/Google; relies on partners’ chips.
2. Narrower product surface (no vision, no speech, few consumer touch‑points).
3. Valuation/revenue ratio now rivals OpenAI without equivalent distribution.
---
## 3. Google (Alphabet / DeepMind)
### Models & Research Pipeline
| Tier | Latest model | Notable strengths | Notes |
|---|---|---|---|
| Frontier | **Gemini 2.5 Pro** (Mar 26 2025) | Leads math/code benchmarks, native 1 M‑token context, soon 2 M | Via AI Studio + Vertex AI citeturn3search2|
| Flagship | Gemini 1.5 Ultra / Flash (Feb 2024) | High‑context multimodal, efficient streaming | citeturn0search4|
| Open models | **Gemma 3** (Mar 2025) | 2‑7 B “open weight” family; on‑device, permissive licence | citeturn4search0|
### Signature Products
- **Gemini app** (Android/iOS) & Gemini Advanced subscription.
- **Workspace AI** (Docs, Sheets, Meet “Help me…”), new **Workspace Flows** no‑code automation. citeturn0search5
- **Gemini Code Assist** inside VS Code, JetBrains, Android Studio. citeturn3search5
### Developer & Infra Stack
- **AI Studio** (free tier) → **Vertex AI** (pay‑as‑you‑go) with GPU & TPU‑v5p back‑ends.
- Long history of open tooling (TensorFlow, JAX) plus Gemma weights for on‑prem.
### People & Org
- Google DeepMind generative‑AI group ≈ **5,600 employees** (Apr 2025). citeturn0search8
- Backed by Alphabet’s **$2.2 T** market cap and worldwide datacenters. citeturn2search13
- Leadership : Sundar Pichai (CEO), Demis Hassabis (DeepMind CEO).
#### Pros
1. Unmatched global distribution (Android, Chrome, Search, Cloud, YouTube).
2. Deep proprietary silicon (TPU v5p) and vast training corpus.
3. Only top‑tier player shipping **both** closed frontier models *and* open‑weight Gemma family.
#### Cons
1. Ship cadence historically slower; organisational silos (Google Cloud vs DeepMind vs Products).
2. Strategic tension: making Gemini too good could erode core Search ad revenue.
3. Licensing still restrictive for big‑context Gemini (waitlists, region locks).
---
## How to think about a “massive bet”
| Dimension | OpenAI | Anthropic | Google | Quick take |
|---|---|---|---|---|
| **Raw model performance (Q2 2025)** | 🟢 top | 🟢 fast follower | 🟢 at parity on many tasks | All three are competitive; edge cases matter (vision, context length). |
| **Cost‑performance at scale** | 🟠 improving | 🟢 cheapest at Sonnet tier | 🟢 aggressive Vertex discounts | Anthropic & Google currently undercut GPT‑4‑level pricing. |
| **Product distribution** | 🟢 ChatGPT ubiquity | 🟠 limited | 🟢 billions of Workspace users | Google wins on built‑in reach. |
| **Ecosystem / APIs** | 🟢 richest (assistants, tools) | 🟢 clean, safety‑first | 🟢 broad + open weights | Tie — depends on needs. |
| **Compute independence** | 🟠 Azure‑locked | 🟠 AWS‑locked (plus GCP credits) | 🟢 owns TPUs | Google least vendor‑dependent. |
| **Governance / stability** | 🟠 history of board turmoil | 🟢 stable, safety board | 🟠 big‑company bureaucracy | Pick your poison. |
| **Valuation vs revenue** | High (~$90 B) | Very high (~$40‑60 B) | Public mega‑cap | Alphabet safest on dilution risk. |
**Bottom line:**
- **Bet on OpenAI** if you want the bleeding‑edge feature set, the largest third‑party tool ecosystem, and Microsoft‑grade enterprise onboarding.
- **Bet on Anthropic** if alignment, transparency, and cost‑controlled high‑quality text models are critical, and you’re comfortable with AWS reliance.
- **Bet on Google** if you value distribution channels, open‑weight fallback options, and sovereign‑scale compute — and you can tolerate slower release cycles.
Always pilot with a narrowly‑scoped production workload before committing multi‑year spend; pricing, rate limits and leadership roadmaps continue to shift quarter‑by‑quarter in this fast‑moving space.
</decision-resources>
</original-question>
<board-decisions>
<board-response>
<model-name>openai:o3:high</model-name>
<response>────────────────────────────────
EXECUTIVE RECOMMENDATION
────────────────────────────────
If the ONLY three variables that really matter to you are
1. Raw intelligence today and the likelihood of keeping the lead
2. Out‑of‑the‑box tool‑use / agent infrastructure
3. $/token in production at scale
then a weighted decision that puts slightly more emphasis on (1) and (2) than on (3) still lands on
➜ OpenAI (70 % likelihood it remains the best net‑present‑value bet)
provided you are comfortable being locked into Azure and can absorb a ~20 – 40 % price premium on frontier‑tier calls for at least the next 12‑18 months.
However, if your budget envelope is tight AND your workloads are dominated by straight text (no vision, no speech) where 95th‑percentile reasoning quality is “good enough”, Anthropic’s Claude 3.5 Sonnet is the most cost‑efficient sweet spot and lowers execution risk.
Google becomes the asymmetric bet if (a) you operate in the Google Cloud / Workspace ecosystem already, (b) you need sovereign or on‑prem options (Gemma), or (c) you want to ride the mega‑cap balance sheet rather than a venture‑backed start‑up.
────────────────────────────────
1. FACTOR‑BY‑FACTOR DEEP DIVE
────────────────────────────────
FACTOR 1 — Model Performance (Raw Intelligence)
• OpenAI o3 (and GPT‑4o) lead most public evals that include vision, reasoning‑under‑uncertainty and zero‑shot tool‐use.
• Anthropic Claude 3.5 Sonnet/Opus top pure‑text reasoning benchmarks and match/beat GPT‑4‑Turbo on many popular leaderboards, but still lag on multimodal tasks.
• Google Gemini 2.5 Pro wins on giant context (1‑2 M tokens) and coding/math specialist tasks, but its frontier “Ultra” variant is gated and region‑restricted.
FACTOR 2 — Tool Use / Orchestration
• OpenAI’s Assistants & Tools API is the most mature: built‑in function calling, auto‑RAG, file‑level plans, beta agentic retries, hundreds of SDK wrappers.
• Anthropic exposes clean JSON tool‑use with schema‑by‑example, but lacks higher‑order agent features (no planner/executor modules, no retrieval primitives).
• Google’s Vertex AI Agents & Extensions are promising (can invoke Google Search, Gmail, Drive, etc.) but APIs still in preview and less documented.
FACTOR 3 — Cost
(List is for “rough GPT‑4‑equivalent quality, May 2025 price sheets, 1K‑token prompt+completion, on‑demand)
• Claude 3.5 Sonnet —— $3.00 (input $2.00, output $1.00)
• GPT‑4o‑mini —— $3.20
• GPT‑4o (full) —— $5.00
• Gemini 2.5 Pro —— $4.20 (Vertex pay‑as‑you‑go, before sustained‑use discounts)
Fixed commitments, reserved‑capacity and committed‑use discounts can bring all three within 10 – 15 % of each other, but Anthropic retains the consistent low‑cost edge.
────────────────────────────────
2. SIMPLE SCORING MATRIX
────────────────────────────────
Weights chosen: Performance 45 %, Tool‑use 35 %, Cost 20 %
Perf (45) Tools (35) Cost (20) Weighted
OpenAI 9 10 6 8.7
Anthropic 8 7 9 7.7
Google 8 8 7 7.9
(Score 1‑10, higher is better. Sensitivity check: If you up‑weight Cost to 40 %, Anthropic wins; if you up‑weight Context‑length or on‑prem‑friendly, Google can edge ahead.)
────────────────────────────────
3. RISK & STRATEGIC CONSIDERATIONS
────────────────────────────────
Vendor Lock‑in
• OpenAI = Azure only (unless you self‑host smaller open‑weights—which defeats the purpose).
• Anthropic = AWS primary, GCP secondary; less rigid, but still contractual minimums.
• Google = GP/TPU first‑party; Gemma open weights give a credible exit hatch.
Governance / Corporate Stability
• Alphabet is public, transparent, Sarbanes‑Oxley‑level reporting.
• Anthropic has a single‑share “long‑term benefit trust” and a safety board, but Amodei siblings firmly in control.
• OpenAI’s capped‑profit / non‑profit hybrid is unique; last November’s board drama shows governance risk, but Microsoft’s observer seat adds adult supervision.
Capex & Compute Security
• Google owns the fabs and TPUs → least likely to hit supply constraints.
• Microsoft fronts multi‑billion‑dollar Azure clusters for OpenAI; so far, delivery has kept pace.
• Anthropic rents from AWS & GCP; anything longer than 3‑year horizons depends on partners’ roadmap.
────────────────────────────────
4. HOW TO DERISK A “ONE‑HORSE” BET
────────────────────────────────
1. Contract for a three‑year spend floor but keep 20 % budget for a secondary provider.
2. Architect with an abstraction layer (LangChain, Semantic‑Kernel, or your own) so that swapping LLM endpoints is <2 weeks work.
3. Maintain an internal eval harness; run weekly quality/compliance tests across at least two providers.
4. Negotiate an “annual price step‑down clause” tied to hardware cost curves.
────────────────────────────────
BOTTOM‑LINE GUIDANCE BY PROFILE
────────────────────────────────
• You’re building consumer‑facing, vision‑heavy, agentic features, want fastest feature velocity → Bet OpenAI.
• You’re doing enterprise knowledge work with 10‑100× token volume, heavily regulated, cost‑sensitive → Bet Anthropic.
• You need extreme context windows, tight Workspace integration, or sovereign/on‑prem control → Bet Google.
If forced to choose exactly ONE for the next three years, I lean 60/40 in favor of OpenAI for most green‑field, innovation‑led projects—while keeping a migration strategy alive, because in generative AI the “leader” position flips roughly every 12‑18 months.</response>
</board-response>
<board-response>
<model-name>openai:o4-mini:high</model-name>
<response>Here’s a focused comparison of OpenAI, Anthropic and Google along your three axes—Model Performance, Model Tool Use and Model Cost—plus a bottom‑line “which to pick” based on different priorities.
1. Model Performance (Raw Intelligence)
• OpenAI (o3 / GPT‑4o): leads most public benchmarks, best vision‑reasoning, continuous frontier releases.
• Google (Gemini 2.5 Pro): at parity on reasoning & code benchmarks, unrivaled context windows (1M→2M tokens soon).
• Anthropic (Claude 3.5 Sonnet): very strong in free‑form reasoning, matches or beats GPT‑4‑Turbo in text tasks but lags on vision/speech.
2. Model Tool Use (Ability to orchestrate APIs, plug‑ins, agents)
• OpenAI: richest ecosystem—Assistants API with built‑in tool discovery, function‑calls, vision+generation APIs out of the box.
• Anthropic: clean, safety‑centric JSON tool schema; coming tooling ecosystem but fewer first‑party connectors (no vision yet).
• Google: Vertex AI + AI Studio pipelines, good SDKs and open‑weight Gemma for on‑prem, but less mature “agent” layer than OpenAI.
3. Model Cost (Price / Performance at scale)
• Anthropic (Sonnet tier): cheapest per token for GPT‑4‑level quality today.
• Google (Vertex discounts & Gemma open models): aggressive pricing and on‑device options with Gemma 3.
• OpenAI: steadily falling prices, but top‑end O‑series still carries a premium vs Sonnet/Gemini mid‑tiers.
Summary “Bet” Recommendations
• If you care most about **bleeding‑edge capabilities + seamless, production‑ready tool/agent support**, lean into **OpenAI**. You get top scores, the largest third‑party connector ecosystem and Microsoft’s enterprise muscle—at a premium price.
• If **unit economics** (cost‑performance) is your #1 driver and you value a safety‑first alignment ethos, **Anthropic** is the sweet spot. You give up some multimodal/speech features but gain the lowest cost for GPT‑4‑class chat and clean tool integration.
• If you prize **distribution scale, open‑weight fallbacks and full control over compute**, **Google** stands out. You’ll trade a slightly slower release cadence and less “agent magic” for unrivaled throughput (TPUs + 1M+ token contexts), built‑in Workspace/Android reach and on‑prem options.
All three are competitive on raw intelligence. Your choice really comes down to your biggest lever:
– Performance & tooling ⇒ OpenAI
– Cost‑performance & alignment ⇒ Anthropic
– Distribution & compute sovereignty ⇒ Google
Whichever you pick, pilot a real workload (with rate limits, enterprise features, support SLAs) before you commit multi‑year spend. This space is evolving so rapidly that today’s “win” can shift next quarter.</response>
</board-response>
<board-response>
<model-name>anthropic:claude-3-7-sonnet-20250219:4k</model-name>
<response># Comparing OpenAI, Anthropic, and Google for Your Major Investment
Based on your three key factors, I'll help you evaluate which AI company might best deserve your significant investment of time, money, and resources.
## Factor 1: Model Performance (Raw Intelligence)
**OpenAI**: Currently leads with o3 and GPT-4o models, demonstrating superior reasoning capabilities and consistent top benchmark scores. Their frontier research pipeline maintains a performance edge.
**Anthropic**: Claude 3.5 Sonnet is competitive, with Claude 3 Opus showing excellent long-form reasoning and 200k context window support. While impressive, they typically follow OpenAI's innovations.
**Google**: Gemini 2.5 Pro leads specifically in math and code benchmarks with native 1M token context (soon 2M). Their models excel in certain specialized domains but lack OpenAI's consistent lead across all dimensions.
**Edge**: OpenAI, though the gap has narrowed considerably in 2025.
## Factor 2: Model Tool Use
**OpenAI**: Most mature with native tool-use API, Assistants & Tools API for agent orchestration, and a universal function-calling schema. Their ecosystem encourages extensive third-party integration.
**Anthropic**: Has an elegant JSON-based tool-use schema but lacks first-party vision capabilities. Their approach is solid but more limited in scope.
**Google**: Good tool integration within their ecosystem, particularly with Workspace AI and Workspace Flows. They offer a blend of closed models and open weights (Gemma), providing flexibility.
**Edge**: OpenAI has the richest tool ecosystem and integration capabilities.
## Factor 3: Model Cost
**OpenAI**: Historically premium-priced, though they've implemented consistent quarterly price drops. GPT-4o is roughly 8× cheaper than previous generation models.
**Anthropic**: Offers the most cost-effective options at the Sonnet tier, undercutting GPT-4-Turbo in many cases. Their mid-tier models (Claude 3 Haiku) are explicitly designed for cost efficiency.
**Google**: Provides aggressive Vertex AI discounts and offers Gemma as open-weight models for on-premises deployment, potentially reducing costs for certain use cases.
**Edge**: Anthropic for pure API cost efficiency, with Google offering compelling total cost of ownership advantages.
## Overall Assessment
If you're prioritizing raw intelligence and cutting-edge capabilities, **OpenAI** would be your bet, though you'll pay a premium.
If cost-efficiency with very competitive performance is your priority, **Anthropic** offers the best value, especially with Claude 3.5 Sonnet.
If you need deep integration with existing productivity tools, desire open-weight options, or want the backing of the most financially stable company, **Google** is your best choice.
## Recommendation
Based on your three factors weighted equally, I would recommend **Anthropic** as your primary bet, as they offer the best balance of performance and cost, while maintaining competitive tool use capabilities. Their Constitutional AI approach also suggests a more stable and responsible trajectory.
However, if raw performance and extensive tool integration outweigh cost considerations for your specific needs, OpenAI would be the better choice despite the higher costs.</response>
</board-response>
<board-response>
<model-name>gemini:gemini-2.5-pro-preview-03-25</model-name>
<response>Okay, let's break down this massive decision based *strictly* on the information provided and your three key factors: Model Performance (Raw Intelligence), Model Tool Use, and Model Cost.
**Analysis based on your factors:**
1. **Model Performance (Raw Intelligence):**
* **OpenAI:** Holds the edge with the "highest benchmark scores" noted in its pros. The new `o3` model is specifically "reasoning-optimized," and `GPT-4o` offers strong unified text-image capabilities. They consistently push the frontier.
* **Anthropic:** `Claude 3.5 Sonnet` is a strong contender, explicitly noted as outperforming their previous top model (Opus) and beating `GPT-4-Turbo` in many tasks. However, the lack of "first-party vision yet" is a gap compared to OpenAI and Google's multimodal capabilities mentioned.
* **Google:** `Gemini 2.5 Pro` leads specific benchmarks (math/code) and offers unparalleled native context length (1M-2M tokens), which is a form of raw capability. `Gemini 1.5` series also offers high-context multimodal performance. The summary table notes parity "on many tasks."
* **Conclusion (Performance):** All three are extremely competitive at the frontier.
* OpenAI likely has a slight edge in *general* benchmark performance and multimodal reasoning (vision).
* Google excels in specific areas like *math/code* and *extreme context length*.
* Anthropic offers very strong *text-based* reasoning, competitive with OpenAI's flagship tiers, but currently lags in native multimodality (vision).
* **Winner (slight edge): OpenAI**, due to perceived overall benchmark leadership and strong multimodal features. Google is very close, especially if context length or specific code/math tasks are paramount.
2. **Model Tool Use (Ability to use tools):**
* **OpenAI:** This seems to be a major focus. `o3` has a "native tool-use API". The "Assistants & Tools API" provides an "agent-style orchestration layer" with a "universal function-calling schema". This suggests a mature, dedicated framework for building applications that use tools.
* **Anthropic:** Possesses an "elegant tool-use schema (JSON)". This implies capability, but the description lacks the emphasis on a dedicated orchestration layer or specific agentic framework seen with OpenAI.
* **Google:** Tool use is integrated into products like `Workspace Flows` (no-code automation) and `Gemini Code Assist`. This shows strong *product-level* integration. While Vertex AI likely supports tool use via API, OpenAI's dedicated "Assistants API" seems more explicitly designed for developers building complex tool-using agents from scratch.
* **Conclusion (Tool Use):**
* OpenAI appears to offer the most *developer-centric, flexible, and mature API framework* specifically for building complex applications involving tool use (Assistants API).
* Google excels at *integrating* tool use into its existing products (Workspace, IDEs).
* Anthropic provides the capability but seems less emphasized as a distinct product/framework layer compared to OpenAI.
* **Winner: OpenAI**, for building sophisticated, custom agentic systems via API. Google wins if the goal is leveraging tool use *within* Google's ecosystem products.
3. **Model Cost (Cost of the model):**
* **OpenAI:** Actively working on cost reduction (`o3` is ~8x cheaper than GPT-4-Turbo, `4o-mini` targets low cost). However, it still carries a "price premium at the very top end," and the summary table rates its cost-performance as "improving" (🟠).
* **Anthropic:** `Claude 3.5 Sonnet` offers double the speed of Opus (implying better efficiency/cost) and is highlighted as the "cheapest at Sonnet tier" (🟢). It explicitly "beats GPT-4-Turbo in many tasks" while being cost-competitive.
* **Google:** `Gemini 1.5 Flash` is noted for efficiency. Vertex AI offers "aggressive discounts" (🟢). AI Studio provides a free tier.
* **Conclusion (Cost):**
* Anthropic and Google are explicitly positioned as having a cost advantage over OpenAI, particularly at the highly capable mid-to-flagship tiers (Sonnet vs. GPT-4 level, Gemini via Vertex discounts).
* OpenAI is getting cheaper but may still be the most expensive for absolute top-tier performance.
* **Winner (Tie): Anthropic & Google**, both offer compelling cost-performance, potentially undercutting OpenAI for similar capability levels below the absolute bleeding edge.
**Decision Framework based *only* on these factors:**
* **Bet on OpenAI IF:**
* Your primary driver is accessing the absolute highest raw intelligence and broadest capabilities (including vision) as soon as they are available.
* You need the most mature and flexible developer API for building complex, custom applications that heavily rely on **tool use / agentic behavior**.
* You can tolerate potentially **higher costs** for top-tier performance, betting that their price cuts will continue aggressively.
* **Bet on Anthropic IF:**
* Your primary driver is achieving an optimal **balance between high performance (especially text reasoning) and cost**. Claude 3.5 Sonnet offers leading performance in its tier at a very competitive price.
* You need solid **tool use** capabilities via a clean API, but perhaps don't require the elaborate orchestration layer of OpenAI's Assistants *yet*.
* Current lack of native vision capabilities is acceptable for your core use cases.
* **Cost-efficiency** at scale for high-quality models is a critical factor.
* **Bet on Google IF:**
* Your performance needs align with their strengths: **math/code reasoning or massive context window** requirements.
* **Cost-performance** is crucial, and you can leverage Vertex AI's aggressive discounts or need a strong free tier (AI Studio).
* Your strategy involves leveraging **tool use integrated within existing ecosystems** (Workspace, IDEs) OR you value their underlying infrastructure strength (TPUs).
* You need a balance of strong performance, good cost, and solid tool integration, potentially without needing OpenAI's most advanced (and possibly complex) Assistants API.
**Recommendation Synthesis:**
Based *purely* on your three factors:
1. **Performance:** OpenAI (slight edge overall), Google (specific strengths).
2. **Tool Use API:** OpenAI (most mature developer framework).
3. **Cost:** Anthropic & Google (better cost-performance).
* If **Tool Use maturity via API** is your *most* critical factor alongside top performance, **OpenAI** is the likely bet, despite the cost premium.
* If **Cost-Performance** is your *most* critical factor for high-quality models, **Anthropic** looks very strong, provided you don't immediately need cutting-edge vision.
* If you need Google's specific performance strengths (context, math/code) or value **integrated tool use** and competitive **cost**, **Google** is the bet.
This is a tight race. Your specific weighting of these three factors will determine the best path. Given the "massive bet" nature, consider which factor represents the biggest *risk* if the chosen provider underperforms.</response>
</board-response>
<board-response>
<model-name>gemini:gemini-2.5-flash-preview-04-17</model-name>
<response>Okay, this is a significant decision requiring careful analysis based on the information provided. Let's break down the three companies based on your stated factors: Model Performance, Model Tool Use, and Model Cost, leveraging the details you've supplied.
**Analysis by Factor**
1. **Model Performance (Raw Intelligence)**
* **OpenAI:** The provided text explicitly states "Highest benchmark scores" and lists "o3" (reasoning-optimized) and "GPT-4o" as the "top" models for Q2 2025. Their strength is presented as being at the bleeding edge of raw capability, vision-reasoning, and rapid iteration.
* **Google:** Gemini 2.5 Pro is described as leading in "math/code benchmarks" and offering unmatched context length (1M+, soon 2M), being "at parity on many tasks" with frontier models. While not claiming *overall* highest benchmarks, it leads in specific, crucial areas (logic, coding, massive context).
* **Anthropic:** Claude 3.5 Sonnet "outperforms Claude 3 Opus" and is a "fast follower". Claude 3 Opus is noted for "Long-form reasoning" and 200k context. They are highly competitive and often beat older flagship models from competitors, excelling particularly in long-form text coherence.
* **Ranking for Performance (Based on text):** This is incredibly close at the frontier. OpenAI claims the "highest benchmark scores" overall, while Google leads in specific critical areas (math/code) and context length, and Anthropic excels in long-form reasoning and is a strong fast follower.
1. **OpenAI / Google (Tie):** Depending on whether you need bleeding-edge *general* benchmarks (OpenAI) or specific strengths like *massive context* and *code/math* (Google), these two are presented as the frontier leaders.
2. **Anthropic:** A very strong "fast follower," competitive on many tasks and potentially best for specific use cases like lengthy, coherent text generation.
2. **Model Tool Use (Ability to use tools)**
* **OpenAI:** The text heavily emphasizes "Native tool-use API," "Assistants & Tools API – agent-style orchestration layer," and a "universal function-calling schema." The table explicitly calls out "richest (assistants, tools)" ecosystem. This is presented as a core strength and dedicated focus.
* **Anthropic:** Mentions an "Elegant tool-use schema (JSON)." The table notes it as "clean, safety-first." This indicates capability but is less detailed or emphasized compared to OpenAI's description of its stack.
* **Google:** The text mentions product features like Workspace AI "Help me..." and Workspace Flows, which *use* AI behind the scenes but aren't strictly about the *model's* API-based tool use. It notes AI Studio/Vertex AI which *do* offer function calling (standard in LLM platforms), but the *description* doesn't position tool use as a core *model or system* advantage in the same way OpenAI's "Assistants" framework is highlighted.
* **Ranking for Tool Use (Based on text):** OpenAI is presented as the clear leader with a dedicated system (Assistants) and explicit focus on tool-use APIs.
1. **OpenAI:** Most mature and feature-rich dedicated tool-use/agent framework described.
2. **Anthropic:** Has a noted schema, indicating capability.
3. **Google:** Has underlying platform capability (Vertex AI) and integrated product features, but the provided text doesn't highlight the *model's* tool use API capabilities as a key differentiator like OpenAI does.
3. **Model Cost (Cost of the model)**
* **OpenAI:** Notes "Ongoing price drops every quarter," cheaper models like 4o-mini and o3 (~8x cheaper inference than GPT-4-Turbo). However, the table also states "Price premium at the very top end remains high." They are getting more competitive but aren't presented as the cheapest at the highest tiers.
* **Anthropic:** Claude 3 Haiku is "cheap," and Claude 3.5 Sonnet offers "Competitive price/perf," explicitly stating it "beats GPT-4-Turbo in many tasks" and the table calls it "cheapest at Sonnet tier." This suggests a strong price advantage at a highly capable tier.
* **Google:** Notes "aggressive Vertex discounts" and a free tier (AI Studio). The table confirms "🟢 aggressive Vertex discounts." This indicates they are pricing competitively, especially at scale via their cloud platform.
* **Ranking for Cost (Based on text):** Anthropic and Google are presented as offering better cost-efficiency, either through specific model tiers or platform pricing.
1. **Anthropic / Google (Tie):** Anthropic seems to have a strong claim on price/perf at a specific high-value tier (Sonnet), while Google offers aggressive discounts via its platform, making both potentially more cost-effective than OpenAI's top models.
2. **OpenAI:** Improving, but still has a premium at the highest-performance end.
**Synthesized Recommendation Based on Your Factors**
Based *solely* on the information provided and weighting your three factors:
* If **Model Performance** and **Model Tool Use** are the absolute highest priorities, even at a higher cost, then **OpenAI** appears to be the strongest contender based on the provided text. It's presented as the leader in overall benchmarks and has the most developed tool-use/agent ecosystem.
* If **Model Performance** (especially context length, math/code) and **Model Cost** via enterprise discounts are the highest priorities, and you value owning the infrastructure stack (TPUs) and vast existing distribution channels, then **Google** is a very strong option. It matches OpenAI on frontier performance in key areas and is positioned as more cost-effective and less vendor-locked (vs Azure/AWS).
* If **Model Cost-Performance** (specifically at a high-quality tier like Sonnet) and **Performance** (strong long-form reasoning, competitive benchmarks) are paramount, and you prioritize safety/alignment principles ("Constitutional AI"), then **Anthropic** is the strongest candidate. You sacrifice some tool-use maturity (compared to OpenAI) and breadth (no vision), but gain significant cost efficiency and a strong safety story.
**Considering the "Massive Bet" Context**
A "massive bet" implies long-term commitment, integration depth, and reliance on the partner's stability and roadmap. While not your primary factors, the "How to think about a 'massive bet'" section provides crucial context:
* **Ecosystem/APIs:** OpenAI is called "richest," Google is "broad + open weights." This reinforces OpenAI's lead in developer tools (Assistants) but highlights Google's unique offering of open models.
* **Compute Independence:** Google owns TPUs, reducing reliance on specific cloud vendors (though Vertex AI *is* Google Cloud). OpenAI is tied to Azure, Anthropic to AWS/GCP. Google has an edge here for long-term infra control.
* **Governance/Stability:** OpenAI has a history of turmoil. Anthropic is presented as stable/safety-focused. Google has bureaucracy. This is a risk/preference trade-off. OpenAI's history is a notable risk for a "massive bet."
* **Distribution:** Google is unmatched (billions of users). This is a huge asset if your "bet" involves reaching consumers or leveraging existing enterprise relationships (Workspace).
**Conclusion**
Given your stated factors:
* **OpenAI:** Leads on Tool Use, competitive on Performance, lags on Cost (at the top end). Strong ecosystem, but governance and vendor lock-in are cons for a massive bet.
* **Anthropic:** Leads on Cost-Performance (at Sonnet tier), strong on Performance (fast follower, long context), lags on Tool Use maturity and product surface. Strong safety story, stable governance, but smaller compute/distribution.
* **Google:** Competitive on Performance (context, specific strengths), competitive on Cost (aggressive discounts), decent on Tool Use (via platform). Unmatched distribution, owns infrastructure, offers open models. Cons: potential slower cadence, bureaucracy, Search conflict of interest.
If I had to pick ONE based on balancing your three factors and the "massive bet" context from the text:
* If **Tool Use / Agentic capabilities** are the absolute most critical and you need the most advanced features *right now*, lean towards **OpenAI**, acknowledging the cost premium and governance risks.
* If **massive context, cost efficiency at scale, infrastructure control, and leveraging existing enterprise/consumer distribution** are key, lean towards **Google**. They are highly competitive on performance and cost, own their stack, and have unparalleled reach.
* If **cost-performance (specifically at a high tier), safety/alignment, and long-form text quality** are paramount, lean towards **Anthropic**, accepting the current narrower scope.
Considering the information implies Google is "at parity on many tasks" with OpenAI on performance and offers competitive cost ("aggressive Vertex discounts"), *and* has advantages in infrastructure and distribution not found at the others, **Google** appears to offer the most balanced profile for a "massive bet" that requires high performance, competitive cost, and infrastructure stability/scale, despite the notes on cadence and bureaucracy. OpenAI is arguably ahead on *dedicated* tool-use features *currently*, but Google's overall platform, infra, and distribution might de-risk a "massive bet" more effectively long-term if performance and cost are competitive.
However, the note about Google's "Ship cadence historically slower" is a direct counterpoint to OpenAI's "feature cadence," which is also crucial for a long-term bet in this fast-moving field.
Ultimately:
* **OpenAI** for current frontier capabilities and the richest agent ecosystem, accepting higher cost and higher risk profile.
* **Google** for long-term scale, infrastructure control, cost competitiveness at scale, and distribution, accepting potentially slower feature evolution.
* **Anthropic** for best cost/performance at a key tier and a strong safety narrative, accepting narrower product scope and reliance on cloud partners.
Based *strictly* on the factors and the resources' presentation of balancing performance, cost, and the "massive bet" context (especially infra/distribution), **Google** seems to present a slightly more robust *platform* for a "massive bet" at scale, assuming their performance continues to be competitive, while **OpenAI** is the choice for bleeding-edge *model/tool* features right now.
As the resource states, piloting is essential before committing multi-year spend.</response>
</board-response>
</board-decisions>
```
--------------------------------------------------------------------------------
/ai_docs/llm_providers_details.xml:
--------------------------------------------------------------------------------
```
This file is a merged representation of a subset of the codebase, containing files not matching ignore patterns, combined into a single document by Repomix.
<file_summary>
This section contains a summary of this file.
<purpose>
This file contains a packed representation of the entire repository's contents.
It is designed to be easily consumable by AI systems for analysis, code review,
or other automated processes.
</purpose>
<file_format>
The content is organized as follows:
1. This summary section
2. Repository information
3. Directory structure
4. Repository files, each consisting of:
- File path as an attribute
- Full contents of the file
</file_format>
<usage_guidelines>
- This file should be treated as read-only. Any changes should be made to the
original repository files, not this packed version.
- When processing this file, use the file path to distinguish
between different files in the repository.
- Be aware that this file may contain sensitive information. Handle it with
the same level of security as you would the original repository.
</usage_guidelines>
<notes>
- Some files may have been excluded based on .gitignore rules and Repomix's configuration
- Binary files are not included in this packed representation. Please refer to the Repository Structure section for a complete list of file paths, including binary files
- Files matching these patterns are excluded: server/modules/exbench_module.py
- Files matching patterns in .gitignore are excluded
- Files matching default ignore patterns are excluded
- Files are sorted by Git change count (files with more changes are at the bottom)
</notes>
<additional_info>
</additional_info>
</file_summary>
<directory_structure>
__init__.py
anthropic_llm.py
data_types.py
deepseek_llm.py
exbench_module.py
execution_evaluators.py
fireworks_llm.py
gemini_llm.py
llm_models.py
ollama_llm.py
openai_llm.py
tools.py
</directory_structure>
<files>
This section contains the contents of the repository's files.
<file path="__init__.py">
# Empty file to make tests a package
</file>
<file path="anthropic_llm.py">
import anthropic
import os
import json
from modules.data_types import ModelAlias, PromptResponse, ToolsAndPrompts
from utils import MAP_MODEL_ALIAS_TO_COST_PER_MILLION_TOKENS, parse_markdown_backticks
from modules.data_types import (
SimpleToolCall,
ToolCallResponse,
BenchPromptResponse,
)
from utils import timeit
from modules.tools import (
anthropic_tools_list,
run_coder_agent,
run_git_agent,
run_docs_agent,
all_tools_list,
)
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Initialize Anthropic client
anthropic_client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
def get_anthropic_cost(model: str, input_tokens: int, output_tokens: int) -> float:
"""
Calculate the cost for Anthropic API usage.
Args:
model: The model name/alias used
input_tokens: Number of input tokens
output_tokens: Number of output tokens
Returns:
float: Total cost in dollars
"""
cost_map = MAP_MODEL_ALIAS_TO_COST_PER_MILLION_TOKENS.get(model)
if not cost_map:
return 0.0
input_cost = (input_tokens / 1_000_000) * cost_map["input"]
output_cost = (output_tokens / 1_000_000) * cost_map["output"]
return round(input_cost + output_cost, 6)
def text_prompt(prompt: str, model: str) -> PromptResponse:
"""
Send a prompt to Anthropic and get a response.
"""
try:
with timeit() as t:
message = anthropic_client.messages.create(
model=model,
max_tokens=2048,
messages=[{"role": "user", "content": prompt}],
)
elapsed_ms = t()
input_tokens = message.usage.input_tokens
output_tokens = message.usage.output_tokens
cost = get_anthropic_cost(model, input_tokens, output_tokens)
return PromptResponse(
response=message.content[0].text,
runTimeMs=elapsed_ms,
inputAndOutputCost=cost,
)
except Exception as e:
print(f"Anthropic error: {str(e)}")
return PromptResponse(
response=f"Error: {str(e)}", runTimeMs=0.0, inputAndOutputCost=0.0
)
def bench_prompt(prompt: str, model: str) -> BenchPromptResponse:
"""
Send a prompt to Anthropic and get detailed benchmarking response.
"""
try:
with timeit() as t:
message = anthropic_client.messages.create(
model=model,
max_tokens=2048,
messages=[{"role": "user", "content": prompt}],
)
elapsed_ms = t()
input_tokens = message.usage.input_tokens
output_tokens = message.usage.output_tokens
cost = get_anthropic_cost(model, input_tokens, output_tokens)
return BenchPromptResponse(
response=message.content[0].text,
tokens_per_second=0.0, # Anthropic doesn't provide this info
provider="anthropic",
total_duration_ms=elapsed_ms,
load_duration_ms=0.0,
inputAndOutputCost=cost,
)
except Exception as e:
print(f"Anthropic error: {str(e)}")
return BenchPromptResponse(
response=f"Error: {str(e)}",
tokens_per_second=0.0,
provider="anthropic",
total_duration_ms=0.0,
load_duration_ms=0.0,
inputAndOutputCost=0.0,
errored=True,
)
def tool_prompt(prompt: str, model: str) -> ToolCallResponse:
"""
Run a chat model with tool calls using Anthropic's Claude.
Now supports JSON structured output variants by parsing the response.
"""
with timeit() as t:
if "-json" in model:
# Standard message request but expecting JSON response
message = anthropic_client.messages.create(
model=model.replace("-json", ""),
max_tokens=2048,
messages=[{"role": "user", "content": prompt}],
)
try:
# Parse raw response text into ToolsAndPrompts model
parsed_response = ToolsAndPrompts.model_validate_json(
parse_markdown_backticks(message.content[0].text)
)
tool_calls = [
SimpleToolCall(
tool_name=tap.tool_name, params={"prompt": tap.prompt}
)
for tap in parsed_response.tools_and_prompts
]
except Exception as e:
print(f"Failed to parse JSON response: {e}")
tool_calls = []
else:
# Original implementation for function calling
message = anthropic_client.messages.create(
model=model,
max_tokens=2048,
messages=[{"role": "user", "content": prompt}],
tools=anthropic_tools_list,
tool_choice={"type": "any"},
)
# Extract tool calls with parameters
tool_calls = []
for content in message.content:
if content.type == "tool_use":
tool_name = content.name
if tool_name in all_tools_list:
tool_calls.append(
SimpleToolCall(tool_name=tool_name, params=content.input)
)
# Calculate cost based on token usage
input_tokens = message.usage.input_tokens
output_tokens = message.usage.output_tokens
cost = get_anthropic_cost(model, input_tokens, output_tokens)
return ToolCallResponse(
tool_calls=tool_calls, runTimeMs=t(), inputAndOutputCost=cost
)
</file>
<file path="data_types.py">
from typing import Optional, Union
from pydantic import BaseModel
from enum import Enum
class ModelAlias(str, Enum):
haiku = "claude-3-5-haiku-latest"
haiku_3_legacy = "claude-3-haiku-20240307"
sonnet = "claude-3-5-sonnet-20241022"
gemini_pro_2 = "gemini-1.5-pro-002"
gemini_flash_2 = "gemini-1.5-flash-002"
gemini_flash_8b = "gemini-1.5-flash-8b-latest"
gpt_4o_mini = "gpt-4o-mini"
gpt_4o = "gpt-4o"
gpt_4o_predictive = "gpt-4o-predictive"
gpt_4o_mini_predictive = "gpt-4o-mini-predictive"
# JSON variants
o1_mini_json = "o1-mini-json"
gpt_4o_json = "gpt-4o-json"
gpt_4o_mini_json = "gpt-4o-mini-json"
gemini_pro_2_json = "gemini-1.5-pro-002-json"
gemini_flash_2_json = "gemini-1.5-flash-002-json"
sonnet_json = "claude-3-5-sonnet-20241022-json"
haiku_json = "claude-3-5-haiku-latest-json"
gemini_exp_1114_json = "gemini-exp-1114-json"
# ollama models
llama3_2_1b = "llama3.2:1b"
llama_3_2_3b = "llama3.2:latest"
qwen_2_5_coder_14b = "qwen2.5-coder:14b"
qwq_3db = "qwq:32b"
phi_4 = "vanilj/Phi-4:latest"
class Prompt(BaseModel):
prompt: str
model: Union[ModelAlias, str]
class ToolEnum(str, Enum):
run_coder_agent = "run_coder_agent"
run_git_agent = "run_git_agent"
run_docs_agent = "run_docs_agent"
class ToolAndPrompt(BaseModel):
tool_name: ToolEnum
prompt: str
class ToolsAndPrompts(BaseModel):
tools_and_prompts: list[ToolAndPrompt]
class PromptWithToolCalls(BaseModel):
prompt: str
model: ModelAlias | str
class PromptResponse(BaseModel):
response: str
runTimeMs: int
inputAndOutputCost: float
class SimpleToolCall(BaseModel):
tool_name: str
params: dict
class ToolCallResponse(BaseModel):
tool_calls: list[SimpleToolCall]
runTimeMs: int
inputAndOutputCost: float
class ThoughtResponse(BaseModel):
thoughts: str
response: str
error: Optional[str] = None
# ------------ Execution Evaluator Benchmarks ------------
class BenchPromptResponse(BaseModel):
response: str
tokens_per_second: float
provider: str
total_duration_ms: float
load_duration_ms: float
inputAndOutputCost: float
errored: Optional[bool] = None
class ModelProvider(str, Enum):
ollama = "ollama"
mlx = "mlx"
class ExeEvalType(str, Enum):
execute_python_code_with_num_output = "execute_python_code_with_num_output"
execute_python_code_with_string_output = "execute_python_code_with_string_output"
raw_string_evaluator = "raw_string_evaluator" # New evaluator type
python_print_execution_with_num_output = "python_print_execution_with_num_output"
json_validator_eval = "json_validator_eval"
class ExeEvalBenchmarkInputRow(BaseModel):
dynamic_variables: Optional[dict]
expectation: str | dict
class ExecEvalBenchmarkFile(BaseModel):
base_prompt: str
evaluator: ExeEvalType
prompts: list[ExeEvalBenchmarkInputRow]
benchmark_name: str
purpose: str
models: list[str] # List of model names/aliases
class ExeEvalBenchmarkOutputResult(BaseModel):
prompt_response: BenchPromptResponse
execution_result: str
expected_result: str
input_prompt: str
model: str
correct: bool
index: int
class ExecEvalBenchmarkCompleteResult(BaseModel):
benchmark_file: ExecEvalBenchmarkFile
results: list[ExeEvalBenchmarkOutputResult]
@property
def correct_count(self) -> int:
return sum(1 for result in self.results if result.correct)
@property
def incorrect_count(self) -> int:
return len(self.results) - self.correct_count
@property
def accuracy(self) -> float:
return self.correct_count / len(self.results)
class ExecEvalBenchmarkModelReport(BaseModel):
model: str # Changed from ModelAlias to str
results: list[ExeEvalBenchmarkOutputResult]
correct_count: int
incorrect_count: int
accuracy: float
average_tokens_per_second: float
average_total_duration_ms: float
average_load_duration_ms: float
total_cost: float
class ExecEvalPromptIteration(BaseModel):
dynamic_variables: dict
expectation: str | dict
class ExecEvalBenchmarkReport(BaseModel):
benchmark_name: str
purpose: str
base_prompt: str
prompt_iterations: list[ExecEvalPromptIteration]
models: list[ExecEvalBenchmarkModelReport]
overall_correct_count: int
overall_incorrect_count: int
overall_accuracy: float
average_tokens_per_second: float
average_total_duration_ms: float
average_load_duration_ms: float
</file>
<file path="deepseek_llm.py">
from openai import OpenAI
from utils import MAP_MODEL_ALIAS_TO_COST_PER_MILLION_TOKENS, timeit
from modules.data_types import BenchPromptResponse, PromptResponse, ThoughtResponse
import os
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Initialize DeepSeek client
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com"
)
def get_deepseek_cost(model: str, input_tokens: int, output_tokens: int) -> float:
"""
Calculate the cost for Gemini API usage.
Args:
model: The model name/alias used
input_tokens: Number of input tokens
output_tokens: Number of output tokens
Returns:
float: Total cost in dollars
"""
cost_map = MAP_MODEL_ALIAS_TO_COST_PER_MILLION_TOKENS.get(model)
if not cost_map:
return 0.0
input_cost = (input_tokens / 1_000_000) * cost_map["input"]
output_cost = (output_tokens / 1_000_000) * cost_map["output"]
return round(input_cost + output_cost, 6)
def bench_prompt(prompt: str, model: str) -> BenchPromptResponse:
"""
Send a prompt to DeepSeek and get detailed benchmarking response.
"""
try:
with timeit() as t:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
stream=False,
)
elapsed_ms = t()
input_tokens = response.usage.prompt_tokens
output_tokens = response.usage.completion_tokens
cost = get_deepseek_cost(model, input_tokens, output_tokens)
return BenchPromptResponse(
response=response.choices[0].message.content,
tokens_per_second=0.0, # DeepSeek doesn't provide this info
provider="deepseek",
total_duration_ms=elapsed_ms,
load_duration_ms=0.0,
inputAndOutputCost=cost,
)
except Exception as e:
print(f"DeepSeek error: {str(e)}")
return BenchPromptResponse(
response=f"Error: {str(e)}",
tokens_per_second=0.0,
provider="deepseek",
total_duration_ms=0.0,
load_duration_ms=0.0,
errored=True,
)
def text_prompt(prompt: str, model: str) -> PromptResponse:
"""
Send a prompt to DeepSeek and get the response.
"""
try:
with timeit() as t:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
stream=False,
)
elapsed_ms = t()
input_tokens = response.usage.prompt_tokens
output_tokens = response.usage.completion_tokens
cost = get_deepseek_cost(model, input_tokens, output_tokens)
return PromptResponse(
response=response.choices[0].message.content,
runTimeMs=elapsed_ms,
inputAndOutputCost=cost,
)
except Exception as e:
print(f"DeepSeek error: {str(e)}")
return PromptResponse(
response=f"Error: {str(e)}",
runTimeMs=0.0,
inputAndOutputCost=0.0,
)
def thought_prompt(prompt: str, model: str) -> ThoughtResponse:
"""
Send a thought prompt to DeepSeek and parse structured response.
"""
try:
# Validate model
if model != "deepseek-reasoner":
raise ValueError(f"Invalid model for thought prompts: {model}. Must use 'deepseek-reasoner'")
# Make API call with reasoning_content=True
with timeit() as t:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
extra_body={"reasoning_content": True}, # Enable structured reasoning
stream=False,
)
elapsed_ms = t()
# Extract content and reasoning
message = response.choices[0].message
thoughts = getattr(message, "reasoning_content", "")
response_content = message.content
# Validate required fields
if not thoughts or not response_content:
raise ValueError("Missing thoughts or response in API response")
# Calculate costs
input_tokens = response.usage.prompt_tokens
output_tokens = response.usage.completion_tokens
cost = get_deepseek_cost("deepseek-reasoner", input_tokens, output_tokens)
return ThoughtResponse(
thoughts=thoughts,
response=response_content,
error=None,
)
except Exception as e:
print(f"DeepSeek thought error: {str(e)}")
return ThoughtResponse(
thoughts=f"Error processing request: {str(e)}",
response="",
error=str(e)
)
</file>
<file path="exbench_module.py">
# ------------------------- Imports -------------------------
from typing import List, Optional
from datetime import datetime
from pathlib import Path
import time
from concurrent.futures import ThreadPoolExecutor
from modules.data_types import (
ExecEvalBenchmarkFile,
ExecEvalBenchmarkCompleteResult,
ExeEvalBenchmarkOutputResult,
ExecEvalBenchmarkModelReport,
ExecEvalBenchmarkReport,
ExecEvalPromptIteration,
ModelAlias,
ExeEvalType,
ModelProvider,
BenchPromptResponse,
)
from modules.ollama_llm import bench_prompt
from modules.execution_evaluators import (
execute_python_code,
eval_result_compare,
)
from utils import parse_markdown_backticks
from modules import (
ollama_llm,
anthropic_llm,
deepseek_llm,
gemini_llm,
openai_llm,
fireworks_llm,
)
provider_delimiter = "~"
def parse_model_string(model: str) -> tuple[str, str]:
"""
Parse model string into provider and model name.
Format: "provider:model_name" or "model_name" (defaults to ollama)
Raises:
ValueError: If provider is not supported
"""
if provider_delimiter not in model:
# Default to ollama if no provider specified
return "ollama", model
provider, *model_parts = model.split(provider_delimiter)
model_name = provider_delimiter.join(model_parts)
# Validate provider
supported_providers = [
"ollama",
"anthropic",
"deepseek",
"openai",
"gemini",
"fireworks",
# "mlx",
# "groq",
]
if provider not in supported_providers:
raise ValueError(
f"Unsupported provider: {provider}. "
f"Supported providers are: {', '.join(supported_providers)}"
)
return provider, model_name
# ------------------------- File Operations -------------------------
def save_report_to_file(
report: ExecEvalBenchmarkReport, output_dir: str = "reports"
) -> str:
"""Save benchmark report to file with standardized naming.
Args:
report: The benchmark report to save
output_dir: Directory to save the report in
Returns:
Path to the saved report file
"""
# Create output directory if it doesn't exist
Path(output_dir).mkdir(exist_ok=True)
# Generate filename
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
safe_benchmark_name = report.benchmark_name.replace(" ", "_")
report_filename = f"{output_dir}/{safe_benchmark_name}_{timestamp}.json"
# Save report
with open(report_filename, "w") as f:
f.write(report.model_dump_json(indent=4))
return report_filename
# ------------------------- Benchmark Execution -------------------------
provider_bench_functions = {
"ollama": ollama_llm.bench_prompt,
"anthropic": anthropic_llm.bench_prompt,
"deepseek": deepseek_llm.bench_prompt,
"openai": openai_llm.bench_prompt,
"gemini": gemini_llm.bench_prompt,
"fireworks": fireworks_llm.bench_prompt,
}
def process_single_prompt(
prompt_row, benchmark_file, provider, model_name, index, total_tests
):
print(f" Running test {index}/{total_tests}...")
prompt = benchmark_file.base_prompt
if prompt_row.dynamic_variables:
for key, value in prompt_row.dynamic_variables.items():
prompt = prompt.replace(f"{{{{{key}}}}}", str(value))
bench_response = None
max_retries = 3
delay = 1
for attempt in range(max_retries + 1):
try:
bench_response = provider_bench_functions[provider](prompt, model_name)
break
except Exception as e:
if attempt < max_retries:
print(f"Retry {attempt+1} for test {index} due to error: {str(e)}")
time.sleep(delay * (attempt + 1))
else:
print(f"All retries failed for test {index}")
bench_response = BenchPromptResponse(
response=f"Error: {str(e)}",
tokens_per_second=0.0,
provider=provider,
total_duration_ms=0.0,
load_duration_ms=0.0,
errored=True,
)
backtick_parsed_response = parse_markdown_backticks(bench_response.response)
execution_result = ""
expected_result = str(prompt_row.expectation).strip()
correct = False
try:
if benchmark_file.evaluator == ExeEvalType.execute_python_code_with_num_output:
execution_result = execute_python_code(backtick_parsed_response)
parsed_execution_result = str(execution_result).strip()
correct = eval_result_compare(
benchmark_file.evaluator, expected_result, parsed_execution_result
)
elif (
benchmark_file.evaluator
== ExeEvalType.execute_python_code_with_string_output
):
execution_result = execute_python_code(backtick_parsed_response)
correct = eval_result_compare(
benchmark_file.evaluator, expected_result, execution_result
)
elif benchmark_file.evaluator == ExeEvalType.raw_string_evaluator:
execution_result = backtick_parsed_response
correct = eval_result_compare(
benchmark_file.evaluator, expected_result, execution_result
)
elif benchmark_file.evaluator == "json_validator_eval":
# For JSON validator, no code execution is needed;
# use the response directly and compare the JSON objects.
execution_result = backtick_parsed_response
# expectation is assumed to be a dict (or JSON string convertible to dict)
expected_result = prompt_row.expectation
correct = eval_result_compare(
"json_validator_eval", expected_result, execution_result
)
elif (
benchmark_file.evaluator
== ExeEvalType.python_print_execution_with_num_output
):
wrapped_code = f"print({backtick_parsed_response})"
execution_result = execute_python_code(wrapped_code)
correct = eval_result_compare(
ExeEvalType.execute_python_code_with_num_output,
expected_result,
execution_result.strip(),
)
else:
raise ValueError(f"Unsupported evaluator: {benchmark_file.evaluator}")
except Exception as e:
print(f"Error executing code in test {index}: {e}")
execution_result = str(e)
correct = False
return ExeEvalBenchmarkOutputResult(
input_prompt=prompt,
prompt_response=bench_response,
execution_result=str(execution_result),
expected_result=str(expected_result),
model=f"{provider}{provider_delimiter}{model_name}",
correct=correct,
index=index,
)
def run_benchmark_for_model(
model: str, benchmark_file: ExecEvalBenchmarkFile
) -> List[ExeEvalBenchmarkOutputResult]:
results = []
total_tests = len(benchmark_file.prompts)
try:
provider, model_name = parse_model_string(model)
except ValueError as e:
print(f"Invalid model string {model}: {str(e)}")
return []
print(f"Running benchmark with provider: {provider}, model: {model_name}")
if provider == "ollama":
# Sequential processing for Ollama
for i, prompt_row in enumerate(benchmark_file.prompts, 1):
result = process_single_prompt(
prompt_row, benchmark_file, provider, model_name, i, total_tests
)
results.append(result)
else:
# Parallel processing for other providers
with ThreadPoolExecutor(max_workers=50) as executor:
futures = []
for i, prompt_row in enumerate(benchmark_file.prompts, 1):
futures.append(
executor.submit(
process_single_prompt,
prompt_row,
benchmark_file,
provider,
model_name,
i,
total_tests,
)
)
for future in futures:
results.append(future.result())
return results
# ------------------------- Report Generation -------------------------
def generate_report(
complete_result: ExecEvalBenchmarkCompleteResult,
) -> ExecEvalBenchmarkReport:
model_reports = []
# Group results by model
model_results = {}
for result in complete_result.results:
if result.model not in model_results:
model_results[result.model] = []
model_results[result.model].append(result)
# Create model reports
for model, results in model_results.items():
correct_count = sum(1 for r in results if r.correct)
incorrect_count = len(results) - correct_count
accuracy = correct_count / len(results)
avg_tokens_per_second = sum(
r.prompt_response.tokens_per_second for r in results
) / len(results)
avg_total_duration = sum(
r.prompt_response.total_duration_ms for r in results
) / len(results)
avg_load_duration = sum(
r.prompt_response.load_duration_ms for r in results
) / len(results)
model_total_cost = 0
try:
model_total_cost = sum(
(
r.prompt_response.inputAndOutputCost
if hasattr(r.prompt_response, "inputAndOutputCost")
else 0.0
)
for r in results
)
except:
print(f"Error calculating model_total_cost for model: {model}")
model_total_cost = 0
model_reports.append(
ExecEvalBenchmarkModelReport(
model=model,
results=results,
correct_count=correct_count,
incorrect_count=incorrect_count,
accuracy=accuracy,
average_tokens_per_second=avg_tokens_per_second,
average_total_duration_ms=avg_total_duration,
average_load_duration_ms=avg_load_duration,
total_cost=model_total_cost,
)
)
# Calculate overall statistics
overall_correct = sum(r.correct_count for r in model_reports)
overall_incorrect = sum(r.incorrect_count for r in model_reports)
overall_accuracy = overall_correct / (overall_correct + overall_incorrect)
avg_tokens_per_second = sum(
r.average_tokens_per_second for r in model_reports
) / len(model_reports)
avg_total_duration = sum(r.average_total_duration_ms for r in model_reports) / len(
model_reports
)
avg_load_duration = sum(r.average_load_duration_ms for r in model_reports) / len(
model_reports
)
return ExecEvalBenchmarkReport(
benchmark_name=complete_result.benchmark_file.benchmark_name,
purpose=complete_result.benchmark_file.purpose,
base_prompt=complete_result.benchmark_file.base_prompt,
prompt_iterations=[
ExecEvalPromptIteration(
dynamic_variables=(
prompt.dynamic_variables
if prompt.dynamic_variables is not None
else {}
),
expectation=prompt.expectation,
)
for prompt in complete_result.benchmark_file.prompts
],
models=model_reports,
overall_correct_count=overall_correct,
overall_incorrect_count=overall_incorrect,
overall_accuracy=overall_accuracy,
average_tokens_per_second=avg_tokens_per_second,
average_total_duration_ms=avg_total_duration,
average_load_duration_ms=avg_load_duration,
)
</file>
<file path="execution_evaluators.py">
import subprocess
from modules.data_types import ExeEvalType
import json
from deepdiff import DeepDiff
def eval_result_compare(evalType: ExeEvalType, expected: str, actual: str) -> bool:
"""
Compare expected and actual results based on evaluation type.
For numeric outputs, compare with a small epsilon tolerance.
"""
try:
if (
evalType == ExeEvalType.execute_python_code_with_num_output
or evalType == ExeEvalType.python_print_execution_with_num_output
):
# Convert both values to float for numeric comparison
expected_num = float(expected)
actual_num = float(actual)
epsilon = 1e-6
return abs(expected_num - actual_num) < epsilon
elif evalType == ExeEvalType.execute_python_code_with_string_output:
return str(expected).strip() == str(actual).strip()
elif evalType == ExeEvalType.raw_string_evaluator:
return str(expected).strip() == str(actual).strip()
elif evalType == ExeEvalType.json_validator_eval:
if not isinstance(expected, dict):
expected = json.loads(expected)
actual_parsed = json.loads(actual) if isinstance(actual, str) else actual
print(f"Expected: {expected}")
print(f"Actual: {actual_parsed}")
deepdiffed = DeepDiff(expected, actual_parsed, ignore_order=False)
print(f"DeepDiff: {deepdiffed}")
return not deepdiffed
else:
return str(expected).strip() == str(actual).strip()
except (ValueError, TypeError):
return str(expected).strip() == str(actual).strip()
def execute_python_code(code: str) -> str:
"""
Execute Python code and return the numeric output as a string.
"""
# Remove any surrounding quotes and whitespace
code = code.strip().strip("'").strip('"')
# Create a temporary file with the code
import tempfile
with tempfile.NamedTemporaryFile(mode="w", suffix=".py", delete=True) as tmp:
tmp.write(code)
tmp.flush()
# Execute the temporary file using uv
result = execute(f"uv run {tmp.name} --ignore-warnings")
# Try to parse the result as a number
try:
# Remove any extra whitespace or newlines
cleaned_result = result.strip()
# Convert to float and back to string to normalize format
return str(float(cleaned_result))
except (ValueError, TypeError):
# If conversion fails, return the raw result
return result
def execute(code: str) -> str:
"""Execute the tests and return the output as a string."""
try:
result = subprocess.run(
code.split(),
capture_output=True,
text=True,
)
if result.returncode != 0:
return f"Error: {result.stderr}"
return result.stdout
except Exception as e:
return f"Execution error: {str(e)}"
</file>
<file path="fireworks_llm.py">
import os
import requests
import json
from modules.data_types import (
BenchPromptResponse,
PromptResponse,
ThoughtResponse,
)
from utils import deepseek_r1_distil_separate_thoughts_and_response
import time
from dotenv import load_dotenv
load_dotenv()
FIREWORKS_API_KEY = os.getenv("FIREWORKS_AI_API_KEY", "")
API_URL = "https://api.fireworks.ai/inference/v1/completions"
def get_fireworks_cost(model: str, input_tokens: int, output_tokens: int) -> float:
# For now, just return 0.0 or substitute a real cost calculation if available
return 0.0
def bench_prompt(prompt: str, model: str) -> BenchPromptResponse:
start_time = time.time()
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": f"Bearer {FIREWORKS_API_KEY}",
}
payload = {
"model": model,
"max_tokens": 20480,
"prompt": prompt,
"temperature": 0.2,
}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
end_time = time.time()
resp_json = response.json()
content = ""
if "choices" in resp_json and len(resp_json["choices"]) > 0:
content = resp_json["choices"][0].get("text", "")
return BenchPromptResponse(
response=content,
tokens_per_second=0.0, # or compute if available
provider="fireworks",
total_duration_ms=(end_time - start_time) * 1000,
load_duration_ms=0.0,
errored=not response.ok,
)
def text_prompt(prompt: str, model: str) -> PromptResponse:
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": f"Bearer {FIREWORKS_API_KEY}",
}
payload = {
"model": model,
"max_tokens": 20480,
"prompt": prompt,
"temperature": 0.0,
}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
resp_json = response.json()
print("resp_json", resp_json)
# Extract just the text from the first choice
content = ""
if "choices" in resp_json and len(resp_json["choices"]) > 0:
content = resp_json["choices"][0].get("text", "")
return PromptResponse(
response=content,
runTimeMs=0, # or compute if desired
inputAndOutputCost=0.0, # or compute if you have cost details
)
def thought_prompt(prompt: str, model: str) -> ThoughtResponse:
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": f"Bearer {FIREWORKS_API_KEY}",
}
payload = {
"model": model,
"max_tokens": 20480,
"prompt": prompt,
"temperature": 0.2,
}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
resp_json = response.json()
content = ""
if "choices" in resp_json and len(resp_json["choices"]) > 0:
content = resp_json["choices"][0].get("text", "")
if "r1" in model:
thoughts, response_content = deepseek_r1_distil_separate_thoughts_and_response(
content
)
else:
thoughts = ""
response_content = content
return ThoughtResponse(
thoughts=thoughts,
response=response_content,
error=None if response.ok else str(resp_json.get("error", "Unknown error")),
)
</file>
<file path="gemini_llm.py">
import google.generativeai as genai
from google import genai as genai2
import os
import json
from modules.tools import gemini_tools_list
from modules.data_types import (
PromptResponse,
SimpleToolCall,
ModelAlias,
ToolsAndPrompts,
ThoughtResponse,
)
from utils import (
parse_markdown_backticks,
timeit,
MAP_MODEL_ALIAS_TO_COST_PER_MILLION_TOKENS,
)
from modules.data_types import ToolCallResponse, BenchPromptResponse
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Initialize Gemini client
genai.configure(api_key=os.getenv("GEMINI_API_KEY"))
def get_gemini_cost(model: str, input_tokens: int, output_tokens: int) -> float:
"""
Calculate the cost for Gemini API usage.
Args:
model: The model name/alias used
input_tokens: Number of input tokens
output_tokens: Number of output tokens
Returns:
float: Total cost in dollars
"""
cost_map = MAP_MODEL_ALIAS_TO_COST_PER_MILLION_TOKENS.get(model)
if not cost_map:
return 0.0
input_cost = (input_tokens / 1_000_000) * cost_map["input"]
output_cost = (output_tokens / 1_000_000) * cost_map["output"]
return round(input_cost + output_cost, 6)
def thought_prompt(prompt: str, model: str) -> ThoughtResponse:
"""
Handle thought prompts for Gemini thinking models.
"""
try:
# Validate model
if model != "gemini-2.0-flash-thinking-exp-01-21":
raise ValueError(
f"Invalid model for thought prompts: {model}. Must use 'gemini-2.0-flash-thinking-exp-01-21'"
)
# Configure thinking model
config = {"thinking_config": {"include_thoughts": True}}
client = genai2.Client(
api_key=os.getenv("GEMINI_API_KEY"), http_options={"api_version": "v1alpha"}
)
with timeit() as t:
response = client.models.generate_content(
model=model, contents=prompt, config=config
)
elapsed_ms = t()
# Parse thoughts and response
thoughts = []
response_content = []
for part in response.candidates[0].content.parts:
if hasattr(part, "thought") and part.thought:
thoughts.append(part.text)
else:
response_content.append(part.text)
return ThoughtResponse(
thoughts="\n".join(thoughts),
response="\n".join(response_content),
error=None,
)
except Exception as e:
print(f"Gemini thought error: {str(e)}")
return ThoughtResponse(
thoughts=f"Error processing request: {str(e)}", response="", error=str(e)
)
def text_prompt(prompt: str, model: str) -> PromptResponse:
"""
Send a prompt to Gemini and get a response.
"""
try:
with timeit() as t:
gemini_model = genai.GenerativeModel(model_name=model)
response = gemini_model.generate_content(prompt)
elapsed_ms = t()
input_tokens = response._result.usage_metadata.prompt_token_count
output_tokens = response._result.usage_metadata.candidates_token_count
cost = get_gemini_cost(model, input_tokens, output_tokens)
return PromptResponse(
response=response.text,
runTimeMs=elapsed_ms,
inputAndOutputCost=cost,
)
except Exception as e:
print(f"Gemini error: {str(e)}")
return PromptResponse(
response=f"Error: {str(e)}", runTimeMs=0.0, inputAndOutputCost=0.0
)
def bench_prompt(prompt: str, model: str) -> BenchPromptResponse:
"""
Send a prompt to Gemini and get detailed benchmarking response.
"""
try:
with timeit() as t:
gemini_model = genai.GenerativeModel(model_name=model)
response = gemini_model.generate_content(prompt)
elapsed_ms = t()
input_tokens = response._result.usage_metadata.prompt_token_count
output_tokens = response._result.usage_metadata.candidates_token_count
cost = get_gemini_cost(model, input_tokens, output_tokens)
return BenchPromptResponse(
response=response.text,
tokens_per_second=0.0, # Gemini doesn't provide timing info
provider="gemini",
total_duration_ms=elapsed_ms,
load_duration_ms=0.0,
inputAndOutputCost=cost,
)
except Exception as e:
print(f"Gemini error: {str(e)}")
return BenchPromptResponse(
response=f"Error: {str(e)}",
tokens_per_second=0.0,
provider="gemini",
total_duration_ms=0.0,
load_duration_ms=0.0,
inputAndOutputCost=0.0,
errored=True,
)
def tool_prompt(prompt: str, model: str, force_tools: list[str]) -> ToolCallResponse:
"""
Run a chat model with tool calls using Gemini's API.
Now supports JSON structured output variants by parsing the response.
"""
with timeit() as t:
if "-json" in model:
# Initialize model for JSON output
base_model = model.replace("-json", "")
if model == "gemini-exp-1114-json":
base_model = "gemini-exp-1114" # Map to actual model name
gemini_model = genai.GenerativeModel(
model_name=base_model,
)
# Send message and get JSON response
chat = gemini_model.start_chat()
response = chat.send_message(prompt)
try:
# Parse raw response text into ToolsAndPrompts model
parsed_response = ToolsAndPrompts.model_validate_json(
parse_markdown_backticks(response.text)
)
tool_calls = [
SimpleToolCall(
tool_name=tap.tool_name, params={"prompt": tap.prompt}
)
for tap in parsed_response.tools_and_prompts
]
except Exception as e:
print(f"Failed to parse JSON response: {e}")
tool_calls = []
else:
# Original implementation using function calling
gemini_model = genai.GenerativeModel(
model_name=model, tools=gemini_tools_list
)
chat = gemini_model.start_chat(enable_automatic_function_calling=True)
response = chat.send_message(prompt)
tool_calls = []
for part in response.parts:
if hasattr(part, "function_call"):
fc = part.function_call
tool_calls.append(SimpleToolCall(tool_name=fc.name, params=fc.args))
# Extract token counts and calculate cost
usage_metadata = response._result.usage_metadata
input_tokens = usage_metadata.prompt_token_count
output_tokens = usage_metadata.candidates_token_count
cost = get_gemini_cost(model, input_tokens, output_tokens)
return ToolCallResponse(
tool_calls=tool_calls, runTimeMs=t(), inputAndOutputCost=cost
)
</file>
<file path="llm_models.py">
import llm
from dotenv import load_dotenv
import os
from modules import ollama_llm
from modules.data_types import (
ModelAlias,
PromptResponse,
PromptWithToolCalls,
ToolCallResponse,
ThoughtResponse,
)
from modules import openai_llm, gemini_llm, deepseek_llm, fireworks_llm
from utils import MAP_MODEL_ALIAS_TO_COST_PER_MILLION_TOKENS
from modules.tools import all_tools_list
from modules import anthropic_llm
# Load environment variables from .env file
load_dotenv()
def simple_prompt(prompt_str: str, model_alias_str: str) -> PromptResponse:
parts = model_alias_str.split(":", 1)
if len(parts) < 2:
raise ValueError("No provider prefix found in model string")
provider = parts[0]
model_name = parts[1]
# For special predictive cases:
if provider == "openai" and model_name in [
"gpt-4o-predictive",
"gpt-4o-mini-predictive",
]:
# Remove -predictive suffix when passing to API
clean_model_name = model_name.replace("-predictive", "")
return openai_llm.predictive_prompt(prompt_str, prompt_str, clean_model_name)
if provider == "openai":
return openai_llm.text_prompt(prompt_str, model_name)
elif provider == "ollama":
return ollama_llm.text_prompt(prompt_str, model_name)
elif provider == "anthropic":
return anthropic_llm.text_prompt(prompt_str, model_name)
elif provider == "gemini":
return gemini_llm.text_prompt(prompt_str, model_name)
elif provider == "deepseek":
return deepseek_llm.text_prompt(prompt_str, model_name)
elif provider == "fireworks":
return fireworks_llm.text_prompt(prompt_str, model_name)
else:
raise ValueError(f"Unsupported provider: {provider}")
def tool_prompt(prompt: PromptWithToolCalls) -> ToolCallResponse:
model_str = str(prompt.model)
parts = model_str.split(":", 1)
if len(parts) < 2:
raise ValueError("No provider prefix found in model string")
provider = parts[0]
model_name = parts[1]
if provider == "openai":
return openai_llm.tool_prompt(prompt.prompt, model_name, all_tools_list)
elif provider == "anthropic":
return anthropic_llm.tool_prompt(prompt.prompt, model_name)
elif provider == "gemini":
return gemini_llm.tool_prompt(prompt.prompt, model_name, all_tools_list)
elif provider == "deepseek":
raise ValueError("DeepSeek does not support tool calls")
elif provider == "ollama":
raise ValueError("Ollama does not support tool calls")
else:
raise ValueError(f"Unsupported provider for tool calls: {provider}")
def thought_prompt(prompt: str, model: str) -> ThoughtResponse:
"""
Handle thought prompt requests with specialized parsing for supported models.
Fall back to standard text prompts for other models.
"""
parts = model.split(":", 1)
if len(parts) < 2:
raise ValueError("No provider prefix found in model string")
provider = parts[0]
model_name = parts[1]
try:
if provider == "deepseek":
if model_name != "deepseek-reasoner":
# Fallback to standard text prompt for non-reasoner models
text_response = simple_prompt(prompt, model)
return ThoughtResponse(
thoughts="", response=text_response.response, error=None
)
# Proceed with reasoner-specific processing
response = deepseek_llm.thought_prompt(prompt, model_name)
return response
elif provider == "gemini":
if model_name != "gemini-2.0-flash-thinking-exp-01-21":
# Fallback to standard text prompt for non-thinking models
text_response = simple_prompt(prompt, model)
return ThoughtResponse(
thoughts="", response=text_response.response, error=None
)
# Proceed with thinking-specific processing
response = gemini_llm.thought_prompt(prompt, model_name)
return response
elif provider == "ollama":
if "deepseek-r1" not in model_name:
# Fallback to standard text prompt for non-R1 models
text_response = simple_prompt(prompt, model)
return ThoughtResponse(
thoughts="", response=text_response.response, error=None
)
# Proceed with R1-specific processing
response = ollama_llm.thought_prompt(prompt, model_name)
return response
elif provider == "fireworks":
text_response = simple_prompt(prompt, model)
return ThoughtResponse(
thoughts="", response=text_response.response, error=None
)
else:
# For all other providers, use standard text prompt and wrap in ThoughtResponse
text_response = simple_prompt(prompt, model)
return ThoughtResponse(
thoughts="", response=text_response.response, error=None
)
except Exception as e:
return ThoughtResponse(
thoughts=f"Error processing request: {str(e)}", response="", error=str(e)
)
</file>
<file path="ollama_llm.py">
from ollama import chat
from modules.data_types import PromptResponse, BenchPromptResponse, ThoughtResponse
from utils import timeit, deepseek_r1_distil_separate_thoughts_and_response
import json
def text_prompt(prompt: str, model: str) -> PromptResponse:
"""
Send a prompt to Ollama and get a response.
"""
try:
with timeit() as t:
response = chat(
model=model,
messages=[
{
"role": "user",
"content": prompt,
},
],
)
elapsed_ms = t()
return PromptResponse(
response=response.message.content,
runTimeMs=elapsed_ms, # Now using actual timing
inputAndOutputCost=0.0, # Ollama is free
)
except Exception as e:
print(f"Ollama error: {str(e)}")
return PromptResponse(
response=f"Error: {str(e)}", runTimeMs=0, inputAndOutputCost=0.0
)
def get_ollama_costs() -> tuple[int, int]:
"""
Return token costs for Ollama (always 0 since it's free)
"""
return 0, 0
def thought_prompt(prompt: str, model: str) -> ThoughtResponse:
"""
Handle thought prompts for DeepSeek R1 models running on Ollama.
"""
try:
# Validate model name contains deepseek-r1
if "deepseek-r1" not in model:
raise ValueError(
f"Model {model} not supported for thought prompts. Must contain 'deepseek-r1'"
)
with timeit() as t:
# Get raw response from Ollama
response = chat(
model=model,
messages=[
{
"role": "user",
"content": prompt,
},
],
)
# Extract content and parse thoughts/response
content = response.message.content
thoughts, response_content = (
deepseek_r1_distil_separate_thoughts_and_response(content)
)
return ThoughtResponse(
thoughts=thoughts,
response=response_content,
error=None,
)
except Exception as e:
print(f"Ollama thought error ({model}): {str(e)}")
return ThoughtResponse(
thoughts=f"Error processing request: {str(e)}", response="", error=str(e)
)
def bench_prompt(prompt: str, model: str) -> BenchPromptResponse:
"""
Send a prompt to Ollama and get detailed benchmarking response.
"""
try:
response = chat(
model=model,
messages=[
{
"role": "user",
"content": prompt,
},
],
)
# Calculate tokens per second using eval_count and eval_duration
eval_count = response.get("eval_count", 0)
eval_duration_ns = response.get("eval_duration", 0)
# Convert nanoseconds to seconds and calculate tokens per second
eval_duration_s = eval_duration_ns / 1_000_000_000
tokens_per_second = eval_count / eval_duration_s if eval_duration_s > 0 else 0
# Create BenchPromptResponse
bench_response = BenchPromptResponse(
response=response.message.content,
tokens_per_second=tokens_per_second,
provider="ollama",
total_duration_ms=response.get("total_duration", 0)
/ 1_000_000, # Convert ns to ms
load_duration_ms=response.get("load_duration", 0)
/ 1_000_000, # Convert ns to ms
inputAndOutputCost=0.0, # Ollama is free
)
# print(json.dumps(bench_response.dict(), indent=2))
return bench_response
except Exception as e:
print(f"Ollama error: {str(e)}")
return BenchPromptResponse(
response=f"Error: {str(e)}",
tokens_per_second=0.0,
provider="ollama",
total_duration_ms=0.0,
load_duration_ms=0.0,
errored=True,
)
</file>
<file path="openai_llm.py">
import openai
import os
import json
from modules.tools import openai_tools_list
from modules.data_types import SimpleToolCall, ToolsAndPrompts
from utils import parse_markdown_backticks, timeit, parse_reasoning_effort
from modules.data_types import (
PromptResponse,
ModelAlias,
ToolCallResponse,
BenchPromptResponse,
)
from utils import MAP_MODEL_ALIAS_TO_COST_PER_MILLION_TOKENS
from modules.tools import all_tools_list
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
openai_client: openai.OpenAI = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# reasoning_effort_enabled_models = [
# "o3-mini",
# "o1",
# ]
def get_openai_cost(model: str, input_tokens: int, output_tokens: int) -> float:
"""
Calculate the cost for OpenAI API usage.
Args:
model: The model name/alias used
input_tokens: Number of input tokens
output_tokens: Number of output tokens
Returns:
float: Total cost in dollars
"""
# Direct model name lookup first
model_alias = model
# Only do special mapping for gpt-4 variants
if "gpt-4" in model:
if model == "gpt-4o-mini":
model_alias = ModelAlias.gpt_4o_mini
elif model == "gpt-4o":
model_alias = ModelAlias.gpt_4o
else:
model_alias = ModelAlias.gpt_4o
cost_map = MAP_MODEL_ALIAS_TO_COST_PER_MILLION_TOKENS.get(model_alias)
if not cost_map:
print(f"No cost map found for model: {model}")
return 0.0
input_cost = (input_tokens / 1_000_000) * float(cost_map["input"])
output_cost = (output_tokens / 1_000_000) * float(cost_map["output"])
# print(
# f"model: {model}, input_cost: {input_cost}, output_cost: {output_cost}, total_cost: {input_cost + output_cost}, total_cost_rounded: {round(input_cost + output_cost, 6)}"
# )
return round(input_cost + output_cost, 6)
def tool_prompt(prompt: str, model: str, force_tools: list[str]) -> ToolCallResponse:
"""
Run a chat model forcing specific tool calls.
Now supports JSON structured output variants.
"""
base_model, reasoning_effort = parse_reasoning_effort(model)
with timeit() as t:
if base_model == "o1-mini-json":
# Manual JSON parsing for o1-mini
completion = openai_client.chat.completions.create(
model="o1-mini",
messages=[{"role": "user", "content": prompt}],
)
try:
# Parse raw response text into ToolsAndPrompts model
parsed_response = ToolsAndPrompts.model_validate_json(
parse_markdown_backticks(completion.choices[0].message.content)
)
tool_calls = [
SimpleToolCall(
tool_name=tap.tool_name.value, params={"prompt": tap.prompt}
)
for tap in parsed_response.tools_and_prompts
]
except Exception as e:
print(f"Failed to parse JSON response: {e}")
tool_calls = []
elif "-json" in base_model:
# Use structured output for JSON variants
completion = openai_client.beta.chat.completions.parse(
model=base_model.replace("-json", ""),
messages=[{"role": "user", "content": prompt}],
response_format=ToolsAndPrompts,
)
try:
tool_calls = [
SimpleToolCall(
tool_name=tap.tool_name.value, params={"prompt": tap.prompt}
)
for tap in completion.choices[0].message.parsed.tools_and_prompts
]
except Exception as e:
print(f"Failed to parse JSON response: {e}")
tool_calls = []
else:
# Original implementation for function calling
completion = openai_client.chat.completions.create(
model=base_model,
messages=[{"role": "user", "content": prompt}],
tools=openai_tools_list,
tool_choice="required",
)
tool_calls = [
SimpleToolCall(
tool_name=tool_call.function.name,
params=json.loads(tool_call.function.arguments),
)
for tool_call in completion.choices[0].message.tool_calls or []
]
# Calculate costs
input_tokens = completion.usage.prompt_tokens
output_tokens = completion.usage.completion_tokens
cost = get_openai_cost(model, input_tokens, output_tokens)
return ToolCallResponse(
tool_calls=tool_calls, runTimeMs=t(), inputAndOutputCost=cost
)
def bench_prompt(prompt: str, model: str) -> BenchPromptResponse:
"""
Send a prompt to OpenAI and get detailed benchmarking response.
"""
base_model, reasoning_effort = parse_reasoning_effort(model)
try:
with timeit() as t:
if reasoning_effort:
completion = openai_client.chat.completions.create(
model=base_model,
reasoning_effort=reasoning_effort,
messages=[{"role": "user", "content": prompt}],
stream=False,
)
else:
completion = openai_client.chat.completions.create(
model=base_model,
messages=[{"role": "user", "content": prompt}],
stream=False,
)
elapsed_ms = t()
input_tokens = completion.usage.prompt_tokens
output_tokens = completion.usage.completion_tokens
cost = get_openai_cost(base_model, input_tokens, output_tokens)
return BenchPromptResponse(
response=completion.choices[0].message.content,
tokens_per_second=0.0, # OpenAI doesn't provide timing info
provider="openai",
total_duration_ms=elapsed_ms,
load_duration_ms=0.0,
inputAndOutputCost=cost,
)
except Exception as e:
print(f"OpenAI error: {str(e)}")
return BenchPromptResponse(
response=f"Error: {str(e)}",
tokens_per_second=0.0,
provider="openai",
total_duration_ms=0.0,
load_duration_ms=0.0,
inputAndOutputCost=0.0,
errored=True,
)
def predictive_prompt(prompt: str, prediction: str, model: str) -> PromptResponse:
"""
Run a chat model with a predicted output to reduce latency.
Args:
prompt (str): The prompt to send to the OpenAI API.
prediction (str): The predicted output text.
model (str): The model ID to use for the API call.
Returns:
PromptResponse: The response including text, runtime, and cost.
"""
base_model, reasoning_effort = parse_reasoning_effort(model)
# Prepare the API call parameters outside the timing block
messages = [{"role": "user", "content": prompt}]
prediction_param = {"type": "content", "content": prediction}
# Only time the actual API call
with timeit() as t:
completion = openai_client.chat.completions.create(
model=base_model,
reasoning_effort=reasoning_effort,
messages=messages,
prediction=prediction_param,
)
# Process results after timing block
input_tokens = completion.usage.prompt_tokens
output_tokens = completion.usage.completion_tokens
cost = get_openai_cost(base_model, input_tokens, output_tokens)
return PromptResponse(
response=completion.choices[0].message.content,
runTimeMs=t(), # Get the elapsed time of just the API call
inputAndOutputCost=cost,
)
def text_prompt(prompt: str, model: str) -> PromptResponse:
"""
Send a prompt to OpenAI and get a response.
"""
base_model, reasoning_effort = parse_reasoning_effort(model)
try:
with timeit() as t:
if reasoning_effort:
completion = openai_client.chat.completions.create(
model=base_model,
reasoning_effort=reasoning_effort,
messages=[{"role": "user", "content": prompt}],
)
else:
completion = openai_client.chat.completions.create(
model=base_model,
messages=[{"role": "user", "content": prompt}],
)
print("completion.usage", completion.usage.model_dump())
input_tokens = completion.usage.prompt_tokens
output_tokens = completion.usage.completion_tokens
cost = get_openai_cost(base_model, input_tokens, output_tokens)
return PromptResponse(
response=completion.choices[0].message.content,
runTimeMs=t(),
inputAndOutputCost=cost,
)
except Exception as e:
print(f"OpenAI error: {str(e)}")
return PromptResponse(
response=f"Error: {str(e)}", runTimeMs=0.0, inputAndOutputCost=0.0
)
</file>
<file path="tools.py">
def run_coder_agent(prompt: str) -> str:
"""
Run the coder agent with the given prompt.
Args:
prompt (str): The input prompt for the coder agent
Returns:
str: The response from the coder agent
"""
return "run_coder_agent"
def run_git_agent(prompt: str) -> str:
"""
Run the git agent with the given prompt.
Args:
prompt (str): The input prompt for the git agent
Returns:
str: The response from the git agent
"""
return "run_git_agent"
def run_docs_agent(prompt: str) -> str:
"""
Run the docs agent with the given prompt.
Args:
prompt (str): The input prompt for the docs agent
Returns:
str: The response from the docs agent
"""
return "run_docs_agent"
# Gemini tools list
gemini_tools_list = [
{
"function_declarations": [
{
"name": "run_coder_agent",
"description": "Run the coding agent with the given prompt. Use this when the user needs help writing, reviewing, or modifying code.",
"parameters": {
"type_": "OBJECT",
"properties": {
"prompt": {
"type_": "STRING",
"description": "The input prompt that describes what to code for the coder agent"
}
},
"required": ["prompt"]
}
},
{
"name": "run_git_agent",
"description": "Run the git agent with the given prompt. Use this when the user needs help with git operations, commits, or repository management.",
"parameters": {
"type_": "OBJECT",
"properties": {
"prompt": {
"type_": "STRING",
"description": "The input prompt that describes what to commit for the git agent"
}
},
"required": ["prompt"]
}
},
{
"name": "run_docs_agent",
"description": "Run the documentation agent with the given prompt. Use this when the user needs help creating, updating, or reviewing documentation.",
"parameters": {
"type_": "OBJECT",
"properties": {
"prompt": {
"type_": "STRING",
"description": "The input prompt that describes what to document for the documentation agent"
}
},
"required": ["prompt"]
}
}
]
}
]
# OpenAI tools list
openai_tools_list = [
{
"type": "function",
"function": {
"name": "run_coder_agent",
"description": "Run the coding agent with the given prompt",
"parameters": {
"type": "object",
"properties": {
"prompt": {
"type": "string",
"description": "The input prompt that describes what to code for the coder agent",
}
},
"required": ["prompt"],
},
},
},
{
"type": "function",
"function": {
"name": "run_git_agent",
"description": "Run the git agent with the given prompt",
"parameters": {
"type": "object",
"properties": {
"prompt": {
"type": "string",
"description": "The input prompt that describes what to commit for the git agent",
}
},
"required": ["prompt"],
},
},
},
{
"type": "function",
"function": {
"name": "run_docs_agent",
"description": "Run the documentation agent with the given prompt",
"parameters": {
"type": "object",
"properties": {
"prompt": {
"type": "string",
"description": "The input prompt that describes what to document for the documentation agent",
}
},
"required": ["prompt"],
},
},
},
]
anthropic_tools_list = [
{
"name": "run_coder_agent",
"description": "Run the coding agent with the given prompt",
"input_schema": {
"type": "object",
"properties": {
"prompt": {
"type": "string",
"description": "The input prompt that describes what to code for the coder agent",
}
},
"required": ["prompt"]
}
},
{
"name": "run_git_agent",
"description": "Run the git agent with the given prompt",
"input_schema": {
"type": "object",
"properties": {
"prompt": {
"type": "string",
"description": "The input prompt that describes what to commit for the git agent",
}
},
"required": ["prompt"]
}
},
{
"name": "run_docs_agent",
"description": "Run the documentation agent with the given prompt",
"input_schema": {
"type": "object",
"properties": {
"prompt": {
"type": "string",
"description": "The input prompt that describes what to document for the documentation agent",
}
},
"required": ["prompt"]
}
}
]
all_tools_list = [d["function"]["name"] for d in openai_tools_list]
</file>
</files>
```