# Directory Structure
```
├── .env
├── .gitignore
├── LICENSE
├── mcp_sqlalchemy_server
│ ├── __init__.py
│ └── server.py
├── pyproject.toml
└── README.md
```
# Files
--------------------------------------------------------------------------------
/.env:
--------------------------------------------------------------------------------
```
1 | ODBC_DSN=VOS
2 | ODBC_USER=dba
3 | ODBC_PASSWORD=dba
4 | API_KEY=sk-xxx
```
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
```
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | share/python-wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 | MANIFEST
28 |
29 | # PyInstaller
30 | # Usually these files are written by a python script from a template
31 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
32 | *.manifest
33 | *.spec
34 |
35 | # Installer logs
36 | pip-log.txt
37 | pip-delete-this-directory.txt
38 |
39 | # Unit test / coverage reports
40 | htmlcov/
41 | .tox/
42 | .nox/
43 | .coverage
44 | .coverage.*
45 | .cache
46 | nosetests.xml
47 | coverage.xml
48 | *.cover
49 | *.py,cover
50 | .hypothesis/
51 | .pytest_cache/
52 | cover/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | .pybuilder/
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | # For a library or package, you might want to ignore these files since the code is
87 | # intended to run in multiple environments; otherwise, check them in:
88 | # .python-version
89 |
90 | # pipenv
91 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
92 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
93 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
94 | # install all needed dependencies.
95 | #Pipfile.lock
96 |
97 | # UV
98 | # Similar to Pipfile.lock, it is generally recommended to include uv.lock in version control.
99 | # This is especially recommended for binary packages to ensure reproducibility, and is more
100 | # commonly ignored for libraries.
101 | #uv.lock
102 |
103 | # poetry
104 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
105 | # This is especially recommended for binary packages to ensure reproducibility, and is more
106 | # commonly ignored for libraries.
107 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
108 | #poetry.lock
109 |
110 | # pdm
111 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
112 | #pdm.lock
113 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
114 | # in version control.
115 | # https://pdm.fming.dev/latest/usage/project/#working-with-version-control
116 | .pdm.toml
117 | .pdm-python
118 | .pdm-build/
119 |
120 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
121 | __pypackages__/
122 |
123 | # Celery stuff
124 | celerybeat-schedule
125 | celerybeat.pid
126 |
127 | # SageMath parsed files
128 | *.sage.py
129 |
130 | # Environments
131 | #.env
132 | .venv
133 | env/
134 | venv/
135 | ENV/
136 | env.bak/
137 | venv.bak/
138 |
139 | # Spyder project settings
140 | .spyderproject
141 | .spyproject
142 |
143 | # Rope project settings
144 | .ropeproject
145 |
146 | # mkdocs documentation
147 | /site
148 |
149 | # mypy
150 | .mypy_cache/
151 | .dmypy.json
152 | dmypy.json
153 |
154 | # Pyre type checker
155 | .pyre/
156 |
157 | # pytype static type analyzer
158 | .pytype/
159 |
160 | # Cython debug symbols
161 | cython_debug/
162 |
163 | # PyCharm
164 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
165 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
166 | # and can be added to the global gitignore or merged into this file. For a more nuclear
167 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
168 | #.idea/
169 |
170 | # Ruff stuff:
171 | .ruff_cache/
172 |
173 | # PyPI configuration file
174 | .pypirc
175 |
```
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
```markdown
1 | ---
2 |
3 | # MCP Server ODBC via SQLAlchemy
4 |
5 | A lightweight MCP (Model Context Protocol) server for ODBC built with **FastAPI**, **pyodbc**, and **SQLAlchemy**. This server is compatible with Virtuoso DBMS and other DBMS backends that implement a SQLAlchemy provider.
6 |
7 | 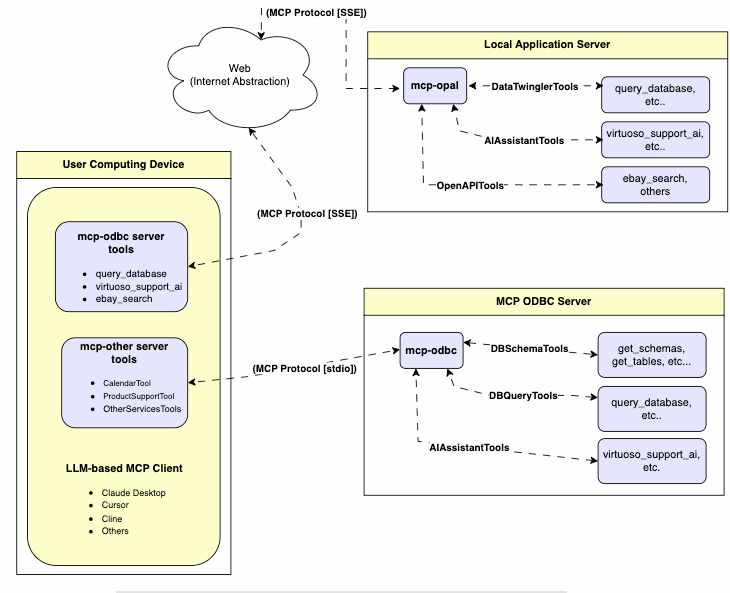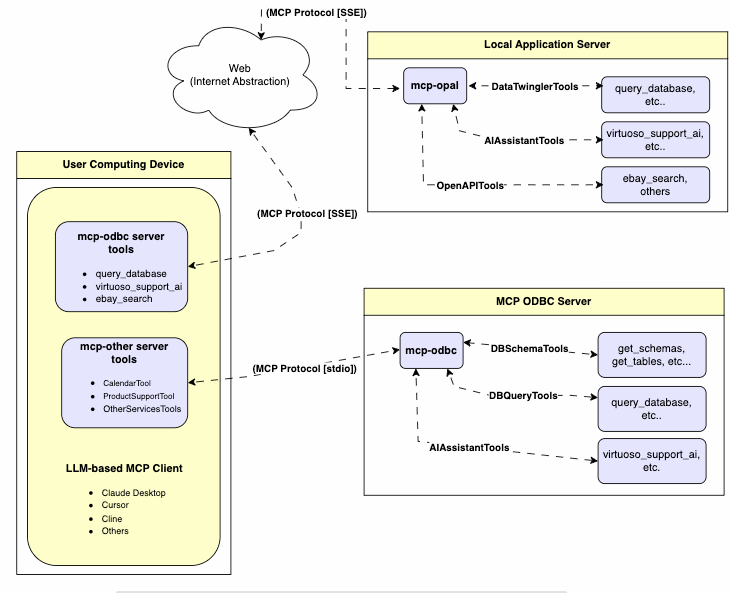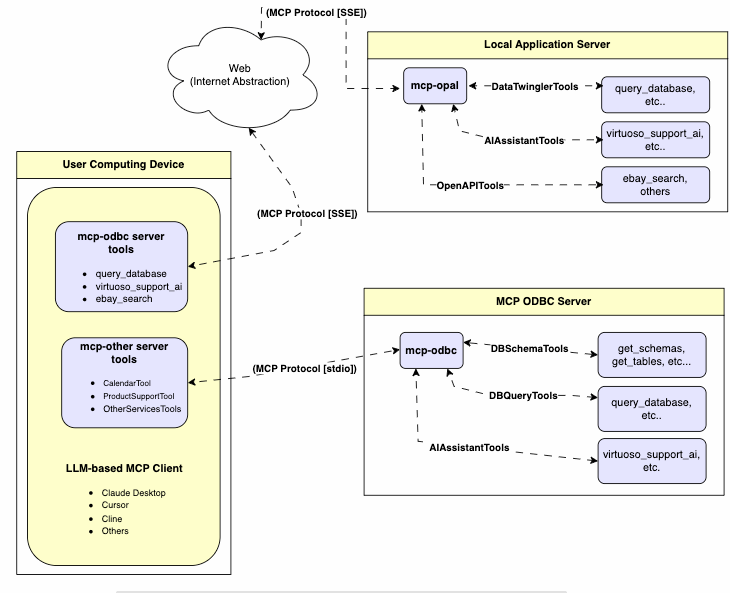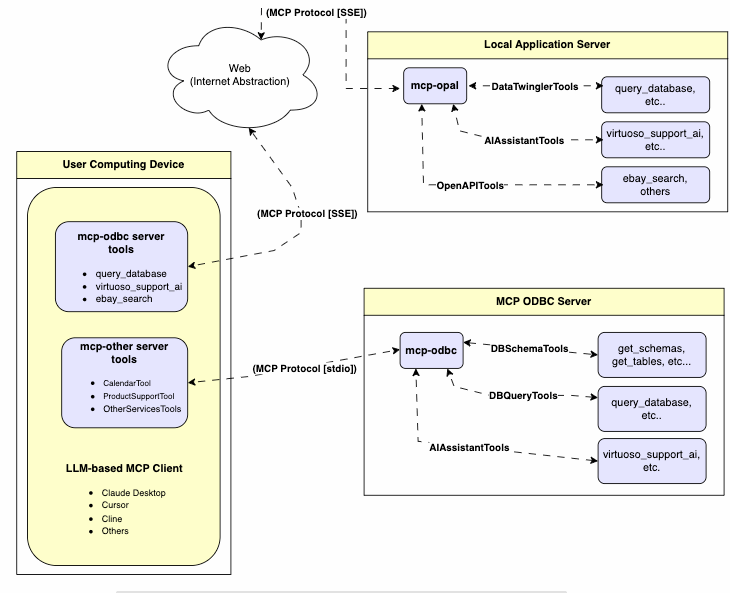
8 |
9 | ---
10 |
11 | ## Features
12 |
13 | - **Get Schemas**: Fetch and list all schema names from the connected database.
14 | - **Get Tables**: Retrieve table information for specific schemas or all schemas.
15 | - **Describe Table**: Generate a detailed description of table structures, including:
16 | - Column names and data types
17 | - Nullable attributes
18 | - Primary and foreign keys
19 | - **Search Tables**: Filter and retrieve tables based on name substrings.
20 | - **Execute Stored Procedures**: In the case of Virtuoso, execute stored procedures and retrieve results.
21 | - **Execute Queries**:
22 | - JSONL result format: Optimized for structured responses.
23 | - Markdown table format: Ideal for reporting and visualization.
24 |
25 | ---
26 |
27 | ## Prerequisites
28 |
29 | 1. **Install uv**:
30 | ```bash
31 | pip install uv
32 | ```
33 | Or use Homebrew:
34 | ```bash
35 | brew install uv
36 | ```
37 |
38 | 2. **unixODBC Runtime Environment Checks**:
39 |
40 | 1. Check installation configuration (i.e., location of key INI files) by running: `odbcinst -j`
41 | 2. List available data source names by running: `odbcinst -q -s`
42 |
43 | 3. **ODBC DSN Setup**: Configure your ODBC Data Source Name (`~/.odbc.ini`) for the target database. Example for Virtuoso DBMS:
44 | ```
45 | [VOS]
46 | Description = OpenLink Virtuoso
47 | Driver = /path/to/virtodbcu_r.so
48 | Database = Demo
49 | Address = localhost:1111
50 | WideAsUTF16 = Yes
51 | ```
52 |
53 | 3. **SQLAlchemy URL Binding**: Use the format:
54 | ```
55 | virtuoso+pyodbc://user:password@VOS
56 | ```
57 |
58 | ---
59 |
60 | ## Installation
61 |
62 | Clone this repository:
63 | ```bash
64 | git clone https://github.com/OpenLinkSoftware/mcp-sqlalchemy-server.git
65 | cd mcp-sqlalchemy-server
66 | ```
67 | ## Environment Variables
68 | Update your `.env`by overriding the defaults to match your preferences
69 | ```
70 | ODBC_DSN=VOS
71 | ODBC_USER=dba
72 | ODBC_PASSWORD=dba
73 | API_KEY=xxx
74 | ```
75 | ---
76 |
77 | ## Configuration
78 |
79 | For **Claude Desktop** users:
80 | Add the following to `claude_desktop_config.json`:
81 | ```json
82 | {
83 | "mcpServers": {
84 | "my_database": {
85 | "command": "uv",
86 | "args": ["--directory", "/path/to/mcp-sqlalchemy-server", "run", "mcp-sqlalchemy-server"],
87 | "env": {
88 | "ODBC_DSN": "dsn_name",
89 | "ODBC_USER": "username",
90 | "ODBC_PASSWORD": "password",
91 | "API_KEY": "sk-xxx"
92 | }
93 | }
94 | }
95 | }
96 | ```
97 | ---
98 | # Usage
99 | ## Database Management System (DBMS) Connection URLs
100 | Here are the pyodbc URL examples for connecting to DBMS systems that have been tested using this mcp-server.
101 |
102 | | Database | URL Format |
103 | |---------------|-----------------------------------------------|
104 | | Virtuoso DBMS | `virtuoso+pyodbc://user:password@ODBC_DSN` |
105 | | PostgreSQL | `postgresql://user:password@localhost/dbname` |
106 | | MySQL | `mysql+pymysql://user:password@localhost/dbname` |
107 | | SQLite | `sqlite:///path/to/database.db` |
108 | Once connected, you can interact with your WhatsApp contacts through Claude, leveraging Claude's AI capabilities in your WhatsApp conversations.
109 |
110 | ## Tools Provided
111 |
112 | ### Overview
113 | |name|description|
114 | |---|---|
115 | |podbc_get_schemas|List database schemas accessible to connected database management system (DBMS).|
116 | |podbc_get_tables|List tables associated with a selected database schema.|
117 | |podbc_describe_table|Provide the description of a table associated with a designated database schema. This includes information about column names, data types, nulls handling, autoincrement, primary key, and foreign keys|
118 | |podbc_filter_table_names|List tables, based on a substring pattern from the `q` input field, associated with a selected database schema.|
119 | |podbc_query_database|Execute a SQL query and return results in JSONL format.|
120 | |podbc_execute_query|Execute a SQL query and return results in JSONL format.|
121 | |podbc_execute_query_md|Execute a SQL query and return results in Markdown table format.|
122 | |podbc_spasql_query|Execute a SPASQL query and return results.|
123 | |podbc_sparql_query|Execute a SPARQL query and return results.|
124 | |podbc_virtuoso_support_ai|Interact with the Virtuoso Support Assistant/Agent -- a Virtuoso-specific feature for interacting with LLMs|
125 |
126 | ### Detailed Description
127 |
128 | - **podbc_get_schemas**
129 | - Retrieve and return a list of all schema names from the connected database.
130 | - Input parameters:
131 | - `user` (string, optional): Database username. Defaults to "demo".
132 | - `password` (string, optional): Database password. Defaults to "demo".
133 | - `dsn` (string, optional): ODBC data source name. Defaults to "Local Virtuoso".
134 | - Returns a JSON string array of schema names.
135 |
136 | - **podbc_get_tables**
137 | - Retrieve and return a list containing information about tables in a specified schema. If no schema is provided, uses the connection's default schema.
138 | - Input parameters:
139 | - `schema` (string, optional): Database schema to filter tables. Defaults to connection default.
140 | - `user` (string, optional): Database username. Defaults to "demo".
141 | - `password` (string, optional): Database password. Defaults to "demo".
142 | - `dsn` (string, optional): ODBC data source name. Defaults to "Local Virtuoso".
143 | - Returns a JSON string containing table information (e.g., TABLE_CAT, TABLE_SCHEM, TABLE_NAME, TABLE_TYPE).
144 |
145 | - **podbc_filter_table_names**
146 | - Filters and returns information about tables whose names contain a specific substring.
147 | - Input parameters:
148 | - `q` (string, required): The substring to search for within table names.
149 | - `schema` (string, optional): Database schema to filter tables. Defaults to connection default.
150 | - `user` (string, optional): Database username. Defaults to "demo".
151 | - `password` (string, optional): Database password. Defaults to "demo".
152 | - `dsn` (string, optional): ODBC data source name. Defaults to "Local Virtuoso".
153 | - Returns a JSON string containing information for matching tables.
154 |
155 | - **podbc_describe_table**
156 | - Retrieve and return detailed information about the columns of a specific table.
157 | - Input parameters:
158 | - `schema` (string, required): The database schema name containing the table.
159 | - `table` (string, required): The name of the table to describe.
160 | - `user` (string, optional): Database username. Defaults to "demo".
161 | - `password` (string, optional): Database password. Defaults to "demo".
162 | - `dsn` (string, optional): ODBC data source name. Defaults to "Local Virtuoso".
163 | - Returns a JSON string describing the table's columns (e.g., COLUMN_NAME, TYPE_NAME, COLUMN_SIZE, IS_NULLABLE).
164 |
165 | - **podbc_query_database**
166 | - Execute a standard SQL query and return the results in JSON format.
167 | - Input parameters:
168 | - `query` (string, required): The SQL query string to execute.
169 | - `user` (string, optional): Database username. Defaults to "demo".
170 | - `password` (string, optional): Database password. Defaults to "demo".
171 | - `dsn` (string, optional): ODBC data source name. Defaults to "Local Virtuoso".
172 | - Returns query results as a JSON string.
173 |
174 | - **podbc_query_database_md**
175 | - Execute a standard SQL query and return the results formatted as a Markdown table.
176 | - Input parameters:
177 | - `query` (string, required): The SQL query string to execute.
178 | - `user` (string, optional): Database username. Defaults to "demo".
179 | - `password` (string, optional): Database password. Defaults to "demo".
180 | - `dsn` (string, optional): ODBC data source name. Defaults to "Local Virtuoso".
181 | - Returns query results as a Markdown table string.
182 |
183 | - **podbc_query_database_jsonl**
184 | - Execute a standard SQL query and return the results in JSON Lines (JSONL) format (one JSON object per line).
185 | - Input parameters:
186 | - `query` (string, required): The SQL query string to execute.
187 | - `user` (string, optional): Database username. Defaults to "demo".
188 | - `password` (string, optional): Database password. Defaults to "demo".
189 | - `dsn` (string, optional): ODBC data source name. Defaults to "Local Virtuoso".
190 | - Returns query results as a JSONL string.
191 |
192 | - **podbc_spasql_query**
193 | - Execute a SPASQL (SQL/SPARQL hybrid) query return results. This is a Virtuoso-specific feature.
194 | - Input parameters:
195 | - `query` (string, required): The SPASQL query string.
196 | - `max_rows` (number, optional): Maximum number of rows to return. Defaults to 20.
197 | - `timeout` (number, optional): Query timeout in milliseconds. Defaults to 30000.
198 | - `user` (string, optional): Database username. Defaults to "demo".
199 | - `password` (string, optional): Database password. Defaults to "demo".
200 | - `dsn` (string, optional): ODBC data source name. Defaults to "Local Virtuoso".
201 | - Returns the result from the underlying stored procedure call (e.g., `Demo.demo.execute_spasql_query`).
202 |
203 | - **podbc_sparql_query**
204 | - Execute a SPARQL query and return results. This is a Virtuoso-specific feature.
205 | - Input parameters:
206 | - `query` (string, required): The SPARQL query string.
207 | - `format` (string, optional): Desired result format. Defaults to 'json'.
208 | - `timeout` (number, optional): Query timeout in milliseconds. Defaults to 30000.
209 | - `user` (string, optional): Database username. Defaults to "demo".
210 | - `password` (string, optional): Database password. Defaults to "demo".
211 | - `dsn` (string, optional): ODBC data source name. Defaults to "Local Virtuoso".
212 | - Returns the result from the underlying function call (e.g., `"UB".dba."sparqlQuery"`).
213 |
214 | - **podbc_virtuoso_support_ai**
215 | - Utilizes a Virtuoso-specific AI Assistant function, passing a prompt and optional API key. This is a Virtuoso-specific feature.
216 | - Input parameters:
217 | - `prompt` (string, required): The prompt text for the AI function.
218 | - `api_key` (string, optional): API key for the AI service. Defaults to "none".
219 | - `user` (string, optional): Database username. Defaults to "demo".
220 | - `password` (string, optional): Database password. Defaults to "demo".
221 | - `dsn` (string, optional): ODBC data source name. Defaults to "Local Virtuoso".
222 | - Returns the result from the AI Support Assistant function call (e.g., `DEMO.DBA.OAI_VIRTUOSO_SUPPORT_AI`).
223 |
224 | ---
225 |
226 | ## Troubleshooting
227 |
228 | For easier troubleshooting:
229 | 1. Install the MCP Inspector:
230 | ```bash
231 | npm install -g @modelcontextprotocol/inspector
232 | ```
233 |
234 | 2. Start the inspector:
235 | ```bash
236 | npx @modelcontextprotocol/inspector uv --directory /path/to/mcp-sqlalchemy-server run mcp-sqlalchemy-server
237 | ```
238 |
239 | Access the provided URL to troubleshoot server interactions.
240 |
241 |
```
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
```toml
1 | [project]
2 | name = "mcp-sqlalchemy-server"
3 | version = "0.3.1"
4 | description = "A simple MCP ODBC server using FastAPI and ODBC"
5 | readme = "README.md"
6 | requires-python = ">=3.10"
7 | dependencies = [
8 | "mcp[cli]>=1.4.1",
9 | "pyodbc>=5.2.0",
10 | "python-dotenv>=1.0.1",
11 | ]
12 | [[project.authors]]
13 | name = "Sergey Malinin"
14 | email = "[email protected]"
15 |
16 | [build-system]
17 | requires = [ "hatchling",]
18 | build-backend = "hatchling.build"
19 |
20 | [project.scripts]
21 | mcp-sqlalchemy-server = "mcp_sqlalchemy_server:main"
22 |
```
--------------------------------------------------------------------------------
/mcp_sqlalchemy_server/__init__.py:
--------------------------------------------------------------------------------
```python
1 | import argparse
2 | import logging
3 | import os
4 |
5 | from .server import (
6 | podbc_get_schemas,
7 | podbc_get_tables,
8 | podbc_describe_table,
9 | podbc_filter_table_names,
10 | podbc_execute_query,
11 | podbc_execute_query_md,
12 | mcp,
13 | podbc_query_database,
14 | podbc_spasql_query,
15 | podbc_sparql_query,
16 | podbc_virtuoso_support_ai,
17 | podbc_sparql_func,
18 | podbc_sparql_get_entity_types,
19 | podbc_sparql_get_entity_types_detailed,
20 | podbc_sparql_get_entity_types_samples,
21 | podbc_sparql_get_ontologies
22 | )
23 |
24 | # Optionally expose other important items at package level
25 | __all__ = [
26 | "podbc_get_schemas",
27 | "podbc_get_tables",
28 | "podbc_describe_table",
29 | "podbc_filter_table_names",
30 | "podbc_execute_query",
31 | "podbc_execute_query_md",
32 | "podbc_query_database",
33 | "podbc_spasql_query",
34 | "podbc_sparql_query",
35 | "podbc_virtuoso_support_ai",
36 | "podbc_sparql_func",
37 | "podbc_sparql_get_entity_types",
38 | "podbc_sparql_get_entity_types_detailed",
39 | "podbc_sparql_get_entity_types_samples",
40 | "podbc_sparql_get_ontologies"
41 | ]
42 |
43 |
44 | def main():
45 | parser = argparse.ArgumentParser(description="MCP SQLAlchemy Server")
46 | parser.add_argument("--transport", type=str, default="stdio", choices=["stdio", "sse"],
47 | help="Transport mode: stdio or sse")
48 |
49 | args = parser.parse_args()
50 | logging.info(f"Starting server with transport={args.transport} ")
51 | mcp.run(transport=args.transport)
52 |
53 | if __name__ == "__main__":
54 | main()
55 |
```
--------------------------------------------------------------------------------
/mcp_sqlalchemy_server/server.py:
--------------------------------------------------------------------------------
```python
1 | from collections import defaultdict
2 | import os
3 | import logging
4 | from dotenv import load_dotenv
5 | import pyodbc
6 | from typing import Any, Dict, List, Optional
7 | import json
8 |
9 | from mcp.server.fastmcp import FastMCP
10 |
11 | # Load environment variables
12 | load_dotenv()
13 |
14 | # Configure logging
15 | logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
16 |
17 | # Retrieve database connection details from environment variables
18 | DB_UID = os.getenv("ODBC_USER")
19 | DB_PWD = os.getenv("ODBC_PASSWORD")
20 | DB_DSN = os.getenv("ODBC_DSN")
21 | MAX_LONG_DATA = int(os.getenv("MAX_LONG_DATA",4096))
22 | API_KEY = os.getenv("API_KEY", "none")
23 |
24 | ### Database ###
25 |
26 |
27 | def get_connection(readonly=True, uid: Optional[str] = None, pwd: Optional[str] = None,
28 | dsn: Optional[str] = None) -> pyodbc.Connection:
29 | dsn = DB_DSN if dsn is None else dsn
30 | uid = DB_UID if uid is None else uid
31 | pwd = DB_PWD if pwd is None else pwd
32 |
33 | if dsn is None:
34 | raise ValueError("ODBC_DSN environment variable is not set.")
35 | if uid is None:
36 | raise ValueError("ODBC_USER environment variable is not set.")
37 | if pwd is None:
38 | raise ValueError("ODBC_PASSWORD environment variable is not set.")
39 |
40 | dsn_string = f"DSN={dsn};UID={uid};PWD={pwd}"
41 | logging.info(f"DSN:{dsn} UID:{uid}")
42 | # connection_string="DSN=VOS;UID=dba;PWD=dba"
43 |
44 | return pyodbc.connect(dsn_string, autocommit=True, readonly=readonly)
45 |
46 |
47 | ### Constants ###
48 |
49 |
50 | ### MCP ###
51 | mcp = FastMCP('mcp-sqlalchemy-server', transport=["stdio", "sse"])
52 |
53 | @mcp.tool(
54 | name="podbc_get_schemas",
55 | description="Retrieve and return a list of all schema names from the connected database."
56 | )
57 | def podbc_get_schemas(user:Optional[str]=None, password:Optional[str]=None, dsn:Optional[str]=None) -> str:
58 | """
59 | Retrieve and return a list of all schema names from the connected database.
60 |
61 | Args:
62 | user (Optional[str]=None): Optional username.
63 | password (Optional[str]=None): Optional password.
64 | dsn (Optional[str]=None): Optional dsn name.
65 |
66 | Returns:
67 | str: A list of schema names.
68 | """
69 | try:
70 | with get_connection(True, user, password, dsn) as conn:
71 | cursor = conn.cursor()
72 | rs = cursor.tables(table=None, catalog="%", schema=None, tableType=None);
73 | catalogs = {row[0] for row in rs.fetchall()}
74 | return json.dumps(list(catalogs))
75 |
76 | except pyodbc.Error as e:
77 | logging.error(f"Error retrieving schemas: {e}")
78 | raise
79 |
80 |
81 | @mcp.tool(
82 | name="podbc_get_tables",
83 | description="Retrieve and return a list containing information about tables in specified schema, if empty uses connection default"
84 | )
85 | def podbc_get_tables(Schema: Optional[str] = None, user:Optional[str]=None,
86 | password:Optional[str]=None, dsn:Optional[str]=None) -> str:
87 | """
88 | Retrieve and return a list containing information about tables.
89 |
90 | If `schema` is None, returns tables for all schemas.
91 | If `schema` is not None, returns tables for the specified schema.
92 |
93 | Args:
94 | schema (Optional[str]): The name of the schema to retrieve tables for. If None, retrieves tables for all schemas.
95 | user (Optional[str]=None): Optional username.
96 | password (Optional[str]=None): Optional password.
97 | dsn (Optional[str]=None): Optional dsn name.
98 |
99 | Returns:
100 | str: A list containing information about tables.
101 | """
102 | cat = "%" if Schema is None else Schema
103 | try:
104 | with get_connection(True, user, password, dsn) as conn:
105 | cursor = conn.cursor()
106 | rs = cursor.tables(table=None, catalog=cat, schema="%", tableType="TABLE");
107 | results = []
108 | for row in rs:
109 | results.append({"TABLE_CAT":row[0], "TABLE_SCHEM":row[1], "TABLE_NAME":row[2]})
110 |
111 | return json.dumps(results, indent=2)
112 | except pyodbc.Error as e:
113 | logging.error(f"Error retrieving tables: {e}")
114 | raise
115 |
116 |
117 | @mcp.tool(
118 | name="podbc_describe_table",
119 | description="Retrieve and return a dictionary containing the definition of a table, including column names, data types, nullable,"
120 | " autoincrement, primary key, and foreign keys."
121 | )
122 | def podbc_describe_table(Schema:str, table: str, user:Optional[str]=None,
123 | password:Optional[str]=None, dsn:Optional[str]=None) -> str:
124 | """
125 | Retrieve and return a dictionary containing the definition of a table, including column names, data types, nullable, autoincrement, primary key, and foreign keys.
126 |
127 | If `schema` is None, returns the table definition for the specified table in all schemas.
128 | If `schema` is not None, returns the table definition for the specified table in the specified schema.
129 |
130 | Args:
131 | schema (str): The name of the schema to retrieve the table definition for. If None, retrieves the table definition for all schemas.
132 | table (str): The name of the table to retrieve the definition for.
133 | user (Optional[str]=None): Optional username.
134 | password (Optional[str]=None): Optional password.
135 | dsn (Optional[str]=None): Optional dsn name.
136 |
137 | Returns:
138 | str: A dictionary containing the table definition, including column names, data types, nullable, autoincrement, primary key, and foreign keys.
139 | """
140 | cat = "%" if Schema is None else Schema
141 | table_definition = {}
142 | try:
143 | with get_connection(True, user, password, dsn) as conn:
144 | rc, tbl = _has_table(conn, cat=cat, table=table)
145 | if rc:
146 | table_definition = _get_table_info(conn, cat=tbl.get("cat"), sch=tbl.get("sch"), table=tbl.get("name"))
147 |
148 | return json.dumps(table_definition, indent=2)
149 |
150 | except pyodbc.Error as e:
151 | logging.error(f"Error retrieving table definition: {e}")
152 | raise
153 |
154 |
155 | def _has_table(conn, cat:str, table:str):
156 | with conn.cursor() as cursor:
157 | row = cursor.tables(table=table, catalog=cat, schema=None, tableType=None).fetchone()
158 | if row:
159 | return True, {"cat":row[0], "sch": row[1], "name":row[2]}
160 | else:
161 | return False, {}
162 |
163 |
164 | def _get_columns(conn, cat: str, sch: str, table:str):
165 | with conn.cursor() as cursor:
166 | ret = []
167 | for row in cursor.columns(table=table, catalog=cat, schema=sch):
168 | ret.append({
169 | "name":row[3],
170 | "type":row[5],
171 | "column_size": row[6],
172 | # "decimal_digits":row[8],
173 | "num_prec_radix":row[9],
174 | "nullable":False if row[10]==0 else True,
175 | "default":row[12]
176 | })
177 | return ret
178 |
179 |
180 | def _get_pk_constraint(conn, cat: str, sch: str, table:str):
181 | with conn.cursor() as cursor:
182 | ret = None
183 | rs = cursor.primaryKeys(table=table, catalog=cat, schema=sch).fetchall()
184 | if len(rs) > 0:
185 | ret = { "constrained_columns": [row[3] for row in rs],
186 | "name": rs[0][5]
187 | }
188 | return ret
189 |
190 |
191 | def _get_foreign_keys(conn, cat: str, sch: str, table:str):
192 | def fkey_rec():
193 | return {
194 | "name": None,
195 | "constrained_columns": [],
196 | "referred_cat": None,
197 | "referred_schem": None,
198 | "referred_table": None,
199 | "referred_columns": [],
200 | "options": {},
201 | }
202 |
203 | fkeys = defaultdict(fkey_rec)
204 | with conn.cursor() as cursor:
205 | rs = cursor.foreignKeys(foreignTable=table, foreignCatalog=cat, foreignSchema=sch)
206 | for row in rs:
207 | rec = fkeys[row[11]] #.FK_NAME
208 | rec["name"] = row[11] #.FK_NAME
209 |
210 | c_cols = rec["constrained_columns"]
211 | c_cols.append(row[7]) #.FKCOLUMN_NAME)
212 |
213 | r_cols = rec["referred_columns"]
214 | r_cols.append(row[3]) #.PKCOLUMN_NAME)
215 |
216 | if not rec["referred_table"]:
217 | rec["referred_table"] = row[2] #.PKTABLE_NAME
218 | rec["referred_schem"] = row[1] #.PKTABLE_OWNER
219 | rec["referred_cat"] = row[0] #.PKTABLE_CAT
220 |
221 | return list(fkeys.values())
222 |
223 |
224 | def _get_table_info(conn, cat:str, sch: str, table: str) -> Dict[str, Any]:
225 | try:
226 | columns = _get_columns(conn, cat=cat, sch=sch, table=table)
227 | primary_keys = _get_pk_constraint(conn, cat=cat, sch=sch, table=table)['constrained_columns']
228 | foreign_keys = _get_foreign_keys(conn, cat=cat, sch=sch, table=table)
229 |
230 | table_info = {
231 | "TABLE_CAT": cat,
232 | "TABLE_SCHEM": sch,
233 | "TABLE_NAME": table,
234 | "columns": columns,
235 | "primary_keys": primary_keys,
236 | "foreign_keys": foreign_keys
237 | }
238 |
239 | for column in columns:
240 | column["primary_key"] = column['name'] in primary_keys
241 |
242 | return table_info
243 |
244 | except pyodbc.Error as e:
245 | logging.error(f"Error retrieving table info: {e}")
246 | raise
247 |
248 |
249 | @mcp.tool(
250 | name="podbc_filter_table_names",
251 | description="Retrieve and return a list containing information about tables whose names contain the substring 'q' ."
252 | )
253 | def podbc_filter_table_names(q: str, Schema: Optional[str] = None, user:Optional[str]=None, password:Optional[str]=None,
254 | dsn:Optional[str]=None) -> str:
255 | """
256 | Retrieve and return a list containing information about tables whose names contain the substring 'q'
257 |
258 | Args:
259 | q (str): The substring to filter table names by.
260 | user (Optional[str]=None): Optional username.
261 | password (Optional[str]=None): Optional password.
262 | dsn (Optional[str]=None): Optional dsn name.
263 |
264 | Returns:
265 | str: A list containing information about tables whose names contain the substring 'q'.
266 | """
267 | cat = "%" if Schema is None else Schema
268 | try:
269 | with get_connection(True, user, password, dsn) as conn:
270 | cursor = conn.cursor()
271 | rs = cursor.tables(table=None, catalog=cat, schema='%', tableType="TABLE");
272 | results = []
273 | for row in rs:
274 | if q in row[2]:
275 | results.append({"TABLE_CAT":row[0], "TABLE_SCHEM":row[1], "TABLE_NAME":row[2]})
276 |
277 | return json.dumps(results, indent=2)
278 | except pyodbc.Error as e:
279 | logging.error(f"Error filtering table names: {e}")
280 | raise
281 |
282 |
283 | @mcp.tool(
284 | name="podbc_execute_query",
285 | description="Execute a SQL query and return results in JSONL format."
286 | )
287 | def podbc_execute_query(query: str, max_rows: int = 100, params: Optional[Dict[str, Any]] = None,
288 | user:Optional[str]=None, password:Optional[str]=None, dsn:Optional[str]=None) -> str:
289 | """
290 | Execute a SQL query and return results in JSONL format.
291 |
292 | Args:
293 | query (str): The SQL query to execute.
294 | max_rows (int): Maximum number of rows to return. Default is 100.
295 | params (Optional[Dict[str, Any]]): Optional dictionary of parameters to pass to the query.
296 | user (Optional[str]=None): Optional username.
297 | password (Optional[str]=None): Optional password.
298 | dsn (Optional[str]=None): Optional dsn name.
299 |
300 | Returns:
301 | str: Results in JSONL format.
302 | """
303 | try:
304 | with get_connection(True, user, password, dsn) as conn:
305 | cursor = conn.cursor()
306 | rs = cursor.execute(query) if params is None else cursor.execute(query, params)
307 | columns = [column[0] for column in rs.description]
308 | results = []
309 | for row in rs:
310 | rs_dict = dict(zip(columns, row))
311 | truncated_row = {key: (str(value)[:MAX_LONG_DATA] if value is not None else None) for key, value in rs_dict.items()}
312 | results.append(truncated_row)
313 | if len(results) >= max_rows:
314 | break
315 |
316 | # Convert the results to JSONL format
317 | jsonl_results = "\n".join(json.dumps(row) for row in results)
318 |
319 | # Return the JSONL formatted results
320 | return jsonl_results
321 | except pyodbc.Error as e:
322 | logging.error(f"Error executing query: {e}")
323 | raise
324 |
325 |
326 | @mcp.tool(
327 | name="podbc_execute_query_md",
328 | description="Execute a SQL query and return results in Markdown table format."
329 | )
330 | def podbc_execute_query_md(query: str, max_rows: int = 100, params: Optional[Dict[str, Any]] = None,
331 | user:Optional[str]=None, password:Optional[str]=None, dsn:Optional[str]=None) -> str:
332 | """
333 | Execute a SQL query and return results in Markdown table format.
334 |
335 | Args:
336 | query (str): The SQL query to execute.
337 | max_rows (int): Maximum number of rows to return. Default is 100.
338 | params (Optional[Dict[str, Any]]): Optional dictionary of parameters to pass to the query.
339 | user (Optional[str]=None): Optional username.
340 | password (Optional[str]=None): Optional password.
341 | dsn (Optional[str]=None): Optional dsn name.
342 |
343 | Returns:
344 | str: Results in Markdown table format.
345 | """
346 | try:
347 | with get_connection(True, user, password, dsn) as conn:
348 | cursor = conn.cursor()
349 | rs = cursor.execute(query) if params is None else cursor.execute(query, params)
350 | columns = [column[0] for column in rs.description]
351 | results = []
352 | for row in rs:
353 | rs_dict = dict(zip(columns, row))
354 | truncated_row = {key: (str(value)[:MAX_LONG_DATA] if value is not None else None) for key, value in rs_dict.items()}
355 | results.append(truncated_row)
356 | if len(results) >= max_rows:
357 | break
358 |
359 | # Create the Markdown table header
360 | md_table = "| " + " | ".join(columns) + " |\n"
361 | md_table += "| " + " | ".join(["---"] * len(columns)) + " |\n"
362 |
363 | # Add rows to the Markdown table
364 | for row in results:
365 | md_table += "| " + " | ".join(str(row[col]) for col in columns) + " |\n"
366 |
367 | # Return the Markdown formatted results
368 | return md_table
369 |
370 | except pyodbc.Error as e:
371 | logging.error(f"Error executing query: {e}")
372 | raise
373 |
374 |
375 | @mcp.tool(
376 | name="podbc_query_database",
377 | description="Execute a SQL query and return results in JSONL format."
378 | )
379 | def podbc_query_database(query: str, user:Optional[str]=None, password:Optional[str]=None,
380 | dsn:Optional[str]=None) -> str:
381 | """
382 | Execute a SQL query and return results in JSONL format.
383 |
384 | Args:
385 | query (str): The SQL query to execute.
386 | user (Optional[str]=None): Optional username.
387 | password (Optional[str]=None): Optional password.
388 | dsn (Optional[str]=None): Optional dsn name.
389 |
390 | Returns:
391 | str: Results in JSONL format.
392 | """
393 | try:
394 | with get_connection(True, user, password, dsn) as conn:
395 | cursor = conn.cursor()
396 | rs = cursor.execute(query)
397 | columns = [column[0] for column in rs.description]
398 | results = []
399 | for row in rs:
400 | rs_dict = dict(zip(columns, row))
401 | truncated_row = {key: (str(value)[:MAX_LONG_DATA] if value is not None else None) for key, value in rs_dict.items()}
402 | results.append(truncated_row)
403 |
404 | # Convert the results to JSONL format
405 | jsonl_results = "\n".join(json.dumps(row) for row in results)
406 |
407 | # Return the JSONL formatted results
408 | return jsonl_results
409 | except pyodbc.Error as e:
410 | logging.error(f"Error executing query: {e}")
411 | raise
412 |
413 |
414 | @mcp.tool(
415 | name="podbc_spasql_query",
416 | description="Execute a SPASQL query and return results."
417 | )
418 | def podbc_spasql_query(query: str, max_rows:Optional[int] = 20, timeout:Optional[int] = 300000,
419 | user:Optional[str]=None, password:Optional[str]=None, dsn:Optional[str]=None) -> str:
420 | """
421 | Execute a SPASQL query and return results in JSONL format.
422 |
423 | Args:
424 | query (str): The SPASQL query to execute.
425 | max_rows (int): Maximum number of rows to return. Default is 100.
426 | timeout (int): Query timeout. Default is 30000ms.
427 | user (Optional[str]=None): Optional username.
428 | password (Optional[str]=None): Optional password.
429 | dsn (Optional[str]=None): Optional dsn name.
430 |
431 | Returns:
432 | str: Results in requested format as string.
433 | """
434 | try:
435 | with get_connection(True, user, password, dsn) as conn:
436 | cursor = conn.cursor()
437 | cmd = f"select Demo.demo.execute_spasql_query(charset_recode(?, '_WIDE_', 'UTF-8'), ?, ?) as result"
438 | rs = cursor.execute(cmd, (query, max_rows, timeout,)).fetchone()
439 | return rs[0]
440 | except pyodbc.Error as e:
441 | logging.error(f"Error executing query: {e}")
442 | raise
443 |
444 |
445 | @mcp.tool(
446 | name="podbc_virtuoso_support_ai",
447 | description="Tool to use the Virtuoso AI support function"
448 | )
449 | def podbc_virtuoso_support_ai(prompt: str, api_key:Optional[str]=None, user:Optional[str]=None,
450 | password:Optional[str]=None, dsn:Optional[str]=None) -> str:
451 | """
452 | Tool to use the Virtuoso AI support function
453 |
454 | Args:
455 | prompt (str): AI prompt text (required).
456 | api_key (str): API key for AI service (optional).
457 | user (Optional[str]=None): Optional username.
458 | password (Optional[str]=None): Optional password.
459 | dsn (Optional[str]=None): Optional dsn name.
460 |
461 | Returns:
462 | str: Results data in JSON.
463 | """
464 | try:
465 | _api_key = api_key if api_key is not None else API_KEY
466 | with get_connection(True, user, password, dsn) as conn:
467 | cursor = conn.cursor()
468 | cmd = f"select DEMO.DBA.OAI_VIRTUOSO_SUPPORT_AI(?, ?) as result"
469 | rs = cursor.execute(cmd, (prompt, _api_key,)).fetchone()
470 | return rs[0]
471 | except pyodbc.Error as e:
472 | logging.error(f"Error executing request")
473 | raise pyodbc.Error("Error executing request")
474 |
475 |
476 | @mcp.tool(
477 | name="podbc_sparql_func",
478 | description="Tool to use the SPARQL AI support function"
479 | )
480 | def podbc_sparql_func(prompt: str, api_key:Optional[str]=None, user:Optional[str]=None,
481 | password:Optional[str]=None, dsn:Optional[str]=None) -> str:
482 | """
483 | Call SPARQL AI func.
484 |
485 | Args:
486 | prompt (str): The prompt.
487 | api_key (str): optional.
488 | user (Optional[str]=None): Optional username.
489 | password (Optional[str]=None): Optional password.
490 | dsn (Optional[str]=None): Optional dsn name.
491 |
492 | Returns:
493 | str: Results data in JSON.
494 | """
495 | try:
496 | _api_key = api_key if api_key is not None else API_KEY
497 | with get_connection(True, user, password, dsn) as conn:
498 | cursor = conn.cursor()
499 | cmd = f"select DEMO.DBA.OAI_SPARQL_FUNC(?, ?) as result"
500 | rs = cursor.execute(cmd, (prompt, _api_key,)).fetchone()
501 | return rs[0]
502 | except pyodbc.Error as e:
503 | logging.error(f"Error executing request")
504 | raise pyodbc.Error("Error executing request")
505 |
506 |
507 | def _exec_sparql(query: str, format:Optional[str]="json", timeout:Optional[int]= 300000,
508 | user:Optional[str]=None, password:Optional[str]=None, dsn:Optional[str]=None) -> str:
509 | timeout = 30000
510 | format = "json"
511 | try:
512 | with get_connection(True, user, password, dsn) as conn:
513 | cursor = conn.cursor()
514 | cmd = f"select Demo.demo.execute_spasql_query(charset_recode(?, '_WIDE_', 'UTF-8'), ?, ?) as result"
515 | rs = cursor.execute(cmd, (query, format, timeout,)).fetchone()
516 | return rs[0]
517 | except pyodbc.Error as e:
518 | logging.error(f"Error executing query: {e}")
519 | raise
520 |
521 |
522 |
523 | @mcp.tool(
524 | name="podbc_sparql_get_entity_types",
525 | description="This query retrieves all entity types in the RDF graph, along with their labels and comments if available. "
526 | "It filters out blank nodes and ensures that only IRI types are returned. "
527 | "The LIMIT clause is set to 100 to restrict the number of entity types returned. "
528 | )
529 | def podbc_sparql_get_entity_types(user:Optional[str]=None, password:Optional[str]=None, dsn:Optional[str]=None) -> str:
530 | """
531 | Execute a SPARQL query and return results.
532 |
533 | Args:
534 | user (Optional[str]=None): Optional username.
535 | password (Optional[str]=None): Optional password.
536 | dsn (Optional[str]=None): Optional dsn name.
537 |
538 | Returns:
539 | str: Results in requested format as string.
540 | """
541 |
542 | query = """
543 | SELECT DISTINCT * FROM (
544 | SPARQL
545 | PREFIX owl: <http://www.w3.org/2002/07/owl#>
546 | PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
547 | PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
548 | SELECT ?o
549 | WHERE {
550 | GRAPH ?g {
551 | ?s a ?o .
552 |
553 | OPTIONAL {
554 | ?s rdfs:label ?label .
555 | FILTER (LANG(?label) = "en" || LANG(?label) = "")
556 | }
557 |
558 | OPTIONAL {
559 | ?s rdfs:comment ?comment .
560 | FILTER (LANG(?comment) = "en" || LANG(?comment) = "")
561 | }
562 |
563 | FILTER (isIRI(?o) && !isBlank(?o))
564 | }
565 | }
566 | LIMIT 100
567 | ) AS x
568 | """
569 | return podbc_query_database(query, user=user, password=password, dsn=dsn)
570 |
571 |
572 | @mcp.tool(
573 | name="podbc_sparql_get_entity_types_detailed",
574 | description="This query retrieves all entity types in the RDF graph, along with their labels and comments if available. "
575 | "It filters out blank nodes and ensures that only IRI types are returned. "
576 | "The LIMIT clause is set to 100 to restrict the number of entity types returned."
577 | )
578 | def podbc_sparql_get_entity_types_detailed(user:Optional[str]=None, password:Optional[str]=None, dsn:Optional[str]=None) -> str:
579 | """
580 | Execute a SPARQL query and return results.
581 |
582 | Args:
583 | user (Optional[str]=None): Optional username.
584 | password (Optional[str]=None): Optional password.
585 | dsn (Optional[str]=None): Optional dsn name.
586 |
587 | Returns:
588 | str: Results in requested format as string.
589 | """
590 |
591 | query = """
592 | SELECT * FROM (
593 | SPARQL
594 | PREFIX owl: <http://www.w3.org/2002/07/owl#>
595 | PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
596 | PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
597 |
598 | SELECT ?o, (SAMPLE(?label) AS ?label), (SAMPLE(?comment) AS ?comment)
599 | WHERE {
600 | GRAPH ?g {
601 | ?s a ?o .
602 | OPTIONAL {?o rdfs:label ?label . FILTER (LANG(?label) = "en" || LANG(?label) = "")}
603 | OPTIONAL {?o rdfs:comment ?comment . FILTER (LANG(?comment) = "en" || LANG(?comment) = "")}
604 | FILTER (isIRI(?o) && !isBlank(?o))
605 | }
606 | }
607 | GROUP BY ?o
608 | ORDER BY ?o
609 | LIMIT 20
610 | ) AS results
611 | """
612 | return podbc_query_database(query, user=user, password=password, dsn=dsn)
613 |
614 |
615 | @mcp.tool(
616 | name="podbc_sparql_get_entity_types_samples",
617 | description="This query retrieves samples of entities for each type in the RDF graph, along with their labels and counts. "
618 | "It groups by entity type and orders the results by sample count in descending order. "
619 | "Note: The LIMIT clause is set to 20 to restrict the number of entity types returned."
620 | )
621 | def podbc_sparql_get_entity_types_samples(user:Optional[str]=None, password:Optional[str]=None, dsn:Optional[str]=None) -> str:
622 | """
623 | Execute a SPARQL query and return results.
624 |
625 | Args:
626 | user (Optional[str]=None): Optional username.
627 | password (Optional[str]=None): Optional password.
628 | dsn (Optional[str]=None): Optional dsn name.
629 |
630 | Returns:
631 | str: Results in requested format as string.
632 | """
633 |
634 | query = """
635 | SELECT * FROM (
636 | SPARQL
637 | PREFIX owl: <http://www.w3.org/2002/07/owl#>
638 | PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
639 | PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
640 | SELECT (SAMPLE(?s) AS ?sample), ?slabel, (COUNT(*) AS ?sampleCount), (?o AS ?entityType), ?olabel
641 | WHERE {
642 | GRAPH ?g {
643 | ?s a ?o .
644 | OPTIONAL {?s rdfs:label ?slabel . FILTER (LANG(?slabel) = \"en\" || LANG(?slabel) = \"\")}
645 | FILTER (isIRI(?s) && !isBlank(?s))
646 | OPTIONAL {?o rdfs:label ?olabel . FILTER (LANG(?olabel) = \"en\" || LANG(?olabel) = \"\")}
647 | FILTER (isIRI(?o) && !isBlank(?o))
648 | }
649 | }
650 | GROUP BY ?slabel ?o ?olabel
651 | ORDER BY DESC(?sampleCount) ?o ?slabel ?olabel
652 | LIMIT 20
653 | ) AS results
654 | """
655 | return podbc_query_database(query, user=user, password=password, dsn=dsn)
656 |
657 |
658 | @mcp.tool(
659 | name="podbc_sparql_get_ontologies",
660 | description="This query retrieves all ontologies in the RDF graph, along with their labels and comments if available."
661 | )
662 | def podbc_sparql_get_ontologies(user:Optional[str]=None, password:Optional[str]=None, dsn:Optional[str]=None) -> str:
663 | """
664 | Execute a SPARQL query and return results.
665 |
666 | Args:
667 | user (Optional[str]=None): Optional username.
668 | password (Optional[str]=None): Optional password.
669 | dsn (Optional[str]=None): Optional dsn name.
670 |
671 | Returns:
672 | str: Results in requested format as string.
673 | """
674 |
675 | query = """
676 | SELECT * FROM (
677 | SPARQL
678 | PREFIX owl: <http://www.w3.org/2002/07/owl#>
679 | PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
680 | PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
681 | SELECT ?s, ?label, ?comment
682 | WHERE {
683 | GRAPH ?g {
684 | ?s a owl:Ontology .
685 |
686 | OPTIONAL {
687 | ?s rdfs:label ?label .
688 | FILTER (LANG(?label) = "en" || LANG(?label) = "")
689 | }
690 |
691 | OPTIONAL {
692 | ?s rdfs:comment ?comment .
693 | FILTER (LANG(?comment) = "en" || LANG(?comment) = "")
694 | }
695 |
696 | FILTER (isIRI(?o) && !isBlank(?o))
697 | }
698 | }
699 | LIMIT 100
700 | ) AS x
701 | """
702 | return podbc_query_database(query, user=user, password=password, dsn=dsn)
703 |
704 |
705 |
706 | if __name__ == "__main__":
707 | mcp.run()
708 |
```