# Directory Structure
```
├── .gitignore
├── build.sh
├── install.sh
├── LICENSE
├── pyproject.toml
├── README.md
├── setup.py
├── src
│ └── mcp_server_deep_research
│ ├── __init__.py
│ └── server.py
└── uv.lock
```
# Files
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
```
# Python specific
__pycache__/
*.py[cod]
*$py.class
*.so
.Python
env/
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
*.egg-info/
.installed.cfg
*.egg
.pytest_cache/
.coverage
htmlcov/
.tox/
.nox/
# Virtual Environment
venv/
ENV/
env/
.env/
# IDE specific files
.idea/
.vscode/
*.swp
*.swo
.DS_Store
# Project specific
.cache/
logs/
*.log
```
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
```markdown
# MCP Server for Deep Research
MCP Server for Deep Research is a tool designed for conducting comprehensive research on complex topics. It helps you explore questions in depth, find relevant sources, and generate structured research reports.
Your personal Research Assistant, turning research questions into comprehensive, well-cited reports.
## 🚀 Try it Out
[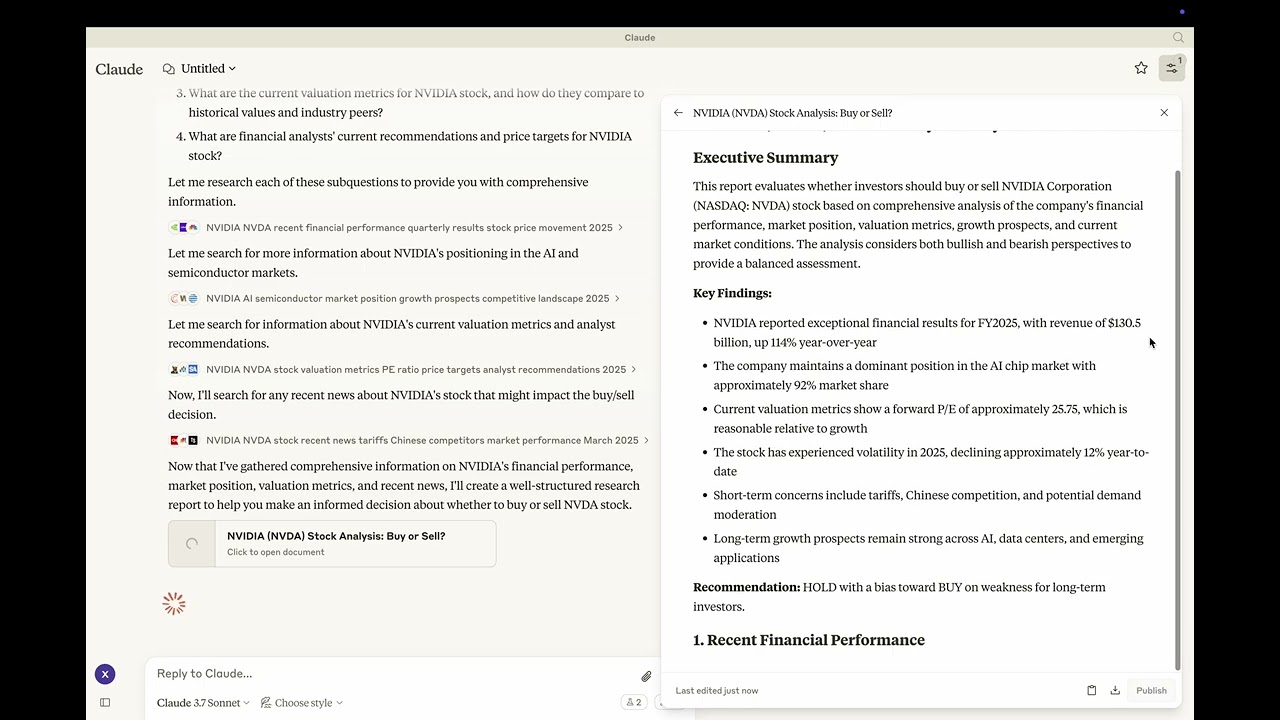]([VIDEO_URL](https://youtu.be/_a7sfo5yxoI))
Youtube: https://youtu.be/_a7sfo5yxoI
1. **Download Claude Desktop**
- Get it [here](https://claude.ai/download)
2. **Install and Set Up**
- On macOS, run the following command in your terminal:
```bash
python setup.py
```
3. **Start Researching**
- Select the deep-research prompt template from MCP
- Begin your research by providing a research question
## Features
The Deep Research MCP Server offers a complete research workflow:
1. **Question Elaboration**
- Expands and clarifies your research question
- Identifies key terms and concepts
- Defines scope and parameters
2. **Subquestion Generation**
- Creates focused subquestions that address different aspects
- Ensures comprehensive coverage of the main topic
- Provides structure for systematic research
3. **Web Search Integration**
- Uses Claude's built-in web search capabilities
- Performs targeted searches for each subquestion
- Identifies relevant and authoritative sources
- Collects diverse perspectives on the topic
4. **Content Analysis**
- Evaluates information quality and relevance
- Synthesizes findings from multiple sources
- Provides proper citations for all sources
5. **Report Generation**
- Creates well-structured, comprehensive reports as artifacts
- Properly cites all sources used
- Presents a balanced view with evidence-based conclusions
- Uses appropriate formatting for clarity and readability
## 📦 Components
### Prompts
- **deep-research**: Tailored for comprehensive research tasks with a structured approach
## ⚙️ Modifying the Server
### Claude Desktop Configurations
- macOS: `~/Library/Application\ Support/Claude/claude_desktop_config.json`
- Windows: `%APPDATA%/Claude/claude_desktop_config.json`
### Development (Unpublished Servers)
```json
"mcpServers": {
"mcp-server-deep-research": {
"command": "uv",
"args": [
"--directory",
"/Users/username/repos/mcp-server-application/mcp-server-deep-research",
"run",
"mcp-server-deep-research"
]
}
}
```
### Published Servers
```json
"mcpServers": {
"mcp-server-deep-research": {
"command": "uvx",
"args": [
"mcp-server-deep-research"
]
}
}
```
## 🛠️ Development
### Building and Publishing
1. **Sync Dependencies**
```bash
uv sync
```
2. **Build Distributions**
```bash
uv build
```
Generates source and wheel distributions in the dist/ directory.
3. **Publish to PyPI**
```bash
uv publish
```
## 🤝 Contributing
Contributions are welcome! Whether you're fixing bugs, adding features, or improving documentation, your help makes this project better.
## 📜 License
This project is licensed under the MIT License.
See the LICENSE file for details.
```
--------------------------------------------------------------------------------
/src/mcp_server_deep_research/__init__.py:
--------------------------------------------------------------------------------
```python
from . import server
import asyncio
def main():
"""Main entry point for the package."""
asyncio.run(server.main())
# Optionally expose other important items at package level
__all__ = ['main', 'server']
```
--------------------------------------------------------------------------------
/build.sh:
--------------------------------------------------------------------------------
```bash
#!/bin/bash
# Build script for the MCP server deep research package
echo "Building mcp-server-deep-research package..."
cd /Users/hezhang/repos/mcp-server-application/mcp-server-deep-research
uv build
echo "Done building. The wheel file should be in the dist/ directory."
ls -la dist/
```
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
```toml
[project]
name = "mcp-server-deep-research"
version = "0.1.1"
description = "A MCP server for deep research and report generation"
readme = "README.md"
requires-python = ">=3.10"
dependencies = [
"mcp>=1.0.0",
]
[[project.authors]]
name = "Xing Xing"
email = "[email protected]"
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
[project.scripts]
mcp-server-deep-research = "mcp_server_deep_research:main"
```
--------------------------------------------------------------------------------
/install.sh:
--------------------------------------------------------------------------------
```bash
#!/bin/bash
# Install script for the MCP server deep research package
echo "Finding the latest wheel file..."
WHEEL_FILE=$(ls -t /Users/hezhang/repos/mcp-server-application/mcp-server-deep-research/dist/*.whl | head -1)
if [ -z "$WHEEL_FILE" ]; then
echo "No wheel file found. Please run build.sh first."
exit 1
fi
echo "Installing wheel file: $WHEEL_FILE"
uv pip install --force-reinstall $WHEEL_FILE
echo "Creating/updating Claude desktop config..."
CONFIG_DIR="$HOME/Library/Application Support/Claude"
CONFIG_FILE="$CONFIG_DIR/claude_desktop_config.json"
# Create directory if it doesn't exist
mkdir -p "$CONFIG_DIR"
# Create or update config file
if [ -f "$CONFIG_FILE" ]; then
# Update existing config
echo "Updating existing Claude config..."
# Check if jq is installed
if ! command -v jq &> /dev/null; then
echo "jq is not installed. Creating a new config file..."
cat > "$CONFIG_FILE" << EOF
{
"mcpServers": {
"mcp-server-deep-research": {
"command": "mcp-server-deep-research"
}
}
}
EOF
else
# Use jq to update config
jq '.mcpServers."mcp-server-deep-research" = {"command": "mcp-server-deep-research"}' "$CONFIG_FILE" > "$CONFIG_FILE.tmp" && mv "$CONFIG_FILE.tmp" "$CONFIG_FILE"
fi
else
# Create new config file
echo "Creating new Claude config file..."
cat > "$CONFIG_FILE" << EOF
{
"mcpServers": {
"mcp-server-deep-research": {
"command": "mcp-server-deep-research"
}
}
}
EOF
fi
echo "Installation complete. Restart Claude to use the updated server."
```
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
```python
#!/usr/bin/env python3
"""Setup script for MCP server deep research environment."""
import json
import subprocess
import sys
from pathlib import Path
import re
import time
def run_command(cmd, check=True):
"""Run a shell command and return output."""
try:
result = subprocess.run(
cmd, shell=True, check=check, capture_output=True, text=True
)
return result.stdout.strip()
except subprocess.CalledProcessError as e:
print(f"Error running command '{cmd}': {e}")
return None
def ask_permission(question):
"""Ask user for permission."""
while True:
response = input(f"{question} (y/n): ").lower()
if response in ["y", "yes"]:
return True
if response in ["n", "no"]:
return False
print("Please answer 'y' or 'n'")
def check_uv():
"""Check if uv is installed and install if needed."""
if not run_command("which uv", check=False):
if ask_permission("uv is not installed. Would you like to install it?"):
print("Installing uv...")
run_command("curl -LsSf https://astral.sh/uv/install.sh | sh")
print("uv installed successfully")
else:
sys.exit("uv is required to continue")
def setup_venv():
"""Create virtual environment if it doesn't exist."""
if not Path(".venv").exists():
if ask_permission("Virtual environment not found. Create one?"):
print("Creating virtual environment...")
run_command("uv venv")
print("Virtual environment created successfully")
else:
sys.exit("Virtual environment is required to continue")
def sync_dependencies():
"""Sync project dependencies."""
print("Syncing dependencies...")
run_command("uv sync")
print("Dependencies synced successfully")
def check_claude_desktop():
"""Check if Claude desktop app is installed."""
app_path = "/Applications/Claude.app"
if not Path(app_path).exists():
print("Claude desktop app not found.")
print("Please download and install from: https://claude.ai/download")
if not ask_permission("Continue after installing Claude?"):
sys.exit("Claude desktop app is required to continue")
def setup_claude_config():
"""Setup Claude desktop config file."""
config_path = Path(
"~/Library/Application Support/Claude/claude_desktop_config.json"
).expanduser()
config_dir = config_path.parent
if not config_dir.exists():
config_dir.mkdir(parents=True)
config = (
{"mcpServers": {}}
if not config_path.exists()
else json.loads(config_path.read_text())
)
return config_path, config
def build_package():
"""Build package and get wheel path."""
print("Building package...")
try:
# Use Popen for real-time and complete output capture
process = subprocess.Popen(
"uv build",
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
)
stdout, stderr = process.communicate() # Capture output
output = stdout + stderr # Combine both streams
print(f"Raw output: {output}") # Debug: check output
except Exception as e:
sys.exit(f"Error running build: {str(e)}")
# Check if the command was successful
if process.returncode != 0:
sys.exit(f"Build failed with error code {process.returncode}")
# Extract wheel file path from the combined output
match = re.findall(r"dist/[^\s]+\.whl", output.strip())
whl_file = match[-1] if match else None
if not whl_file:
sys.exit("Failed to find wheel file in build output")
# Convert to absolute path
path = Path(whl_file).absolute()
return str(path)
def update_config(config_path, config, wheel_path):
"""Update Claude config with MCP server settings."""
config.setdefault("mcpServers", {})
config["mcpServers"]["mcp-server-deep-research"] = {
"command": "uvx",
"args": ["--from", wheel_path, "mcp-server-deep-research"],
}
config_path.write_text(json.dumps(config, indent=2))
print(f"Updated config at {config_path}")
def restart_claude():
"""Restart Claude desktop app if running."""
if run_command("pgrep -x Claude", check=False):
if ask_permission("Claude is running. Restart it?"):
print("Restarting Claude...")
run_command("pkill -x Claude")
time.sleep(2)
run_command("open -a Claude")
print("Claude restarted successfully")
else:
print("Starting Claude...")
run_command("open -a Claude")
def main():
"""Main setup function."""
print("Starting setup...")
check_uv()
setup_venv()
sync_dependencies()
check_claude_desktop()
config_path, config = setup_claude_config()
wheel_path = build_package()
update_config(config_path, config, wheel_path)
restart_claude()
print("Setup completed successfully!")
if __name__ == "__main__":
main()
```
--------------------------------------------------------------------------------
/src/mcp_server_deep_research/server.py:
--------------------------------------------------------------------------------
```python
from enum import Enum
import logging
from typing import Any
import json
# Import MCP server
from mcp.server.models import InitializationOptions
from mcp.types import (
TextContent,
Tool,
Resource,
Prompt,
PromptArgument,
GetPromptResult,
PromptMessage,
)
from mcp.server import NotificationOptions, Server
from pydantic import AnyUrl
import mcp.server.stdio
logger = logging.getLogger(__name__)
logger.info("Starting deep research server")
### Prompt templates
class DeepResearchPrompts(str, Enum):
DEEP_RESEARCH = "deep-research"
class PromptArgs(str, Enum):
RESEARCH_QUESTION = "research_question"
PROMPT_TEMPLATE = """
You are a professional researcher tasked with conducting thorough research on a topic and producing a structured, comprehensive report. Your goal is to provide a detailed analysis that addresses the research question systematically.
The research question is:
<research_question>
{research_question}
</research_question>
Follow these steps carefully:
1. <question_elaboration>
Elaborate on the research question. Define key terms, clarify the scope, and identify the core issues that need to be addressed. Consider different angles and perspectives that are relevant to the question.
</question_elaboration>
2. <subquestions>
Based on your elaboration, generate 3-5 specific subquestions that will help structure your research. Each subquestion should:
- Address a specific aspect of the main research question
- Be focused and answerable through web research
- Collectively provide comprehensive coverage of the main question
</subquestions>
3. For each subquestion:
a. <web_search_results>
Search for relevant information using web search. For each subquestion, perform searches with carefully formulated queries.
Extract meaningful content from the search results, focusing on:
- Authoritative sources
- Recent information when relevant
- Diverse perspectives
- Factual data and evidence
Be sure to properly cite all sources and avoid extensive quotations. Limit quotes to less than 25 words each and use no more than one quote per source.
</web_search_results>
b. Analyze the collected information, evaluating:
- Relevance to the subquestion
- Credibility of sources
- Consistency across sources
- Comprehensiveness of coverage
4. Create a beautifully formatted research report as an artifact. Your report should:
- Begin with an introduction framing the research question
- Include separate sections for each subquestion with findings
- Synthesize information across sections
- Provide a conclusion answering the main research question
- Include proper citations of all sources
- Use tables, lists, and other formatting for clarity where appropriate
The final report should be well-organized, carefully written, and properly cited. It should present a balanced view of the topic, acknowledge limitations and areas of uncertainty, and make clear, evidence-based conclusions.
Remember these important guidelines:
- Never provide extensive quotes from copyrighted content
- Limit quotes to less than 25 words each
- Use only one quote per source
- Properly cite all sources
- Do not reproduce song lyrics, poems, or other copyrighted creative works
- Put everything in your own words except for properly quoted material
- Keep summaries of copyrighted content to 2-3 sentences maximum
Please begin your research process, documenting each step carefully.
"""
### Research Processor
class ResearchProcessor:
def __init__(self):
self.research_data = {
"question": "",
"elaboration": "",
"subquestions": [],
"search_results": {},
"extracted_content": {},
"final_report": "",
}
self.notes: list[str] = []
def add_note(self, note: str):
"""Add a note to the research process."""
self.notes.append(note)
logger.debug(f"Note added: {note}")
def update_research_data(self, key: str, value: Any):
"""Update a specific key in the research data dictionary."""
self.research_data[key] = value
self.add_note(f"Updated research data: {key}")
def get_research_notes(self) -> str:
"""Return all research notes as a newline-separated string."""
return "\n".join(self.notes)
def get_research_data(self) -> dict:
"""Return the current research data dictionary."""
return self.research_data
### MCP Server Definition
async def main():
research_processor = ResearchProcessor()
server = Server("deep-research-server")
@server.list_resources()
async def handle_list_resources() -> list[Resource]:
logger.debug("Handling list_resources request")
return [
Resource(
uri="research://notes",
name="Research Process Notes",
description="Notes generated during the research process",
mimeType="text/plain",
),
Resource(
uri="research://data",
name="Research Data",
description="Structured data collected during the research process",
mimeType="application/json",
),
]
@server.read_resource()
async def handle_read_resource(uri: AnyUrl) -> str:
logger.debug(f"Handling read_resource request for URI: {uri}")
if str(uri) == "research://notes":
return research_processor.get_research_notes()
elif str(uri) == "research://data":
return json.dumps(research_processor.get_research_data(), indent=2)
else:
raise ValueError(f"Unknown resource: {uri}")
@server.list_prompts()
async def handle_list_prompts() -> list[Prompt]:
logger.debug("Handling list_prompts request")
return [
Prompt(
name=DeepResearchPrompts.DEEP_RESEARCH,
description="A prompt to conduct deep research on a question",
arguments=[
PromptArgument(
name=PromptArgs.RESEARCH_QUESTION,
description="The research question to investigate",
required=True,
),
],
)
]
@server.get_prompt()
async def handle_get_prompt(
name: str, arguments: dict[str, str] | None
) -> GetPromptResult:
logger.debug(f"Handling get_prompt request for {name} with args {arguments}")
if name != DeepResearchPrompts.DEEP_RESEARCH:
logger.error(f"Unknown prompt: {name}")
raise ValueError(f"Unknown prompt: {name}")
if not arguments or PromptArgs.RESEARCH_QUESTION not in arguments:
logger.error("Missing required argument: research_question")
raise ValueError("Missing required argument: research_question")
research_question = arguments[PromptArgs.RESEARCH_QUESTION]
prompt = PROMPT_TEMPLATE.format(research_question=research_question)
# Store the research question
research_processor.update_research_data("question", research_question)
research_processor.add_note(
f"Research initiated on question: {research_question}"
)
logger.debug(
f"Generated prompt template for research_question: {research_question}"
)
return GetPromptResult(
description=f"Deep research template for: {research_question}",
messages=[
PromptMessage(
role="user",
content=TextContent(type="text", text=prompt.strip()),
)
],
)
@server.list_tools()
async def handle_list_tools() -> list[Tool]:
logger.debug("Handling list_tools request")
# We're not exposing any tools since we'll be using Claude's built-in web search
return []
async with mcp.server.stdio.stdio_server() as (read_stream, write_stream):
logger.debug("Server running with stdio transport")
await server.run(
read_stream,
write_stream,
InitializationOptions(
server_name="deep-research-server",
server_version="0.1.0",
capabilities=server.get_capabilities(
notification_options=NotificationOptions(),
experimental_capabilities={},
),
),
)
```