This is page 1 of 4. Use http://codebase.md/zilliztech/claude-context?page={x} to view the full context.
# Directory Structure
```
├── .env.example
├── .eslintrc.js
├── .github
│ ├── ISSUE_TEMPLATE
│ │ └── bug_report.md
│ └── workflows
│ ├── ci.yml
│ └── release.yml
├── .gitignore
├── .npmrc
├── .vscode
│ ├── extensions.json
│ ├── launch.json
│ ├── settings.json
│ └── tasks.json
├── assets
│ ├── Architecture.png
│ ├── claude-context.png
│ ├── docs
│ │ ├── file-inclusion-flow.png
│ │ ├── indexing-flow-diagram.png
│ │ └── indexing-sequence-diagram.png
│ ├── file_synchronizer.png
│ ├── mcp_efficiency_analysis_chart.png
│ ├── signup_and_create_cluster.jpeg
│ ├── signup_and_get_apikey.png
│ ├── vscode-setup.png
│ └── zilliz_cloud_dashboard.jpeg
├── build-benchmark.json
├── CONTRIBUTING.md
├── docs
│ ├── dive-deep
│ │ ├── asynchronous-indexing-workflow.md
│ │ └── file-inclusion-rules.md
│ ├── getting-started
│ │ ├── environment-variables.md
│ │ ├── prerequisites.md
│ │ └── quick-start.md
│ ├── README.md
│ └── troubleshooting
│ ├── faq.md
│ └── troubleshooting-guide.md
├── evaluation
│ ├── .python-version
│ ├── analyze_and_plot_mcp_efficiency.py
│ ├── case_study
│ │ ├── django_14170
│ │ │ ├── both_conversation.log
│ │ │ ├── both_result.json
│ │ │ ├── grep_conversation.log
│ │ │ ├── grep_result.json
│ │ │ └── README.md
│ │ ├── pydata_xarray_6938
│ │ │ ├── both_conversation.log
│ │ │ ├── both_result.json
│ │ │ ├── grep_conversation.log
│ │ │ ├── grep_result.json
│ │ │ └── README.md
│ │ └── README.md
│ ├── client.py
│ ├── generate_subset_json.py
│ ├── pyproject.toml
│ ├── README.md
│ ├── retrieval
│ │ ├── __init__.py
│ │ ├── base.py
│ │ └── custom.py
│ ├── run_evaluation.py
│ ├── servers
│ │ ├── __init__.py
│ │ ├── edit_server.py
│ │ ├── grep_server.py
│ │ └── read_server.py
│ ├── utils
│ │ ├── __init__.py
│ │ ├── constant.py
│ │ ├── file_management.py
│ │ ├── format.py
│ │ └── llm_factory.py
│ └── uv.lock
├── examples
│ ├── basic-usage
│ │ ├── index.ts
│ │ ├── package.json
│ │ └── README.md
│ └── README.md
├── LICENSE
├── package.json
├── packages
│ ├── chrome-extension
│ │ ├── CONTRIBUTING.md
│ │ ├── package.json
│ │ ├── README.md
│ │ ├── src
│ │ │ ├── background.ts
│ │ │ ├── config
│ │ │ │ └── milvusConfig.ts
│ │ │ ├── content.ts
│ │ │ ├── icons
│ │ │ │ ├── icon128.png
│ │ │ │ ├── icon16.png
│ │ │ │ ├── icon32.png
│ │ │ │ └── icon48.png
│ │ │ ├── manifest.json
│ │ │ ├── milvus
│ │ │ │ └── chromeMilvusAdapter.ts
│ │ │ ├── options.html
│ │ │ ├── options.ts
│ │ │ ├── storage
│ │ │ │ └── indexedRepoManager.ts
│ │ │ ├── stubs
│ │ │ │ └── milvus-vectordb-stub.ts
│ │ │ ├── styles.css
│ │ │ └── vm-stub.js
│ │ ├── tsconfig.json
│ │ └── webpack.config.js
│ ├── core
│ │ ├── CONTRIBUTING.md
│ │ ├── package.json
│ │ ├── README.md
│ │ ├── src
│ │ │ ├── context.ts
│ │ │ ├── embedding
│ │ │ │ ├── base-embedding.ts
│ │ │ │ ├── gemini-embedding.ts
│ │ │ │ ├── index.ts
│ │ │ │ ├── ollama-embedding.ts
│ │ │ │ ├── openai-embedding.ts
│ │ │ │ └── voyageai-embedding.ts
│ │ │ ├── index.ts
│ │ │ ├── splitter
│ │ │ │ ├── ast-splitter.ts
│ │ │ │ ├── index.ts
│ │ │ │ └── langchain-splitter.ts
│ │ │ ├── sync
│ │ │ │ ├── merkle.ts
│ │ │ │ └── synchronizer.ts
│ │ │ ├── types.ts
│ │ │ ├── utils
│ │ │ │ ├── env-manager.ts
│ │ │ │ └── index.ts
│ │ │ └── vectordb
│ │ │ ├── index.ts
│ │ │ ├── milvus-restful-vectordb.ts
│ │ │ ├── milvus-vectordb.ts
│ │ │ ├── types.ts
│ │ │ └── zilliz-utils.ts
│ │ └── tsconfig.json
│ ├── mcp
│ │ ├── CONTRIBUTING.md
│ │ ├── package.json
│ │ ├── README.md
│ │ ├── src
│ │ │ ├── config.ts
│ │ │ ├── embedding.ts
│ │ │ ├── handlers.ts
│ │ │ ├── index.ts
│ │ │ ├── snapshot.ts
│ │ │ ├── sync.ts
│ │ │ └── utils.ts
│ │ └── tsconfig.json
│ └── vscode-extension
│ ├── CONTRIBUTING.md
│ ├── copy-assets.js
│ ├── LICENSE
│ ├── package.json
│ ├── README.md
│ ├── resources
│ │ ├── activity_bar.svg
│ │ └── icon.png
│ ├── src
│ │ ├── commands
│ │ │ ├── indexCommand.ts
│ │ │ ├── searchCommand.ts
│ │ │ └── syncCommand.ts
│ │ ├── config
│ │ │ └── configManager.ts
│ │ ├── extension.ts
│ │ ├── stubs
│ │ │ ├── ast-splitter-stub.js
│ │ │ └── milvus-vectordb-stub.js
│ │ └── webview
│ │ ├── scripts
│ │ │ └── semanticSearch.js
│ │ ├── semanticSearchProvider.ts
│ │ ├── styles
│ │ │ └── semanticSearch.css
│ │ ├── templates
│ │ │ └── semanticSearch.html
│ │ └── webviewHelper.ts
│ ├── tsconfig.json
│ ├── wasm
│ │ ├── tree-sitter-c_sharp.wasm
│ │ ├── tree-sitter-cpp.wasm
│ │ ├── tree-sitter-go.wasm
│ │ ├── tree-sitter-java.wasm
│ │ ├── tree-sitter-javascript.wasm
│ │ ├── tree-sitter-python.wasm
│ │ ├── tree-sitter-rust.wasm
│ │ ├── tree-sitter-scala.wasm
│ │ └── tree-sitter-typescript.wasm
│ └── webpack.config.js
├── pnpm-lock.yaml
├── pnpm-workspace.yaml
├── python
│ ├── README.md
│ ├── test_context.ts
│ ├── test_endtoend.py
│ └── ts_executor.py
├── README.md
├── scripts
│ └── build-benchmark.js
└── tsconfig.json
```
# Files
--------------------------------------------------------------------------------
/evaluation/.python-version:
--------------------------------------------------------------------------------
```
3.10
```
--------------------------------------------------------------------------------
/.npmrc:
--------------------------------------------------------------------------------
```
# Enable shell emulator for cross-platform script execution
shell-emulator=true
# Ignore workspace root check warning (already configured in package.json)
ignore-workspace-root-check=true
# Build performance optimizations
prefer-frozen-lockfile=true
auto-install-peers=true
dedupe-peer-dependents=true
# Enhanced caching
store-dir=~/.pnpm-store
cache-dir=~/.pnpm-cache
# Parallel execution optimization
child-concurrency=4
```
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
```
# Dependencies
node_modules/
*.pnp
.pnp.js
# Production builds
dist/
build/
*.tsbuildinfo
# Environment variables
.env
.env.local
.env.development.local
.env.production.local
# Logs
npm-debug.log*
yarn-debug.log*
yarn-error.log*
pnpm-debug.log*
lerna-debug.log*
# Runtime data
pids
*.pid
*.seed
*.pid.lock
# IDE
# .vscode/
.idea/
*.swp
*.swo
*~
# OS
.DS_Store
.DS_Store?
._*
.Spotlight-V100
.Trashes
ehthumbs.db
Thumbs.db
# Temporary files
*.tmp
*.temp
# Extension specific
*.vsix
*.crx
*.pem
__pycache__/
*.log
!evaluation/case_study/**/*.log
.claude/*
CLAUDE.md
.cursor/*
evaluation/repos
repos
evaluation/retrieval_results*
.venv/
```
--------------------------------------------------------------------------------
/.eslintrc.js:
--------------------------------------------------------------------------------
```javascript
module.exports = {
root: true,
parser: '@typescript-eslint/parser',
plugins: ['@typescript-eslint'],
extends: [
'eslint:recommended',
'@typescript-eslint/recommended',
],
parserOptions: {
ecmaVersion: 2020,
sourceType: 'module',
},
env: {
node: true,
es6: true,
},
rules: {
'@typescript-eslint/no-unused-vars': ['error', { argsIgnorePattern: '^_' }],
'@typescript-eslint/explicit-function-return-type': 'off',
'@typescript-eslint/explicit-module-boundary-types': 'off',
'@typescript-eslint/no-explicit-any': 'warn',
},
ignorePatterns: [
'dist',
'node_modules',
'*.js',
'*.d.ts',
],
};
```
--------------------------------------------------------------------------------
/.env.example:
--------------------------------------------------------------------------------
```
# Claude Context Environment Variables Example
#
# Copy this file to ~/.context/.env as a global setting, modify the values as needed
#
# Usage: cp env.example ~/.context/.env
#
# Note: This file does not work if you put it in your codebase directory (because it may conflict with the environment variables of your codebase project)
# =============================================================================
# Embedding Provider Configuration
# =============================================================================
# Embedding provider: OpenAI, VoyageAI, Gemini, Ollama
EMBEDDING_PROVIDER=OpenAI
# Embedding model (provider-specific)
EMBEDDING_MODEL=text-embedding-3-small
# Embedding batch size for processing (default: 100)
# You can customize it according to the throughput of your embedding model. Generally, larger batch size means less indexing time.
EMBEDDING_BATCH_SIZE=100
# =============================================================================
# OpenAI Configuration
# =============================================================================
# OpenAI API key
OPENAI_API_KEY=your-openai-api-key-here
# OpenAI base URL (optional, for custom endpoints)
# OPENAI_BASE_URL=https://api.openai.com/v1
# =============================================================================
# VoyageAI Configuration
# =============================================================================
# VoyageAI API key
# VOYAGEAI_API_KEY=your-voyageai-api-key-here
# =============================================================================
# Gemini Configuration
# =============================================================================
# Google Gemini API key
# GEMINI_API_KEY=your-gemini-api-key-here
# Gemini API base URL (optional, for custom endpoints)
# GEMINI_BASE_URL=https://generativelanguage.googleapis.com/v1beta
# =============================================================================
# Ollama Configuration
# =============================================================================
# Ollama model name
# OLLAMA_MODEL=
# Ollama host (default: http://localhost:11434)
# OLLAMA_HOST=http://localhost:11434
# =============================================================================
# Vector Database Configuration (Milvus/Zilliz)
# =============================================================================
# Milvus server address. It's optional when you get Zilliz Personal API Key.
MILVUS_ADDRESS=your-zilliz-cloud-public-endpoint
# Milvus authentication token. You can refer to this guide to get Zilliz Personal API Key as your Milvus token.
# https://github.com/zilliztech/claude-context/blob/master/assets/signup_and_get_apikey.png
MILVUS_TOKEN=your-zilliz-cloud-api-key
# =============================================================================
# Code Splitter Configuration
# =============================================================================
# Code splitter type: ast, langchain
SPLITTER_TYPE=ast
# =============================================================================
# Custom File Processing Configuration
# =============================================================================
# Additional file extensions to include beyond defaults (comma-separated)
# Example: .vue,.svelte,.astro,.twig,.blade.php
# CUSTOM_EXTENSIONS=.vue,.svelte,.astro
# Additional ignore patterns to exclude files/directories (comma-separated)
# Example: temp/**,*.backup,private/**,uploads/**
# CUSTOM_IGNORE_PATTERNS=temp/**,*.backup,private/**
# Whether to use hybrid search mode. If true, it will use both dense vector and BM25; if false, it will use only dense vector search.
# HYBRID_MODE=true
```
--------------------------------------------------------------------------------
/examples/README.md:
--------------------------------------------------------------------------------
```markdown
# Claude Context Examples
This directory contains usage examples for Claude Context.
```
--------------------------------------------------------------------------------
/evaluation/case_study/README.md:
--------------------------------------------------------------------------------
```markdown
# Case Study
This directory includes some case analysis. We compare the both method(grep + Claude Context semantic search) and the traditional grep only method.
These cases are selected from the Princeton NLP's [SWE-bench_Verified](https://openai.com/index/introducing-swe-bench-verified/) dataset. The results and the logs are generated by the [run_evaluation.py](../run_evaluation.py) script. For more details, please refer to the [evaluation README.md](../README.md) file.
- 📁 [django_14170](./django_14170/): Query optimization in YearLookup breaks filtering by "__iso_year"
- 📁 [pydata_xarray_6938](./pydata_xarray_6938/): `.swap_dims()` can modify original object
Each case study includes:
- **Original Issue**: The GitHub issue description and requirements
- **Problem Analysis**: Technical breakdown of the bug and expected solution
- **Method Comparison**: Detailed comparison of both approaches
- **Conversation Logs**: The interaction records showing how the LLM agent call the ols and generate the final answer.
- **Results**: Performance metrics and outcome analysis
## Key Results
Compared with traditional grep only, the both method(grep + Claude Context semantic search) is more efficient and accurate.
## Why Grep Fails
1. **Information Overload** - Generates hundreds of irrelevant matches
2. **No Semantic Understanding** - Only literal text matching
3. **Context Loss** - Can't understand code relationships
4. **Inefficient Navigation** - Produces many irrelevant results
## How Grep + Semantic Search Wins
1. **Intelligent Filtering** - Automatically ranks by relevance
2. **Conceptual Understanding** - Grasps code meaning and relationships
3. **Efficient Navigation** - Direct targeting of relevant sections
```
--------------------------------------------------------------------------------
/python/README.md:
--------------------------------------------------------------------------------
```markdown
# Python → TypeScript Claude Context Bridge
A simple utility to call TypeScript Claude Context methods from Python.
## What's This?
This directory contains a basic bridge that allows you to run Claude Context TypeScript functions from Python scripts. It's not a full SDK - just a simple way to test and use the TypeScript codebase from Python.
## Files
- `ts_executor.py` - Executes TypeScript methods from Python
- `test_context.ts` - TypeScript test script with Claude Context workflow
- `test_endtoend.py` - Python script that calls the TypeScript test
## Prerequisites
```bash
# Make sure you have Node.js dependencies installed
cd .. && pnpm install
# Set your OpenAI API key (required for actual indexing)
export OPENAI_API_KEY="your-openai-api-key"
# Optional: Set Milvus address (defaults to localhost:19530)
export MILVUS_ADDRESS="localhost:19530"
```
## Quick Usage
```bash
# Run the end-to-end test
python test_endtoend.py
```
This will:
1. Create embeddings using OpenAI
2. Connect to Milvus vector database
3. Index the `packages/core/src` codebase
4. Perform a semantic search
5. Show results
## Manual Usage
```python
from ts_executor import TypeScriptExecutor
executor = TypeScriptExecutor()
result = executor.call_method(
'./test_context.ts',
'testContextEndToEnd',
{
'openaiApiKey': 'sk-your-key',
'milvusAddress': 'localhost:19530',
'codebasePath': '../packages/core/src',
'searchQuery': 'vector database configuration'
}
)
print(result)
```
## How It Works
1. `ts_executor.py` creates temporary TypeScript wrapper files
2. Runs them with `ts-node`
3. Captures JSON output and returns to Python
4. Supports async functions and complex parameters
That's it! This is just a simple bridge for testing purposes.
```
--------------------------------------------------------------------------------
/docs/README.md:
--------------------------------------------------------------------------------
```markdown
# Claude Context Documentation

Welcome to the Claude Context documentation! Claude Context is a powerful tool that adds semantic code search capabilities to AI coding assistants through MCP.
## 🚀 Quick Navigation
### Getting Started
- [🛠️ Prerequisites](getting-started/prerequisites.md) - What you need before starting
- [🔍 Environment Variables](getting-started/environment-variables.md) - How to configure environment variables for MCP
- [⚡ Quick Start Guide](getting-started/quick-start.md) - Get up and running in 1 minutes
### Components
- [MCP Server](../packages/mcp/README.md) - The MCP server of Claude Context
- [VSCode Extension](../packages/vscode-extension/README.md) - The VSCode extension of Claude Context
- [Core Package](../packages/core/README.md) - The core package of Claude Context
### Dive Deep
- [File Inclusion & Exclusion Rules](dive-deep/file-inclusion-rules.md) - Detailed explanation of file inclusion and exclusion rules
- [Asynchronous Indexing Workflow](dive-deep/asynchronous-indexing-workflow.md) - Detailed explanation of asynchronous indexing workflow
### Troubleshooting
- [❓ FAQ](troubleshooting/faq.md) - Frequently asked questions
- [🐛 Troubleshooting Guide](troubleshooting/troubleshooting-guide.md) - Troubleshooting guide
## 🔗 External Resources
- [GitHub Repository](https://github.com/zilliztech/claude-context)
- [VSCode Marketplace](https://marketplace.visualstudio.com/items?itemName=zilliz.semanticcodesearch)
- [npm - Core Package](https://www.npmjs.com/package/@zilliz/claude-context-core)
- [npm - MCP Server](https://www.npmjs.com/package/@zilliz/claude-context-mcp)
- [Zilliz Cloud](https://cloud.zilliz.com)
## 💬 Support
- **Issues**: [GitHub Issues](https://github.com/zilliztech/claude-context/issues)
- **Discord**: [Join our Discord](https://discord.gg/mKc3R95yE5)
```
--------------------------------------------------------------------------------
/examples/basic-usage/README.md:
--------------------------------------------------------------------------------
```markdown
# Basic Usage Example
This example demonstrates the basic usage of Claude Context.
## Prerequisites
1. **OpenAI API Key**: Set your OpenAI API key for embeddings:
```bash
export OPENAI_API_KEY="your-openai-api-key"
```
2. **Milvus Server**: Make sure Milvus server is running:
- You can also use fully managed Milvus on [Zilliz Cloud](https://zilliz.com/cloud).
In this case, set the `MILVUS_ADDRESS` as the Public Endpoint and `MILVUS_TOKEN` as the Token like this:
```bash
export MILVUS_ADDRESS="https://your-cluster.zillizcloud.com"
export MILVUS_TOKEN="your-zilliz-token"
```
- You can also set up a Milvus server on [Docker or Kubernetes](https://milvus.io/docs/install-overview.md). In this setup, please use the server address and port as your `uri`, e.g.`http://localhost:19530`. If you enable the authentication feature on Milvus, set the `token` as `"<your_username>:<your_password>"`, otherwise there is no need to set the token.
```bash
export MILVUS_ADDRESS="http://localhost:19530"
export MILVUS_TOKEN="<your_username>:<your_password>"
```
## Running the Example
1. Install dependencies:
```bash
pnpm install
```
2. Set environment variables (see examples above)
3. Run the example:
```bash
pnpm run start
```
## What This Example Does
1. **Indexes Codebase**: Indexes the entire Claude Context project
2. **Performs Searches**: Executes semantic searches for different code patterns
3. **Shows Results**: Displays search results with similarity scores and file locations
## Expected Output
```
🚀 Claude Context Real Usage Example
===============================
...
🔌 Connecting to vector database at: ...
📖 Starting to index codebase...
🗑️ Existing index found, clearing it first...
📊 Indexing stats: 45 files, 234 code chunks
🔍 Performing semantic search...
🔎 Search: "vector database operations"
1. Similarity: 89.23%
File: /path/to/packages/core/src/vectordb/milvus-vectordb.ts
Language: typescript
Lines: 147-177
Preview: async search(collectionName: string, queryVector: number[], options?: SearchOptions)...
🎉 Example completed successfully!
```
```
--------------------------------------------------------------------------------
/packages/chrome-extension/README.md:
--------------------------------------------------------------------------------
```markdown
# GitHub Code Vector Search Chrome Extension
A Chrome extension for indexing and semantically searching GitHub repository code, powered by Claude Context.
> 📖 **New to Claude Context?** Check out the [main project README](../../README.md) for an overview and setup instructions.
## Features
- 🔍 **Semantic Search**: Intelligent code search on GitHub repositories based on semantic understanding
- 📁 **Repository Indexing**: Automatically index GitHub repositories and build semantic vector database
- 🎯 **Context Search**: Search related code by selecting code snippets directly on GitHub
- 🔧 **Multi-platform Support**: Support for OpenAI and VoyageAI as embedding providers
- 💾 **Vector Storage**: Integrated with Milvus vector database for efficient storage and retrieval
- 🌐 **GitHub Integration**: Seamlessly integrates with GitHub's interface
- 📱 **Cross-Repository**: Search across multiple indexed repositories
- ⚡ **Real-time**: Index and search code as you browse GitHub
## Installation
### From Chrome Web Store
> **Coming Soon**: Extension will be available on Chrome Web Store
### Manual Installation (Development)
1. **Build the Extension**:
```bash
cd packages/chrome-extension
pnpm build
```
2. **Load in Chrome**:
- Open Chrome and navigate to `chrome://extensions/`
- Enable "Developer mode" in the top right
- Click "Load unpacked" and select the `dist` folder
- The extension should now appear in your extensions list
## Quick Start
1. **Configure Settings**:
- Click the extension icon in Chrome toolbar
- Go to Options/Settings
- Configure embedding provider and API Key
- Set up Milvus connection details
2. **Index a Repository**:
- Navigate to any GitHub repository
- Click the "Index Repository" button that appears in the sidebar
- Wait for indexing to complete
3. **Start Searching**:
- Use the search box that appears on GitHub repository pages
- Enter natural language queries like "function that handles authentication"
- Click on results to navigate to the code
## Configuration
The extension can be configured through the options page:
- **Embedding Provider**: Choose between OpenAI or VoyageAI
- **Embedding Model**: Select specific model (e.g., `text-embedding-3-small`)
- **API Key**: Your embedding provider API key
- **Milvus Settings**: Vector database connection details
- **GitHub Token**: Personal access token for private repositories (optional)
## Permissions
The extension requires the following permissions:
- **Storage**: To save configuration and index metadata
- **Scripting**: To inject search UI into GitHub pages
- **Unlimited Storage**: For storing vector embeddings locally
- **Host Permissions**: Access to GitHub.com and embedding provider APIs
## File Structure
- `src/content.ts` - Main content script that injects UI into GitHub pages
- `src/background.ts` - Background service worker for extension lifecycle
- `src/options.ts` - Options page for configuration
- `src/config/milvusConfig.ts` - Milvus connection configuration
- `src/milvus/chromeMilvusAdapter.ts` - Browser-compatible Milvus adapter
- `src/storage/indexedRepoManager.ts` - Repository indexing management
- `src/stubs/` - Browser compatibility stubs for Node.js modules
## Development Features
- **Browser Compatibility**: Node.js modules adapted for browser environment
- **WebAssembly Support**: Optimized for browser performance
- **Offline Capability**: Local storage for indexed repositories
- **Progress Tracking**: Real-time indexing progress indicators
- **Error Handling**: Graceful degradation and user feedback
## Usage Examples
### Basic Search
1. Navigate to a GitHub repository
2. Enter query: "error handling middleware"
3. Browse semantic search results
### Context Search
1. Select code snippet on GitHub
2. Right-click and choose "Search Similar Code"
3. View related code across the repository
### Multi-Repository Search
1. Index multiple repositories
2. Use the extension popup to search across all indexed repos
3. Filter results by repository or file type
## Contributing
This Chrome extension is part of the Claude Context monorepo. Please see:
- [Main Contributing Guide](../../CONTRIBUTING.md) - General contribution guidelines
- [Chrome Extension Contributing](CONTRIBUTING.md) - Specific development guide for this extension
## Related Packages
- **[@zilliz/claude-context-core](../core)** - Core indexing engine used by this extension
- **[@zilliz/claude-context-vscode-extension](../vscode-extension)** - VSCode integration
- **[@zilliz/claude-context-mcp](../mcp)** - MCP server integration
## Tech Stack
- **TypeScript** - Type-safe development
- **Chrome Extension Manifest V3** - Modern extension architecture
- **Webpack** - Module bundling and optimization
- **Claude Context Core** - Semantic search engine
- **Milvus Vector Database** - Vector storage and retrieval
- **OpenAI/VoyageAI Embeddings** - Text embedding generation
## Browser Support
- Chrome 88+
- Chromium-based browsers (Edge, Brave, etc.)
## License
MIT - See [LICENSE](../../LICENSE) for details
```
--------------------------------------------------------------------------------
/evaluation/README.md:
--------------------------------------------------------------------------------
```markdown
# Claude Context MCP Evaluation
This directory contains the evaluation framework and experimental results for comparing the efficiency of code retrieval using Claude Context MCP versus traditional grep-only approaches.
## Overview
We conducted a controlled experiment to measure the impact of adding Claude Context MCP tool to a baseline coding agent. The evaluation demonstrates significant improvements in token efficiency while maintaining comparable retrieval quality.
## Experimental Design
We designed a controlled experiment comparing two coding agents performing identical retrieval tasks. The baseline agent uses simple tools including read, grep, and edit functions. The enhanced agent adds Claude Context MCP tool to this same foundation. Both agents work on the same dataset using the same model to ensure fair comparison. We use [LangGraph MCP and ReAct framework](https://langchain-ai.github.io/langgraph/agents/mcp/#use-mcp-tools) to implement it.
We selected 30 instances from Princeton NLP's [SWE-bench_Verified](https://openai.com/index/introducing-swe-bench-verified/) dataset, filtering for 15-60 minute difficulty problems with exactly 2 file modifications. This subset represents typical coding tasks and enables quick validation. The dataset generation is implemented in [`generate_subset_json.py`](./generate_subset_json.py).
We chose [GPT-4o-mini](https://platform.openai.com/docs/models/gpt-4o-mini) as the default model for cost-effective considerations.
We ran each method 3 times independently, giving us 6 total runs for statistical reliability. We measured token usage, tool calls, retrieval precision, recall, and F1-score across all runs. The main entry point for running evaluations is [`run_evaluation.py`](./run_evaluation.py).
## Key Results
### Performance Summary
| Metric | Baseline (Grep Only) | With Claude Context MCP | Improvement |
|--------|---------------------|--------------------------|-------------|
| **Average F1-Score** | 0.40 | 0.40 | Comparable |
| **Average Token Usage** | 73,373 | 44,449 | **-39.4%** |
| **Average Tool Calls** | 8.3 | 5.3 | **-36.3%** |
### Key Findings
**Dramatic Efficiency Gains**:
With Claude Context MCP, we achieved:
- **39.4% reduction** in token consumption (28,924 tokens saved per instance)
- **36.3% reduction** in tool calls (3.0 fewer calls per instance)
## Conclusion
The results demonstrate that Claude Context MCP provides:
### Immediate Benefits
- **Cost Efficiency**: ~40% reduction in token usage directly reduces operational costs
- **Speed Improvement**: Fewer tool calls and tokens mean faster code localization and task completion
- **Better Quality**: This also means that, under the constraint of limited token context length, using Claude Context yields better retrieval and answer results.
### Strategic Advantages
- **Better Resource Utilization**: Under fixed token budgets, Claude Context MCP enables handling more tasks
- **Wider Usage Scenarios**: Lower per-task costs enable broader usage scenarios
- **Improved User Experience**: Faster responses with maintained accuracy
## Running the Evaluation
To reproduce these results:
1. **Install Dependencies**:
For python environment, you can use `uv` to install the lockfile dependencies.
```bash
cd evaluation && uv sync
source .venv/bin/activate
```
For node environment, make sure your `node` version is `Node.js >= 20.0.0 and < 24.0.0`.
Our evaluation results are tested on `[email protected]`, you can change the `claude-context` mcp server setting in the `retrieval/custom.py` file to get the latest version or use a development version.
2. **Set Environment Variables**:
```bash
export OPENAI_API_KEY=your_openai_api_key
export MILVUS_ADDRESS=your_milvus_address
```
For more configuration details, refer the `claude-context` mcp server settings in the `retrieval/custom.py` file.
```bash
export GITHUB_TOKEN=your_github_token
```
You need also prepare a `GITHUB_TOKEN` for automatically cloning the repositories, refer to [SWE-bench documentation](https://www.swebench.com/SWE-bench/guides/create_rag_datasets/#example-usage) for more details.
3. **Generate Dataset**:
```bash
python generate_subset_json.py
```
4. **Run Baseline Evaluation**:
```bash
python run_evaluation.py --retrieval_types grep --output_dir retrieval_results_grep
```
5. **Run Enhanced Evaluation**:
```bash
python run_evaluation.py --retrieval_types cc,grep --output_dir retrieval_results_both
```
6. **Analyze Results**:
```bash
python analyze_and_plot_mcp_efficiency.py
```
The evaluation framework is designed to be reproducible and can be easily extended to test additional configurations or datasets. Due to the proprietary nature of LLMs, exact numerical results may vary between runs and cannot be guaranteed to be identical. However, the core conclusions drawn from the analysis remain consistent and robust across different runs.
## Results Visualization

*The chart above shows the dramatic efficiency improvements achieved by Claude Context MCP. The token usage and tool calls are significantly reduced.*
## Case Study
For detailed analysis of why grep-only approaches have limitations and how semantic search addresses these challenges, please refer to our **[Case Study](./case_study/)** which provides in-depth comparisons and analysis on the this experiment results.
```
--------------------------------------------------------------------------------
/packages/vscode-extension/README.md:
--------------------------------------------------------------------------------
```markdown
# Semantic Code Search VSCode Extension
[](https://marketplace.visualstudio.com/items?itemName=zilliz.semanticcodesearch)
A code indexing and semantic search VSCode extension powered by [Claude Context](https://github.com/zilliztech/claude-context).
> 📖 **New to Claude Context?** Check out the [main project README](https://github.com/zilliztech/claude-context/blob/master/README.md) for an overview and setup instructions.

## Features
- 🔍 **Semantic Search**: Intelligent code search based on semantic understanding, not just keyword matching
- 📁 **Codebase Indexing**: Automatically index entire codebase and build semantic vector database
- 🎯 **Context Search**: Search related code by selecting code snippets
- 🔧 **Multi-platform Support**: Support for OpenAI, VoyageAI, Gemini, and Ollama as embedding providers
- 💾 **Vector Storage**: Integrated with Milvus vector database for efficient storage and retrieval
## Requirements
- **VSCode Version**: 1.74.0 or higher
## Installation
### From VS Code Marketplace
1. **Direct Link**: [Install from VS Code Marketplace](https://marketplace.visualstudio.com/items?itemName=zilliz.semanticcodesearch)
2. **Manual Search**:
- Open Extensions view in VSCode (Ctrl+Shift+X or Cmd+Shift+X on Mac)
- Search for "Semantic Code Search"
- Click Install
## Quick Start
### Configuration
The first time you open Claude Context, you need to click on Settings icon to configure the relevant options.
#### Embedding Configuration
Configure your embedding provider to convert code into semantic vectors.
**OpenAI Configuration:**
- `Embedding Provider`: Select "OpenAI" from the dropdown
- `Model name`: Choose the embedding model (e.g., `text-embedding-3-small`, `text-embedding-3-large`)
- `OpenAI API key`: Your OpenAI API key for authentication
- `Custom API endpoint URL`: Optional custom endpoint (defaults to `https://api.openai.com/v1`)
**Other Supported Providers:**
- **Gemini**: Google's state-of-the-art embedding model with Matryoshka representation learning
- **VoyageAI**: Alternative embedding provider with competitive performance
- **Ollama**: For local embedding models
#### Code Splitter Configuration
Configure how your code is split into chunks for indexing.
**Splitter Settings:**
- `Splitter Type`: Choose between "AST Splitter" (syntax-aware) or "LangChain Splitter" (character-based)
- `Chunk Size`: Maximum size of each code chunk (default: 1000 characters)
- `Chunk Overlap`: Number of overlapping characters between chunks (default: 200 characters)
> **Recommendation**: Use AST Splitter for better semantic understanding of code structure.
#### Zilliz Cloud configuration
Get a free Milvus vector database on Zilliz Cloud.
Claude Context needs a vector database. You can [sign up](https://cloud.zilliz.com/signup?utm_source=github&utm_medium=referral&utm_campaign=2507-codecontext-readme) on Zilliz Cloud to get a free Serverless cluster.
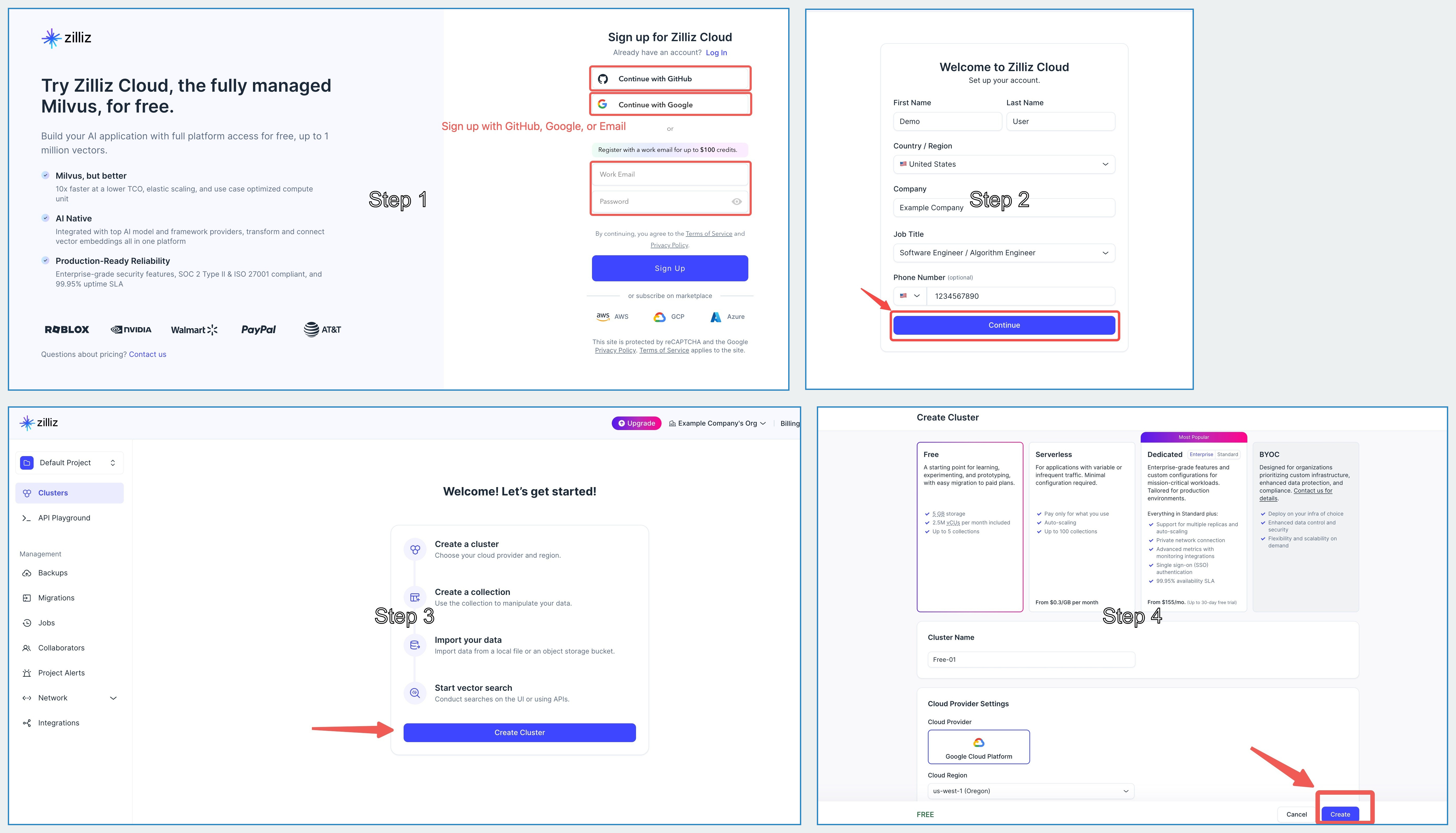
After creating your cluster, open your Zilliz Cloud console and copy both the **public endpoint** and your **API key**.
These will be used as `your-zilliz-cloud-public-endpoint` and `your-zilliz-cloud-api-key` in the configuration examples.
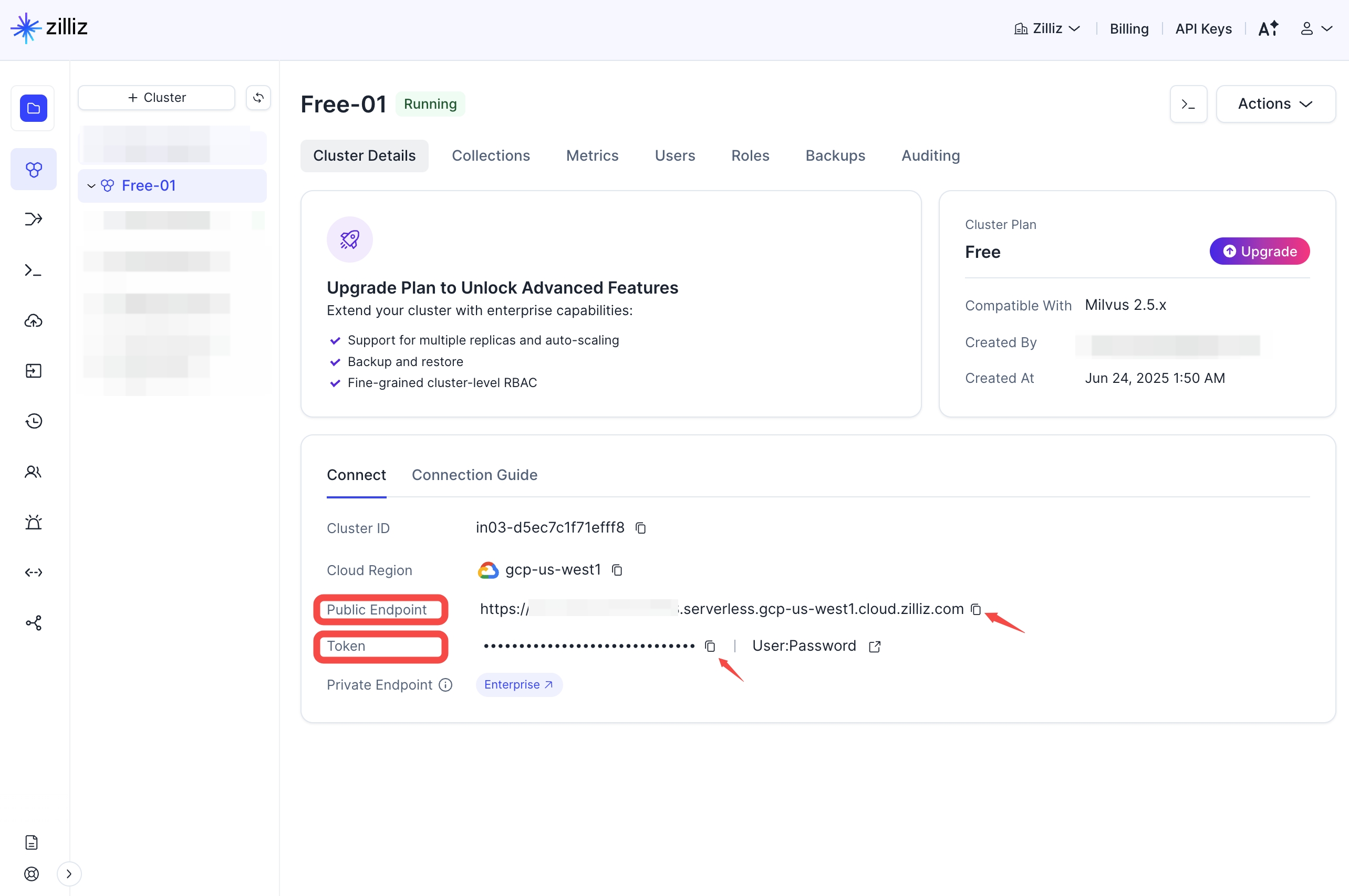
Keep both values handy for the configuration steps below.
If you need help creating your free vector database or finding these values, see the [Zilliz Cloud documentation](https://docs.zilliz.com/docs/create-cluster) for detailed instructions.
```bash
MILVUS_ADDRESS=your-zilliz-cloud-public-endpoint
MILVUS_TOKEN=your-zilliz-cloud-api-key
```
### Usage
1. **Set the Configuration**:
- Open VSCode Settings (Ctrl+, or Cmd+, on Mac)
- Search for "Semantic Code Search"
- Set the configuration
2. **Index Codebase**:
- Open Command Palette (Ctrl+Shift+P or Cmd+Shift+P on Mac)
- Run "Semantic Code Search: Index Codebase"
3. **Start Searching**:
- Open Semantic Code Search panel in sidebar
- Enter search query or right-click on selected code to search
## Commands
- `Semantic Code Search: Semantic Search` - Perform semantic search
- `Semantic Code Search: Index Codebase` - Index current codebase
- `Semantic Code Search: Clear Index` - Clear the index
## Configuration
- `semanticCodeSearch.embeddingProvider.provider` - Embedding provider (OpenAI/VoyageAI/Gemini/Ollama)
- `semanticCodeSearch.embeddingProvider.model` - Embedding model to use
- `semanticCodeSearch.embeddingProvider.apiKey` - API key for embedding provider
- `semanticCodeSearch.embeddingProvider.baseURL` - Custom API endpoint URL (optional, for OpenAI and Gemini)
- `semanticCodeSearch.embeddingProvider.outputDimensionality` - Output dimension for Gemini (supports 3072, 1536, 768, 256)
- `semanticCodeSearch.milvus.address` - Milvus server address
## Contributing
This VSCode extension is part of the Claude Context monorepo. Please see:
- [Main Contributing Guide](https://github.com/zilliztech/claude-context/blob/master/CONTRIBUTING.md) - General contribution guidelines
- [VSCode Extension Contributing](https://github.com/zilliztech/claude-context/blob/master/packages/vscode-extension/CONTRIBUTING.md) - Specific development guide for this extension
## Related Packages
- **[@zilliz/claude-context-core](https://github.com/zilliztech/claude-context/tree/master/packages/core)** - Core indexing engine used by this extension
- **[@zilliz/claude-context-mcp](https://github.com/zilliztech/claude-context/tree/master/packages/mcp)** - Alternative MCP server integration
## Tech Stack
- TypeScript
- VSCode Extension API
- Milvus Vector Database
- OpenAI/VoyageAI Embeddings
## License
MIT - See [LICENSE](https://github.com/zilliztech/claude-context/blob/master/LICENSE) for details
```
--------------------------------------------------------------------------------
/evaluation/case_study/django_14170/README.md:
--------------------------------------------------------------------------------
```markdown
# Django 14170: YearLookup ISO Year Bug
A comparison showing how both methods(grep + semantic search) outperform grep-based approaches for complex Django ORM bugs.
<details>
<summary><strong>📋 Original GitHub Issue</strong></summary>
## Query optimization in YearLookup breaks filtering by "__iso_year"
The optimization to use BETWEEN instead of the EXTRACT operation in YearLookup is also registered for the "__iso_year" lookup, which breaks the functionality provided by ExtractIsoYear when used via the lookup.
**Problem**: When using `__iso_year` filters, the `YearLookup` class applies standard BETWEEN optimization which works for calendar years but fails for ISO week-numbering years.
**Example**:
```python
# This should use EXTRACT('isoyear' FROM ...) but incorrectly uses BETWEEN
DTModel.objects.filter(start_date__iso_year=2020)
# Generates: WHERE "start_date" BETWEEN 2020-01-01 AND 2020-12-31
# Should be: WHERE EXTRACT('isoyear' FROM "start_date") = 2020
```
**Files**: `django/db/models/lookups.py`, `django/db/backends/base/operations.py`
</details>
## Results
| Metric | Both Methods | Grep Method | Improvement |
|--------|-------------|-------------|-------------|
| **Token Usage** | 9,036 | 130,819 | **93% less** |
| **Tool Calls** | 3 | 8 | **62% fewer** |
| **Success Rate** | 50% hit | 0% hit | **Much better** |
## How Each Method Found the Problem
### 🎯 Both Methods
```log
🔧 search_code('YearLookup')
⚙️ Found 10 results for query: "YearLookup" in codebase
1. Code snippet (python) [repo__django__django]
Location: django/db/models/lookups.py:568-577
Context: YearExact class with get_bound_params method
2. Code snippet (python) [repo__django__django]
Location: django/db/models/lookups.py:538-569
Context: YearLookup base class with year_lookup_bounds method
🔧 edit_file(django/db/models/lookups.py)
⚙️ Arguments: {'file_path': 'django/db/models/lookups.py',
'old_string': 'def get_direct_rhs_sql(self, connection, rhs):\n return connection.operators[self.lookup_name] % rhs',
'new_string': "def get_direct_rhs_sql(self, connection, rhs):\n if self.lookup_name == '__iso_year':\n return 'EXTRACT(ISOYEAR FROM %s)' % rhs\n return connection.operators[self.lookup_name] % rhs"}
Result: Successfully modified file
🔧 edit_file(django/db/models/lookups.py)
⚙️ Arguments: {'file_path': 'django/db/models/lookups.py',
'old_string': 'def year_lookup_bounds(self, connection, year):',
'new_string': "def year_lookup_bounds(self, connection, year):\n if self.lookup_name == '__iso_year':\n return (year - 1, year)"}
Result: Successfully modified file
```
**Key Success**: Semantic search immediately understood "YearLookup" as the core concept and found the exact classes that needed modification.
### 🔍 Grep Method
```log
🔧 directory_tree()
⚙️ Arguments: {'path': 'repo__django__django'}
Result: Retrieved 3000+ lines of directory structure (~50k tokens)
Problem: Massive information overload, no direct relevance
🔧 search_text('ExtractIsoYear')
⚙️ Arguments: {'pattern': 'ExtractIsoYear', 'path': 'repo__django__django'}
Result: Found 21 matches across multiple files:
- django/db/models/functions/__init__.py:5 (import statement)
- django/db/models/functions/__init__.py:31 (export list)
- django/db/models/functions/datetime.py:93 (class ExtractIsoYear)
- django/db/models/functions/datetime.py:150 (DateField.register_lookup)
Problem: Most were irrelevant imports and registrations
🔧 edit_file('django/db/models/functions/datetime.py')
⚙️ Arguments: {'old_string': 'ExtractIsoYear.register_lookup(YearExact)', 'new_string': '# ExtractIsoYear.register_lookup(YearExact)'}
Result: Successfully modified file
🔧 edit_file('django/db/models/functions/datetime.py')
⚙️ Arguments: {'old_string': 'ExtractIsoYear.register_lookup(YearGt)', 'new_string': '# ExtractIsoYear.register_lookup(YearGt)'}
Result: Successfully modified file
🔧 edit_file('django/db/models/functions/datetime.py')
⚙️ Arguments: {'old_string': 'ExtractIsoYear.register_lookup(YearGte)', 'new_string': '# ExtractIsoYear.register_lookup(YearGte)'}
Result: Successfully modified file
🔧 edit_file('django/db/models/functions/datetime.py')
⚙️ Arguments: {'old_string': 'ExtractIsoYear.register_lookup(YearLt)', 'new_string': '# ExtractIsoYear.register_lookup(YearLt)'}
Result: Successfully modified file
🔧 edit_file('django/db/models/functions/datetime.py')
⚙️ Arguments: {'old_string': 'ExtractIsoYear.register_lookup(YearLte)', 'new_string': '# ExtractIsoYear.register_lookup(YearLte)'}
Result: Successfully modified file
🔧 edit_file('tests/db_functions/datetime/test_extract_trunc.py')
⚙️ Arguments: {'old_string': "self.assertEqual(DTModel.objects.filter(start_datetime__iso_year=ExtractIsoYear('start_datetime')).count(), 2)", 'new_string': "# self.assertEqual(DTModel.objects.filter(start_datetime__iso_year=ExtractIsoYear('start_datetime')).count(), 2)"}
Result: Successfully modified file
```
**Key Failure**: Text search focused on wrong components (ExtractIsoYear registrations) instead of the actual optimization logic (YearLookup class).
## Why Grep + Semantic Search Won
1. **Conceptual Understanding**: Recognized "YearLookup" as the optimization mechanism causing the issue
2. **Direct Navigation**: Immediately found the relevant classes without noise
3. **Root Cause Focus**: Identified the boundary calculation logic that needed ISO year awareness
4. **Efficient Execution**: 3 targeted operations vs 8 scattered attempts
## Why Grep Failed
1. **Information Overload**: Wasted 50k tokens on irrelevant directory structure
2. **Surface-Level Matching**: Focused on "ExtractIsoYear" strings instead of understanding the optimization conflict
3. **Wrong Solution**: Applied superficial fixes (commenting registrations) instead of addressing the core logic
4. **No Context**: Couldn't understand the relationship between YearLookup optimization and ISO year boundaries
The semantic approach understood that the issue was about **optimization logic**, not just **ISO year functionality**, leading to the correct architectural fix.
## Files
- [`both_conversation.log`](./both_conversation.log) - Both methods interaction log
- [`grep_conversation.log`](./grep_conversation.log) - Grep method interaction log
- [`both_result.json`](./both_result.json) - Both methods performance metrics
- [`grep_result.json`](./grep_result.json) - Grep method performance metrics
```
--------------------------------------------------------------------------------
/evaluation/case_study/pydata_xarray_6938/README.md:
--------------------------------------------------------------------------------
```markdown
# Xarray 6938: swap_dims() Mutation Bug
A case study showing how both methods(grep + semantic search) efficiently identify object mutation bugs in scientific computing libraries.
<details>
<summary><strong>📋 Original GitHub Issue</strong></summary>
## `.swap_dims()` can modify original object
**Problem**: In certain cases, `.swap_dims()` modifies the original object instead of returning a new one, violating immutability expectations.
**Example**:
```python
import numpy as np
import xarray as xr
nz = 11
ds = xr.Dataset({
"y": ("z", np.random.rand(nz)),
"lev": ("z", np.arange(nz) * 10),
})
# This should not modify ds, but it does
ds2 = ds.swap_dims(z="lev").rename_dims(lev="z").reset_index("lev").reset_coords()
ds2.swap_dims(z='lev') # This modifies ds2['lev'] unexpectedly
# ds2['lev'] now has dimension 'lev' instead of 'z'
```
**Expected**: Original objects should remain unchanged after swap_dims operations.
**Actual**: Original object's internal state gets modified during dimension swapping.
**Files**: `xarray/core/dataset.py`, `xarray/core/variable.py`
</details>
## Results
| Metric | Both Methods | Grep Method | Improvement |
|--------|-------------|-------------|-------------|
| **Token Usage** | 15,826 | 41,999 | **62% less** |
| **Tool Calls** | 3 | 11 | **73% fewer** |
| **Success Rate** | 50% hit | 50% hit | **Equal accuracy** |
## How Each Method Found the Problem
### 🎯 Both Methods
```log
🔧 search_code('.swap_dims()')
⚙️ Arguments: {'path': 'repo__pydata__xarray', 'query': '.swap_dims()', 'limit': 10}
Result: Found 10 results for query: ".swap_dims()" in codebase
1. Code snippet (python) [repo__pydata__xarray]
Location: xarray/tests/test_formatting_html.py:67-76
2. Code snippet (python) [repo__pydata__xarray]
Location: xarray/tests/test_dataset.py:2926-2979
🔧 edit_file('xarray/core/dataset.py')
⚙️ Arguments: {'old_string': 'result_dims = {dims_dict.get(dim, dim) for dim in self.dims}', 'new_string': 'result_dims = {dims_dict.get(dim, dim) for dim in self.dims if dim in dims_dict or dim not in self.variables}'}
Result: Successfully modified file
🔧 edit_file('xarray/core/dataarray.py')
⚙️ Arguments: {'old_string': 'ds = self._to_temp_dataset().swap_dims(dims_dict)', 'new_string': 'ds = self._to_temp_dataset().swap_dims(dims_dict) # Ensure that ds does not modify the original DataArray'}
Result: Successfully modified file
```
**Key Success**: Semantic search immediately located the actual `swap_dims()` implementations and understood the functional context.
### 🔍 Grep Method
```log
🔧 list_directory('repo__pydata__xarray')
⚙️ Result: Retrieved directory structure with multiple subdirectories
Problem: Basic directory navigation without targeted search
🔧 list_directory('repo__pydata__xarray/xarray')
⚙️ Result: Found core directories: backends, coding, core, plot, static, tests
🔧 list_directory('repo__pydata__xarray/xarray/core')
⚙️ Result: Found 50+ Python files including dataset.py, dataarray.py, variable.py
🔧 search_text('swap_dims')
⚙️ Arguments: {'pattern': 'swap_dims', 'path': 'repo__pydata__xarray/xarray/core', 'include': '*.py'}
Result: Found 21 matches across core files:
- xarray/core/common.py:600 (Dataset.swap_dims reference)
- xarray/core/dataarray.py:753 (".rename() or .swap_dims() instead.")
- xarray/core/dataarray.py:2026 (DataArray.swap_dims reference)
- xarray/core/dataarray.py:2044 (def swap_dims method)
Problem: Many matches across different contexts
🔧 read_file('xarray/core/dataarray.py', offset=2000, limit=40)
⚙️ Result: Read lines 2001-2040 showing rename method documentation
🔧 read_file('xarray/core/dataset.py', offset=3600, limit=40)
⚙️ Result: Read lines 3601-3640 showing rename_dims method
🔧 read_file('xarray/core/common.py', offset=590, limit=10)
⚙️ Result: Read lines 591-600 showing assign_coords documentation
🔧 edit_file('xarray/core/dataarray.py')
⚙️ Arguments: {'old_string': ' def swap_dims(', 'new_string': ' def swap_dims(self, dims_dict: Mapping[str, str] | None = None, **dims: str) -> DataArray:\n """Returns a new DataArray with swapped dimensions..."""'}
Result: Successfully modified file
🔧 edit_file('xarray/core/dataset.py')
⚙️ Arguments: {'old_string': ' def swap_dims(', 'new_string': ' def swap_dims(self, dims_dict: Mapping[str, str] | None = None, **dims: str) -> Dataset:\n """Returns a new Dataset with swapped dimensions..."""'}
Result: Successfully modified file
🔧 edit_file('xarray/core/common.py')
⚙️ Arguments: {'old_string': 'Dataset.swap_dims', 'new_string': '# The swap_dims method is being used here without modification, so ensure appropriate usage.'}
Result: Successfully modified file
```
**Key Inefficiency**: Used massive list_directory and read_file operations, instead of focusing on relevant methods.
## Why Grep + Semantic Search Won
1. **Method-Level Understanding**: Recognized `.swap_dims()` as a specific method with defined behavior
2. **Functional Context**: Understood the relationship between Dataset, DataArray, and Variable classes
3. **Efficient Navigation**: Directly located method implementations without searching through tests and docs
4. **Mutation Awareness**: Connected the symptom (unexpected changes) to likely causes (shared references)
## Why Grep Was Less Efficient
1. **Information Overload**: Generated hundreds of matches for common terms like 'swap_dims' and 'dimension'
2. **Context Loss**: Treated method names as text strings rather than functional concepts
3. **Inefficient Reading**: Required reading large portions of files to understand basic functionality
## Key Insights
**Semantic Search Advantages**:
- **Concept Recognition**: Understands `.swap_dims()` as a method concept, not just text
- **Relationship Mapping**: Automatically connects related classes and methods
- **Relevance Filtering**: Prioritizes implementation code over tests and documentation
- **Efficiency**: Achieves same accuracy with 62% fewer tokens and 73% fewer operations
**Traditional Search Limitations**:
- **Text Literalism**: Treats code as text without understanding semantic meaning
- **Noise Generation**: Produces excessive irrelevant matches across different contexts
- **Resource Waste**: Consumes 2.6x more computational resources for equivalent results
- **Scalability Issues**: Becomes increasingly inefficient with larger codebases
This case demonstrates semantic search's particular value for scientific computing libraries where **data integrity** is paramount and **mutation bugs** can corrupt research results.
## Files
- [`both_conversation.log`](./both_conversation.log) - Both methods interaction log
- [`grep_conversation.log`](./grep_conversation.log) - Grep method interaction log
- [`both_result.json`](./both_result.json) - Both methods performance metrics
- [`grep_result.json`](./grep_result.json) - Grep method performance metrics
```
--------------------------------------------------------------------------------
/packages/core/README.md:
--------------------------------------------------------------------------------
```markdown
# @zilliz/claude-context-core

The core indexing engine for Claude Context - a powerful tool for semantic search and analysis of codebases using vector embeddings and AI.
[](https://www.npmjs.com/package/@zilliz/claude-context-core)
[](https://www.npmjs.com/package/@zilliz/claude-context-core)
> 📖 **New to Claude Context?** Check out the [main project README](../../README.md) for an overview and quick start guide.
## Installation
```bash
npm install @zilliz/claude-context-core
```
### Prepare Environment Variables
#### OpenAI API key
See [OpenAI Documentation](https://platform.openai.com/docs/api-reference) for more details to get your API key.
```bash
OPENAI_API_KEY=your-openai-api-key
```
#### Zilliz Cloud configuration
Get a free Milvus vector database on Zilliz Cloud.
Claude Context needs a vector database. You can [sign up](https://cloud.zilliz.com/signup?utm_source=github&utm_medium=referral&utm_campaign=2507-codecontext-readme) on Zilliz Cloud to get a free Serverless cluster.

After creating your cluster, open your Zilliz Cloud console and copy both the **public endpoint** and your **API key**.
These will be used as `your-zilliz-cloud-public-endpoint` and `your-zilliz-cloud-api-key` in the configuration examples.

Keep both values handy for the configuration steps below.
If you need help creating your free vector database or finding these values, see the [Zilliz Cloud documentation](https://docs.zilliz.com/docs/create-cluster) for detailed instructions.
```bash
MILVUS_ADDRESS=your-zilliz-cloud-public-endpoint
MILVUS_TOKEN=your-zilliz-cloud-api-key
```
> 💡 **Tip**: For easier configuration management across different usage scenarios, consider using [global environment variables](../../docs/getting-started/environment-variables.md).
## Quick Start
```typescript
import {
Context,
OpenAIEmbedding,
MilvusVectorDatabase
} from '@zilliz/claude-context-core';
// Initialize embedding provider
const embedding = new OpenAIEmbedding({
apiKey: process.env.OPENAI_API_KEY || 'your-openai-api-key',
model: 'text-embedding-3-small'
});
// Initialize vector database
const vectorDatabase = new MilvusVectorDatabase({
address: process.env.MILVUS_ADDRESS || 'localhost:19530',
token: process.env.MILVUS_TOKEN || ''
});
// Create context instance
const context = new Context({
embedding,
vectorDatabase
});
// Index a codebase
const stats = await context.indexCodebase('./my-project', (progress) => {
console.log(`${progress.phase} - ${progress.percentage}%`);
});
console.log(`Indexed ${stats.indexedFiles} files with ${stats.totalChunks} chunks`);
// Search the codebase
const results = await context.semanticSearch(
'./my-project',
'function that handles user authentication',
5
);
results.forEach(result => {
console.log(`${result.relativePath}:${result.startLine}-${result.endLine}`);
console.log(`Score: ${result.score}`);
console.log(result.content);
});
```
## Features
- **Multi-language Support**: Index TypeScript, JavaScript, Python, Java, C++, and many other programming languages
- **Semantic Search**: Find code using natural language queries powered by AI embeddings
- **Flexible Architecture**: Pluggable embedding providers and vector databases
- **Smart Chunking**: Intelligent code splitting that preserves context and structure
- **Batch Processing**: Efficient processing of large codebases with progress tracking
- **Pattern Matching**: Built-in ignore patterns for common build artifacts and dependencies
- **Incremental File Synchronization**: Efficient change detection using Merkle trees to only re-index modified files
## Embedding Providers
- **OpenAI Embeddings** (`text-embedding-3-small`, `text-embedding-3-large`, `text-embedding-ada-002`)
- **VoyageAI Embeddings** - High-quality embeddings optimized for code (`voyage-code-3`, `voyage-3.5`, etc.)
- **Gemini Embeddings** - Google's embedding models (`gemini-embedding-001`)
- **Ollama Embeddings** - Local embedding models via Ollama
## Vector Database Support
- **Milvus/Zilliz Cloud** - High-performance vector database
## Code Splitters
- **AST Code Splitter** - AST-based code splitting with automatic fallback (default)
- **LangChain Code Splitter** - Character-based code chunking
## Configuration
### ContextConfig
```typescript
interface ContextConfig {
embedding?: Embedding; // Embedding provider
vectorDatabase?: VectorDatabase; // Vector database instance (required)
codeSplitter?: Splitter; // Code splitting strategy
supportedExtensions?: string[]; // File extensions to index
ignorePatterns?: string[]; // Patterns to ignore
customExtensions?: string[]; // Custom extensions from MCP
customIgnorePatterns?: string[]; // Custom ignore patterns from MCP
}
```
### Supported File Extensions (Default)
```typescript
[
// Programming languages
'.ts', '.tsx', '.js', '.jsx', '.py', '.java', '.cpp', '.c', '.h', '.hpp',
'.cs', '.go', '.rs', '.php', '.rb', '.swift', '.kt', '.scala', '.m', '.mm',
// Text and markup files
'.md', '.markdown', '.ipynb'
]
```
### Default Ignore Patterns
- Build and dependency directories: `node_modules/**`, `dist/**`, `build/**`, `out/**`, `target/**`
- Version control: `.git/**`, `.svn/**`, `.hg/**`
- IDE files: `.vscode/**`, `.idea/**`, `*.swp`, `*.swo`
- Cache directories: `.cache/**`, `__pycache__/**`, `.pytest_cache/**`, `coverage/**`
- Minified files: `*.min.js`, `*.min.css`, `*.bundle.js`, `*.map`
- Log and temp files: `logs/**`, `tmp/**`, `temp/**`, `*.log`
- Environment files: `.env`, `.env.*`, `*.local`
## API Reference
### Context
#### Methods
- `indexCodebase(path, progressCallback?, forceReindex?)` - Index an entire codebase
- `reindexByChange(path, progressCallback?)` - Incrementally re-index only changed files
- `semanticSearch(path, query, topK?, threshold?, filterExpr?)` - Search indexed code semantically
- `hasIndex(path)` - Check if codebase is already indexed
- `clearIndex(path, progressCallback?)` - Remove index for a codebase
- `updateIgnorePatterns(patterns)` - Update ignore patterns
- `addCustomIgnorePatterns(patterns)` - Add custom ignore patterns
- `addCustomExtensions(extensions)` - Add custom file extensions
- `updateEmbedding(embedding)` - Switch embedding provider
- `updateVectorDatabase(vectorDB)` - Switch vector database
- `updateSplitter(splitter)` - Switch code splitter
### Search Results
```typescript
interface SemanticSearchResult {
content: string; // Code content
relativePath: string; // File path relative to codebase root
startLine: number; // Starting line number
endLine: number; // Ending line number
language: string; // Programming language
score: number; // Similarity score (0-1)
}
```
## Examples
### Using VoyageAI Embeddings
```typescript
import { Context, MilvusVectorDatabase, VoyageAIEmbedding } from '@zilliz/claude-context-core';
// Initialize with VoyageAI embedding provider
const embedding = new VoyageAIEmbedding({
apiKey: process.env.VOYAGEAI_API_KEY || 'your-voyageai-api-key',
model: 'voyage-code-3'
});
const vectorDatabase = new MilvusVectorDatabase({
address: process.env.MILVUS_ADDRESS || 'localhost:19530',
token: process.env.MILVUS_TOKEN || ''
});
const context = new Context({
embedding,
vectorDatabase
});
```
### Custom File Filtering
```typescript
const context = new Context({
embedding,
vectorDatabase,
supportedExtensions: ['.ts', '.js', '.py', '.java'],
ignorePatterns: [
'node_modules/**',
'dist/**',
'*.spec.ts',
'*.test.js'
]
});
```
## File Synchronization Architecture
Claude Context implements an intelligent file synchronization system that efficiently tracks and processes only the files that have changed since the last indexing operation. This dramatically improves performance when working with large codebases.

### How It Works
The file synchronization system uses a **Merkle tree-based approach** combined with SHA-256 file hashing to detect changes:
#### 1. File Hashing
- Each file in the codebase is hashed using SHA-256
- File hashes are computed based on file content, not metadata
- Hashes are stored with relative file paths for consistency across different environments
#### 2. Merkle Tree Construction
- All file hashes are organized into a Merkle tree structure
- The tree provides a single root hash that represents the entire codebase state
- Any change to any file will cause the root hash to change
#### 3. Snapshot Management
- File synchronization state is persisted to `~/.context/merkle/` directory
- Each codebase gets a unique snapshot file based on its absolute path hash
- Snapshots contain both file hashes and serialized Merkle tree data
#### 4. Change Detection Process
1. **Quick Check**: Compare current Merkle root hash with stored snapshot
2. **Detailed Analysis**: If root hashes differ, perform file-by-file comparison
3. **Change Classification**: Categorize changes into three types:
- **Added**: New files that didn't exist before
- **Modified**: Existing files with changed content
- **Removed**: Files that were deleted from the codebase
#### 5. Incremental Updates
- Only process files that have actually changed
- Update vector database entries only for modified chunks
- Remove entries for deleted files
- Add entries for new files
## Contributing
This package is part of the Claude Context monorepo. Please see:
- [Main Contributing Guide](../../CONTRIBUTING.md) - General contribution guidelines
- [Core Package Contributing](CONTRIBUTING.md) - Specific development guide for this package
## Related Packages
- **[@claude-context/mcp](../mcp)** - MCP server that uses this core engine
- **[VSCode Extension](../vscode-extension)** - VSCode extension built on this core
## License
MIT - See [LICENSE](../../LICENSE) for details
```
--------------------------------------------------------------------------------
/packages/mcp/README.md:
--------------------------------------------------------------------------------
```markdown
# @zilliz/claude-context-mcp

Model Context Protocol (MCP) integration for Claude Context - A powerful MCP server that enables AI assistants and agents to index and search codebases using semantic search.
[](https://www.npmjs.com/package/@zilliz/claude-context-mcp)
[](https://www.npmjs.com/package/@zilliz/claude-context-mcp)
> 📖 **New to Claude Context?** Check out the [main project README](../../README.md) for an overview and setup instructions.
## 🚀 Use Claude Context as MCP in Claude Code and others

Model Context Protocol (MCP) allows you to integrate Claude Context with your favorite AI coding assistants, e.g. Claude Code.
## Quick Start
### Prerequisites
Before using the MCP server, make sure you have:
- API key for your chosen embedding provider (OpenAI, VoyageAI, Gemini, or Ollama setup)
- Milvus vector database (local or cloud)
> 💡 **Setup Help:** See the [main project setup guide](../../README.md#-quick-start) for detailed installation instructions.
### Prepare Environment Variables
#### Embedding Provider Configuration
Claude Context MCP supports multiple embedding providers. Choose the one that best fits your needs:
> 📋 **Quick Reference**: For a complete list of environment variables and their descriptions, see the [Environment Variables Guide](../../docs/getting-started/environment-variables.md).
```bash
# Supported providers: OpenAI, VoyageAI, Gemini, Ollama
EMBEDDING_PROVIDER=OpenAI
```
<details>
<summary><strong>1. OpenAI Configuration (Default)</strong></summary>
OpenAI provides high-quality embeddings with excellent performance for code understanding.
```bash
# Required: Your OpenAI API key
OPENAI_API_KEY=sk-your-openai-api-key
# Optional: Specify embedding model (default: text-embedding-3-small)
EMBEDDING_MODEL=text-embedding-3-small
# Optional: Custom API base URL (for Azure OpenAI or other compatible services)
OPENAI_BASE_URL=https://api.openai.com/v1
```
**Available Models:**
See `getSupportedModels` in [`openai-embedding.ts`](https://github.com/zilliztech/claude-context/blob/master/packages/core/src/embedding/openai-embedding.ts) for the full list of supported models.
**Getting API Key:**
1. Visit [OpenAI Platform](https://platform.openai.com/api-keys)
2. Sign in or create an account
3. Generate a new API key
4. Set up billing if needed
</details>
<details>
<summary><strong>2. VoyageAI Configuration</strong></summary>
VoyageAI offers specialized code embeddings optimized for programming languages.
```bash
# Required: Your VoyageAI API key
VOYAGEAI_API_KEY=pa-your-voyageai-api-key
# Optional: Specify embedding model (default: voyage-code-3)
EMBEDDING_MODEL=voyage-code-3
```
**Available Models:**
See `getSupportedModels` in [`voyageai-embedding.ts`](https://github.com/zilliztech/claude-context/blob/master/packages/core/src/embedding/voyageai-embedding.ts) for the full list of supported models.
**Getting API Key:**
1. Visit [VoyageAI Console](https://dash.voyageai.com/)
2. Sign up for an account
3. Navigate to API Keys section
4. Create a new API key
</details>
<details>
<summary><strong>3. Gemini Configuration</strong></summary>
Google's Gemini provides competitive embeddings with good multilingual support.
```bash
# Required: Your Gemini API key
GEMINI_API_KEY=your-gemini-api-key
# Optional: Specify embedding model (default: gemini-embedding-001)
EMBEDDING_MODEL=gemini-embedding-001
# Optional: Custom API base URL (for custom endpoints)
GEMINI_BASE_URL=https://generativelanguage.googleapis.com/v1beta
```
**Available Models:**
See `getSupportedModels` in [`gemini-embedding.ts`](https://github.com/zilliztech/claude-context/blob/master/packages/core/src/embedding/gemini-embedding.ts) for the full list of supported models.
**Getting API Key:**
1. Visit [Google AI Studio](https://aistudio.google.com/)
2. Sign in with your Google account
3. Go to "Get API key" section
4. Create a new API key
</details>
<details>
<summary><strong>4. Ollama Configuration (Local/Self-hosted)</strong></summary>
Ollama allows you to run embeddings locally without sending data to external services.
```bash
# Required: Specify which Ollama model to use
EMBEDDING_MODEL=nomic-embed-text
# Optional: Specify Ollama host (default: http://127.0.0.1:11434)
OLLAMA_HOST=http://127.0.0.1:11434
```
**Setup Instructions:**
1. Install Ollama from [ollama.ai](https://ollama.ai/)
2. Pull the embedding model:
```bash
ollama pull nomic-embed-text
```
3. Ensure Ollama is running:
```bash
ollama serve
```
</details>
#### Get a free vector database on Zilliz Cloud
Claude Context needs a vector database. You can [sign up](https://cloud.zilliz.com/signup?utm_source=github&utm_medium=referral&utm_campaign=2507-codecontext-readme) on Zilliz Cloud to get an API key.

Copy your Personal Key to replace `your-zilliz-cloud-api-key` in the configuration examples.
```bash
MILVUS_TOKEN=your-zilliz-cloud-api-key
```
#### Embedding Batch Size
You can set the embedding batch size to optimize the performance of the MCP server, depending on your embedding model throughput. The default value is 100.
```bash
EMBEDDING_BATCH_SIZE=512
```
#### Custom File Processing (Optional)
You can configure custom file extensions and ignore patterns globally via environment variables:
```bash
# Additional file extensions to include beyond defaults
CUSTOM_EXTENSIONS=.vue,.svelte,.astro,.twig
# Additional ignore patterns to exclude files/directories
CUSTOM_IGNORE_PATTERNS=temp/**,*.backup,private/**,uploads/**
```
These settings work in combination with tool parameters - patterns from both sources will be merged together.
## Usage with MCP Clients
<details>
<summary><strong>Claude Code</strong></summary>
Use the command line interface to add the Claude Context MCP server:
```bash
# Add the Claude Context MCP server
claude mcp add claude-context -e OPENAI_API_KEY=your-openai-api-key -e MILVUS_TOKEN=your-zilliz-cloud-api-key -- npx @zilliz/claude-context-mcp@latest
```
See the [Claude Code MCP documentation](https://docs.anthropic.com/en/docs/claude-code/mcp) for more details about MCP server management.
</details>
<details>
<summary><strong>OpenAI Codex CLI</strong></summary>
Codex CLI uses TOML configuration files:
1. Create or edit the `~/.codex/config.toml` file.
2. Add the following configuration:
```toml
# IMPORTANT: the top-level key is `mcp_servers` rather than `mcpServers`.
[mcp_servers.claude-context]
command = "npx"
args = ["@zilliz/claude-context-mcp@latest"]
env = { "OPENAI_API_KEY" = "your-openai-api-key", "MILVUS_TOKEN" = "your-zilliz-cloud-api-key" }
# Optional: override the default 10s startup timeout
startup_timeout_ms = 20000
```
3. Save the file and restart Codex CLI to apply the changes.
</details>
<details>
<summary><strong>Gemini CLI</strong></summary>
Gemini CLI requires manual configuration through a JSON file:
1. Create or edit the `~/.gemini/settings.json` file.
2. Add the following configuration:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
3. Save the file and restart Gemini CLI to apply the changes.
</details>
<details>
<summary><strong>Qwen Code</strong></summary>
Create or edit the `~/.qwen/settings.json` file and add the following configuration:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Cursor</strong></summary>
Go to: `Settings` -> `Cursor Settings` -> `MCP` -> `Add new global MCP server`
Pasting the following configuration into your Cursor `~/.cursor/mcp.json` file is the recommended approach. You may also install in a specific project by creating `.cursor/mcp.json` in your project folder. See [Cursor MCP docs](https://docs.cursor.com/context/model-context-protocol) for more info.
**OpenAI Configuration (Default):**
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"EMBEDDING_PROVIDER": "OpenAI",
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
**VoyageAI Configuration:**
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"EMBEDDING_PROVIDER": "VoyageAI",
"VOYAGEAI_API_KEY": "your-voyageai-api-key",
"EMBEDDING_MODEL": "voyage-code-3",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
**Gemini Configuration:**
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"EMBEDDING_PROVIDER": "Gemini",
"GEMINI_API_KEY": "your-gemini-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
**Ollama Configuration:**
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"EMBEDDING_PROVIDER": "Ollama",
"EMBEDDING_MODEL": "nomic-embed-text",
"OLLAMA_HOST": "http://127.0.0.1:11434",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Void</strong></summary>
Go to: `Settings` -> `MCP` -> `Add MCP Server`
Add the following configuration to your Void MCP settings:
```json
{
"mcpServers": {
"code-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Claude Desktop</strong></summary>
Add to your Claude Desktop configuration:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Windsurf</strong></summary>
Windsurf supports MCP configuration through a JSON file. Add the following configuration to your Windsurf MCP settings:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>VS Code</strong></summary>
The Claude Context MCP server can be used with VS Code through MCP-compatible extensions. Add the following configuration to your VS Code MCP settings:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Cherry Studio</strong></summary>
Cherry Studio allows for visual MCP server configuration through its settings interface. While it doesn't directly support manual JSON configuration, you can add a new server via the GUI:
1. Navigate to **Settings → MCP Servers → Add Server**.
2. Fill in the server details:
- **Name**: `claude-context`
- **Type**: `STDIO`
- **Command**: `npx`
- **Arguments**: `["@zilliz/claude-context-mcp@latest"]`
- **Environment Variables**:
- `OPENAI_API_KEY`: `your-openai-api-key`
- `MILVUS_TOKEN`: `your-zilliz-cloud-api-key`
3. Save the configuration to activate the server.
</details>
<details>
<summary><strong>Cline</strong></summary>
Cline uses a JSON configuration file to manage MCP servers. To integrate the provided MCP server configuration:
1. Open Cline and click on the **MCP Servers** icon in the top navigation bar.
2. Select the **Installed** tab, then click **Advanced MCP Settings**.
3. In the `cline_mcp_settings.json` file, add the following configuration:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
4. Save the file.
</details>
<details>
<summary><strong>Augment</strong></summary>
To configure Claude Context MCP in Augment Code, you can use either the graphical interface or manual configuration.
#### **A. Using the Augment Code UI**
1. Click the hamburger menu.
2. Select **Settings**.
3. Navigate to the **Tools** section.
4. Click the **+ Add MCP** button.
5. Enter the following command:
```
npx @zilliz/claude-context-mcp@latest
```
6. Name the MCP: **Claude Context**.
7. Click the **Add** button.
------
#### **B. Manual Configuration**
1. Press Cmd/Ctrl Shift P or go to the hamburger menu in the Augment panel
2. Select Edit Settings
3. Under Advanced, click Edit in settings.json
4. Add the server configuration to the `mcpServers` array in the `augment.advanced` object
```json
"augment.advanced": {
"mcpServers": [
{
"name": "claude-context",
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"]
}
]
}
```
</details>
<details>
<summary><strong>Roo Code</strong></summary>
Roo Code utilizes a JSON configuration file for MCP servers:
1. Open Roo Code and navigate to **Settings → MCP Servers → Edit Global Config**.
2. In the `mcp_settings.json` file, add the following configuration:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
3. Save the file to activate the server.
</details>
<details>
<summary><strong>Zencoder</strong></summary>
Zencoder offers support for MCP tools and servers in both its JetBrains and VS Code plugin versions.
1. Go to the Zencoder menu (...)
2. From the dropdown menu, select `Tools`
3. Click on the `Add Custom MCP`
4. Add the name (i.e. `Claude Context` and server configuration from below, and make sure to hit the `Install` button
```json
{
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
```
5. Save the server by hitting the `Install` button.
</details>
<details>
<summary><strong>LangChain/LangGraph</strong></summary>
For LangChain/LangGraph integration examples, see [this example](https://github.com/zilliztech/claude-context/blob/643796a0d30e706a2a0dff3d55621c9b5d831807/evaluation/retrieval/custom.py#L88).
</details>
<details>
<summary><strong>Other MCP Clients</strong></summary>
The server uses stdio transport and follows the standard MCP protocol. It can be integrated with any MCP-compatible client by running:
```bash
npx @zilliz/claude-context-mcp@latest
```
</details>
## Features
- 🔌 **MCP Protocol Compliance**: Full compatibility with MCP-enabled AI assistants and agents
- 🔍 **Hybrid Code Search**: Natural language queries using advanced hybrid search (BM25 + dense vector) to find relevant code snippets
- 📁 **Codebase Indexing**: Index entire codebases for fast hybrid search across millions of lines of code
- 🔄 **Incremental Indexing**: Efficiently re-index only changed files using Merkle trees for auto-sync
- 🧩 **Intelligent Code Chunking**: AST-based code analysis for syntax-aware chunking with automatic fallback
- 🗄️ **Scalable**: Integrates with Zilliz Cloud for scalable vector search, no matter how large your codebase is
- 🛠️ **Customizable**: Configure file extensions, ignore patterns, and embedding models
- ⚡ **Real-time**: Interactive indexing and searching with progress feedback
## Available Tools
### 1. `index_codebase`
Index a codebase directory for hybrid search (BM25 + dense vector).
**Parameters:**
- `path` (required): Absolute path to the codebase directory to index
- `force` (optional): Force re-indexing even if already indexed (default: false)
- `splitter` (optional): Code splitter to use - 'ast' for syntax-aware splitting with automatic fallback, 'langchain' for character-based splitting (default: "ast")
- `customExtensions` (optional): Additional file extensions to include beyond defaults (e.g., ['.vue', '.svelte', '.astro']). Extensions should include the dot prefix or will be automatically added (default: [])
- `ignorePatterns` (optional): Additional ignore patterns to exclude specific files/directories beyond defaults (e.g., ['static/**', '*.tmp', 'private/**']) (default: [])
### 2. `search_code`
Search the indexed codebase using natural language queries with hybrid search (BM25 + dense vector).
**Parameters:**
- `path` (required): Absolute path to the codebase directory to search in
- `query` (required): Natural language query to search for in the codebase
- `limit` (optional): Maximum number of results to return (default: 10, max: 50)
- `extensionFilter` (optional): List of file extensions to filter results (e.g., ['.ts', '.py']) (default: [])
### 3. `clear_index`
Clear the search index for a specific codebase.
**Parameters:**
- `path` (required): Absolute path to the codebase directory to clear index for
### 4. `get_indexing_status`
Get the current indexing status of a codebase. Shows progress percentage for actively indexing codebases and completion status for indexed codebases.
**Parameters:**
- `path` (required): Absolute path to the codebase directory to check status for
## Contributing
This package is part of the Claude Context monorepo. Please see:
- [Main Contributing Guide](../../CONTRIBUTING.md) - General contribution guidelines
- [MCP Package Contributing](CONTRIBUTING.md) - Specific development guide for this package
## Related Projects
- **[@zilliz/claude-context-core](../core)** - Core indexing engine used by this MCP server
- **[VSCode Extension](../vscode-extension)** - Alternative VSCode integration
- [Model Context Protocol](https://modelcontextprotocol.io/) - Official MCP documentation
## License
MIT - See [LICENSE](../../LICENSE) for details
```
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
```markdown

### Your entire codebase as Claude's context
[](https://opensource.org/licenses/MIT)
[](https://nodejs.org/)
[](docs/)
[](https://marketplace.visualstudio.com/items?itemName=zilliz.semanticcodesearch)
[](https://www.npmjs.com/package/@zilliz/claude-context-core)
[](https://www.npmjs.com/package/@zilliz/claude-context-mcp)
[](https://twitter.com/zilliz_universe)
[](https://deepwiki.com/zilliztech/claude-context)
<a href="https://discord.gg/mKc3R95yE5"><img height="20" src="https://img.shields.io/badge/Discord-%235865F2.svg?style=for-the-badge&logo=discord&logoColor=white" alt="discord" /></a>
</div>
**Claude Context** is an MCP plugin that adds semantic code search to Claude Code and other AI coding agents, giving them deep context from your entire codebase.
🧠 **Your Entire Codebase as Context**: Claude Context uses semantic search to find all relevant code from millions of lines. No multi-round discovery needed. It brings results straight into the Claude's context.
💰 **Cost-Effective for Large Codebases**: Instead of loading entire directories into Claude for every request, which can be very expensive, Claude Context efficiently stores your codebase in a vector database and only uses related code in context to keep your costs manageable.
---
## 🚀 Demo

Model Context Protocol (MCP) allows you to integrate Claude Context with your favorite AI coding assistants, e.g. Claude Code.
## Quick Start
### Prerequisites
<details>
<summary>Get a free vector database on Zilliz Cloud 👈</summary>
Claude Context needs a vector database. You can [sign up](https://cloud.zilliz.com/signup?utm_source=github&utm_medium=referral&utm_campaign=2507-codecontext-readme) on Zilliz Cloud to get an API key.

Copy your Personal Key to replace `your-zilliz-cloud-api-key` in the configuration examples.
</details>
<details>
<summary>Get OpenAI API Key for embedding model</summary>
You need an OpenAI API key for the embedding model. You can get one by signing up at [OpenAI](https://platform.openai.com/api-keys).
Your API key will look like this: it always starts with `sk-`.
Copy your key and use it in the configuration examples below as `your-openai-api-key`.
</details>
### Configure MCP for Claude Code
**System Requirements:**
- Node.js >= 20.0.0 and < 24.0.0
> Claude Context is not compatible with Node.js 24.0.0, you need downgrade it first if your node version is greater or equal to 24.
#### Configuration
Use the command line interface to add the Claude Context MCP server:
```bash
claude mcp add claude-context \
-e OPENAI_API_KEY=sk-your-openai-api-key \
-e MILVUS_TOKEN=your-zilliz-cloud-api-key \
-- npx @zilliz/claude-context-mcp@latest
```
See the [Claude Code MCP documentation](https://docs.anthropic.com/en/docs/claude-code/mcp) for more details about MCP server management.
### Other MCP Client Configurations
<details>
<summary><strong>OpenAI Codex CLI</strong></summary>
Codex CLI uses TOML configuration files:
1. Create or edit the `~/.codex/config.toml` file.
2. Add the following configuration:
```toml
# IMPORTANT: the top-level key is `mcp_servers` rather than `mcpServers`.
[mcp_servers.claude-context]
command = "npx"
args = ["@zilliz/claude-context-mcp@latest"]
env = { "OPENAI_API_KEY" = "your-openai-api-key", "MILVUS_TOKEN" = "your-zilliz-cloud-api-key" }
# Optional: override the default 10s startup timeout
startup_timeout_ms = 20000
```
3. Save the file and restart Codex CLI to apply the changes.
</details>
<details>
<summary><strong>Gemini CLI</strong></summary>
Gemini CLI requires manual configuration through a JSON file:
1. Create or edit the `~/.gemini/settings.json` file.
2. Add the following configuration:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
3. Save the file and restart Gemini CLI to apply the changes.
</details>
<details>
<summary><strong>Qwen Code</strong></summary>
Create or edit the `~/.qwen/settings.json` file and add the following configuration:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Cursor</strong></summary>
<a href="https://cursor.com/install-mcp?name=claude-context&config=JTdCJTIyY29tbWFuZCUyMiUzQSUyMm5weCUyMC15JTIwJTQwemlsbGl6JTJGY29kZS1jb250ZXh0LW1jcCU0MGxhdGVzdCUyMiUyQyUyMmVudiUyMiUzQSU3QiUyMk9QRU5BSV9BUElfS0VZJTIyJTNBJTIyeW91ci1vcGVuYWktYXBpLWtleSUyMiUyQyUyMk1JTFZVU19BRERSRVNTJTIyJTNBJTIybG9jYWxob3N0JTNBMTk1MzAlMjIlN0QlN0Q%3D"><img src="https://cursor.com/deeplink/mcp-install-dark.svg" alt="Add claude-context MCP server to Cursor" height="32" /></a>
Go to: `Settings` -> `Cursor Settings` -> `MCP` -> `Add new global MCP server`
Pasting the following configuration into your Cursor `~/.cursor/mcp.json` file is the recommended approach. You may also install in a specific project by creating `.cursor/mcp.json` in your project folder. See [Cursor MCP docs](https://docs.cursor.com/context/model-context-protocol) for more info.
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Void</strong></summary>
Go to: `Settings` -> `MCP` -> `Add MCP Server`
Add the following configuration to your Void MCP settings:
```json
{
"mcpServers": {
"code-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Claude Desktop</strong></summary>
Add to your Claude Desktop configuration:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Windsurf</strong></summary>
Windsurf supports MCP configuration through a JSON file. Add the following configuration to your Windsurf MCP settings:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>VS Code</strong></summary>
The Claude Context MCP server can be used with VS Code through MCP-compatible extensions. Add the following configuration to your VS Code MCP settings:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Cherry Studio</strong></summary>
Cherry Studio allows for visual MCP server configuration through its settings interface. While it doesn't directly support manual JSON configuration, you can add a new server via the GUI:
1. Navigate to **Settings → MCP Servers → Add Server**.
2. Fill in the server details:
- **Name**: `claude-context`
- **Type**: `STDIO`
- **Command**: `npx`
- **Arguments**: `["@zilliz/claude-context-mcp@latest"]`
- **Environment Variables**:
- `OPENAI_API_KEY`: `your-openai-api-key`
- `MILVUS_ADDRESS`: `your-zilliz-cloud-public-endpoint`
- `MILVUS_TOKEN`: `your-zilliz-cloud-api-key`
3. Save the configuration to activate the server.
</details>
<details>
<summary><strong>Cline</strong></summary>
Cline uses a JSON configuration file to manage MCP servers. To integrate the provided MCP server configuration:
1. Open Cline and click on the **MCP Servers** icon in the top navigation bar.
2. Select the **Installed** tab, then click **Advanced MCP Settings**.
3. In the `cline_mcp_settings.json` file, add the following configuration:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
4. Save the file.
</details>
<details>
<summary><strong>Augment</strong></summary>
To configure Claude Context MCP in Augment Code, you can use either the graphical interface or manual configuration.
#### **A. Using the Augment Code UI**
1. Click the hamburger menu.
2. Select **Settings**.
3. Navigate to the **Tools** section.
4. Click the **+ Add MCP** button.
5. Enter the following command:
```
npx @zilliz/claude-context-mcp@latest
```
6. Name the MCP: **Claude Context**.
7. Click the **Add** button.
------
#### **B. Manual Configuration**
1. Press Cmd/Ctrl Shift P or go to the hamburger menu in the Augment panel
2. Select Edit Settings
3. Under Advanced, click Edit in settings.json
4. Add the server configuration to the `mcpServers` array in the `augment.advanced` object
```json
"augment.advanced": {
"mcpServers": [
{
"name": "claude-context",
"command": "npx",
"args": ["-y", "@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
]
}
```
</details>
<details>
<summary><strong>Roo Code</strong></summary>
Roo Code utilizes a JSON configuration file for MCP servers:
1. Open Roo Code and navigate to **Settings → MCP Servers → Edit Global Config**.
2. In the `mcp_settings.json` file, add the following configuration:
```json
{
"mcpServers": {
"claude-context": {
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
3. Save the file to activate the server.
</details>
<details>
<summary><strong>Zencoder</strong></summary>
Zencoder offers support for MCP tools and servers in both its JetBrains and VS Code plugin versions.
1. Go to the Zencoder menu (...)
2. From the dropdown menu, select `Tools`
3. Click on the `Add Custom MCP`
4. Add the name (i.e. `Claude Context` and server configuration from below, and make sure to hit the `Install` button
```json
{
"command": "npx",
"args": ["@zilliz/claude-context-mcp@latest"],
"env": {
"OPENAI_API_KEY": "your-openai-api-key",
"MILVUS_ADDRESS": "your-zilliz-cloud-public-endpoint",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
```
5. Save the server by hitting the `Install` button.
</details>
<details>
<summary><strong>LangChain/LangGraph</strong></summary>
For LangChain/LangGraph integration examples, see [this example](https://github.com/zilliztech/claude-context/blob/643796a0d30e706a2a0dff3d55621c9b5d831807/evaluation/retrieval/custom.py#L88).
</details>
<details>
<summary><strong>Other MCP Clients</strong></summary>
The server uses stdio transport and follows the standard MCP protocol. It can be integrated with any MCP-compatible client by running:
```bash
npx @zilliz/claude-context-mcp@latest
```
</details>
---
### Usage in Your Codebase
1. **Open Claude Code**
```
cd your-project-directory
claude
```
2. **Index your codebase**:
```
Index this codebase
```
3. **Check indexing status**:
```
Check the indexing status
```
4. **Start searching**:
```
Find functions that handle user authentication
```
🎉 **That's it!** You now have semantic code search in Claude Code.
---
### Environment Variables Configuration
For more detailed MCP environment variable configuration, see our [Environment Variables Guide](docs/getting-started/environment-variables.md).
### Using Different Embedding Models
To configure custom embedding models (e.g., `text-embedding-3-large` for OpenAI, `voyage-code-3` for VoyageAI), see the [MCP Configuration Examples](packages/mcp/README.md#embedding-provider-configuration) for detailed setup instructions for each provider.
### File Inclusion & Exclusion Rules
For detailed explanation of file inclusion and exclusion rules, and how to customize them, see our [File Inclusion & Exclusion Rules](docs/dive-deep/file-inclusion-rules.md).
### Available Tools
#### 1. `index_codebase`
Index a codebase directory for hybrid search (BM25 + dense vector).
#### 2. `search_code`
Search the indexed codebase using natural language queries with hybrid search (BM25 + dense vector).
#### 3. `clear_index`
Clear the search index for a specific codebase.
#### 4. `get_indexing_status`
Get the current indexing status of a codebase. Shows progress percentage for actively indexing codebases and completion status for indexed codebases.
---
## 📊 Evaluation
Our controlled evaluation demonstrates that Claude Context MCP achieves ~40% token reduction under the condition of equivalent retrieval quality. This translates to significant cost and time savings in production environments. This also means that, under the constraint of limited token context length, using Claude Context yields better retrieval and answer results.

For detailed evaluation methodology and results, see the [evaluation directory](evaluation/).
---
## 🏗️ Architecture

### 🔧 Implementation Details
- 🔍 **Hybrid Code Search**: Ask questions like *"find functions that handle user authentication"* and get relevant, context-rich code instantly using advanced hybrid search (BM25 + dense vector).
- 🧠 **Context-Aware**: Discover large codebase, understand how different parts of your codebase relate, even across millions of lines of code.
- ⚡ **Incremental Indexing**: Efficiently re-index only changed files using Merkle trees.
- 🧩 **Intelligent Code Chunking**: Analyze code in Abstract Syntax Trees (AST) for chunking.
- 🗄️ **Scalable**: Integrates with Zilliz Cloud for scalable vector search, no matter how large your codebase is.
- 🛠️ **Customizable**: Configure file extensions, ignore patterns, and embedding models.
### Core Components
Claude Context is a monorepo containing three main packages:
- **`@zilliz/claude-context-core`**: Core indexing engine with embedding and vector database integration
- **VSCode Extension**: Semantic Code Search extension for Visual Studio Code
- **`@zilliz/claude-context-mcp`**: Model Context Protocol server for AI agent integration
### Supported Technologies
- **Embedding Providers**: [OpenAI](https://openai.com), [VoyageAI](https://voyageai.com), [Ollama](https://ollama.ai), [Gemini](https://gemini.google.com)
- **Vector Databases**: [Milvus](https://milvus.io) or [Zilliz Cloud](https://zilliz.com/cloud)(fully managed vector database as a service)
- **Code Splitters**: AST-based splitter (with automatic fallback), LangChain character-based splitter
- **Languages**: TypeScript, JavaScript, Python, Java, C++, C#, Go, Rust, PHP, Ruby, Swift, Kotlin, Scala, Markdown
- **Development Tools**: VSCode, Model Context Protocol
---
## 📦 Other Ways to Use Claude Context
While MCP is the recommended way to use Claude Context with AI assistants, you can also use it directly or through the VSCode extension.
### Build Applications with Core Package
The `@zilliz/claude-context-core` package provides the fundamental functionality for code indexing and semantic search.
```typescript
import { Context, MilvusVectorDatabase, OpenAIEmbedding } from '@zilliz/claude-context-core';
// Initialize embedding provider
const embedding = new OpenAIEmbedding({
apiKey: process.env.OPENAI_API_KEY || 'your-openai-api-key',
model: 'text-embedding-3-small'
});
// Initialize vector database
const vectorDatabase = new MilvusVectorDatabase({
address: process.env.MILVUS_ADDRESS || 'your-zilliz-cloud-public-endpoint',
token: process.env.MILVUS_TOKEN || 'your-zilliz-cloud-api-key'
});
// Create context instance
const context = new Context({
embedding,
vectorDatabase
});
// Index your codebase with progress tracking
const stats = await context.indexCodebase('./your-project', (progress) => {
console.log(`${progress.phase} - ${progress.percentage}%`);
});
console.log(`Indexed ${stats.indexedFiles} files, ${stats.totalChunks} chunks`);
// Perform semantic search
const results = await context.semanticSearch('./your-project', 'vector database operations', 5);
results.forEach(result => {
console.log(`File: ${result.relativePath}:${result.startLine}-${result.endLine}`);
console.log(`Score: ${(result.score * 100).toFixed(2)}%`);
console.log(`Content: ${result.content.substring(0, 100)}...`);
});
```
### VSCode Extension
Integrates Claude Context directly into your IDE. Provides an intuitive interface for semantic code search and navigation.
1. **Direct Link**: [Install from VS Code Marketplace](https://marketplace.visualstudio.com/items?itemName=zilliz.semanticcodesearch)
2. **Manual Search**:
- Open Extensions view in VSCode (Ctrl+Shift+X or Cmd+Shift+X on Mac)
- Search for "Semantic Code Search"
- Click Install

---
## 🛠️ Development
### Setup Development Environment
#### Prerequisites
- Node.js 20.x or 22.x
- pnpm (recommended package manager)
#### Cross-Platform Setup
```bash
# Clone repository
git clone https://github.com/zilliztech/claude-context.git
cd claude-context
# Install dependencies
pnpm install
# Build all packages
pnpm build
# Start development mode
pnpm dev
```
#### Windows-Specific Setup
On Windows, ensure you have:
- **Git for Windows** with proper line ending configuration
- **Node.js** installed via the official installer or package manager
- **pnpm** installed globally: `npm install -g pnpm`
```powershell
# Windows PowerShell/Command Prompt
git clone https://github.com/zilliztech/claude-context.git
cd claude-context
# Configure git line endings (recommended)
git config core.autocrlf false
# Install dependencies
pnpm install
# Build all packages (uses cross-platform scripts)
pnpm build
# Start development mode
pnpm dev
```
### Building
```bash
# Build all packages (cross-platform)
pnpm build
# Build specific package
pnpm build:core
pnpm build:vscode
pnpm build:mcp
# Performance benchmarking
pnpm benchmark
```
#### Windows Build Notes
- All build scripts are cross-platform compatible using rimraf
- Build caching is enabled for faster subsequent builds
- Use PowerShell or Command Prompt - both work equally well
### Running Examples
```bash
# Development with file watching
cd examples/basic-usage
pnpm dev
```
---
## 📖 Examples
Check the `/examples` directory for complete usage examples:
- **Basic Usage**: Simple indexing and search example
---
## ❓ FAQ
**Common Questions:**
- **[What files does Claude Context decide to embed?](docs/troubleshooting/faq.md#q-what-files-does-claude-context-decide-to-embed)**
- **[Can I use a fully local deployment setup?](docs/troubleshooting/faq.md#q-can-i-use-a-fully-local-deployment-setup)**
- **[Does it support multiple projects / codebases?](docs/troubleshooting/faq.md#q-does-it-support-multiple-projects--codebases)**
- **[How does Claude Context compare to other coding tools?](docs/troubleshooting/faq.md#q-how-does-claude-context-compare-to-other-coding-tools-like-serena-context7-or-deepwiki)**
❓ For detailed answers and more troubleshooting tips, see our [FAQ Guide](docs/troubleshooting/faq.md).
🔧 **Encountering issues?** Visit our [Troubleshooting Guide](docs/troubleshooting/troubleshooting-guide.md) for step-by-step solutions.
📚 **Need more help?** Check out our [complete documentation](docs/) for detailed guides and troubleshooting tips.
---
## 🤝 Contributing
We welcome contributions! Please see our [Contributing Guide](CONTRIBUTING.md) for details on how to get started.
**Package-specific contributing guides:**
- [Core Package Contributing](packages/core/CONTRIBUTING.md)
- [MCP Server Contributing](packages/mcp/CONTRIBUTING.md)
- [VSCode Extension Contributing](packages/vscode-extension/CONTRIBUTING.md)
---
## 🗺️ Roadmap
- [x] AST-based code analysis for improved understanding
- [x] Support for additional embedding providers
- [ ] Agent-based interactive search mode
- [x] Enhanced code chunking strategies
- [ ] Search result ranking optimization
- [ ] Robust Chrome Extension
---
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
---
## 🔗 Links
- [GitHub Repository](https://github.com/zilliztech/claude-context)
- [VSCode Marketplace](https://marketplace.visualstudio.com/items?itemName=zilliz.semanticcodesearch)
- [Milvus Documentation](https://milvus.io/docs)
- [Zilliz Cloud](https://zilliz.com/cloud)
```
--------------------------------------------------------------------------------
/packages/core/CONTRIBUTING.md:
--------------------------------------------------------------------------------
```markdown
# Contributing to @zilliz/claude-context-core
Thanks for your interest in contributing to the Claude Context core package!
> 📖 **First time contributing?** Please read the [main contributing guide](../../CONTRIBUTING.md) first for general setup and workflow.
## Core Package Development
This guide covers development specific to the core indexing engine.
## Development Workflow
### Quick Commands
```bash
# Build core package
pnpm build:core
# Watch mode for development
pnpm dev:core
```
### Making Changes
1. Create a new branch for your feature/fix
2. Make your changes in the `src/` directory
3. Follow the commit guidelines in the [main guide](../../CONTRIBUTING.md)
## Project Structure
- `src/context.ts` - Main Claude Context class
- `src/embedding/` - Embedding providers (OpenAI, VoyageAI, Ollama)
- `src/vectordb/` - Vector database implementations (Milvus)
- `src/splitter/` - Code splitting logic
- `src/types.ts` - TypeScript type definitions
## Guidelines
- Use TypeScript strict mode
- Follow existing code style
- Handle errors gracefully
## Questions?
- **General questions**: See [main contributing guide](../../CONTRIBUTING.md)
- **Core-specific issues**: Open an issue with the `core` label
```
--------------------------------------------------------------------------------
/packages/vscode-extension/CONTRIBUTING.md:
--------------------------------------------------------------------------------
```markdown
# Contributing to VSCode Extension
Thanks for your interest in contributing to the Claude Context VSCode extension!
> 📖 **First time contributing?** Please read the [main contributing guide](../../CONTRIBUTING.md) first for general setup and workflow.
## VSCode Extension Development
This guide covers development specific to the VSCode extension.
### Requirements
- **VSCode Version**: 1.74.0 or higher
### Quick Commands
```bash
# Build VSCode extension
pnpm build:vscode
# Watch mode for development
pnpm dev:vscode
# Package extension
pnpm package
```
### Development Setup
Press `F5` to launch Extension Development Host
## Making Changes
1. Create a new branch for your feature/fix
2. Make changes in the `src/` directory
3. Run in the Extension Development Host
4. Follow commit guidelines in the [main guide](../../CONTRIBUTING.md)
## Project Structure
- `src/extension.ts` - Main extension entry point
- `src/` - Extension source code
- `resources/` - Icons and assets
- `package.json` - Extension manifest and commands
- `webpack.config.js` - Build configuration
## Development Workflow
1. Press `F5` in VSCode to open Extension Development Host
2. Try all commands and features
3. Check the Output panel for errors
4. Try with different project types
## Guidelines
- Follow VSCode extension best practices
- Use TypeScript for all code
- Keep UI responsive and non-blocking
- Provide user feedback for long operations
- Handle errors gracefully with user-friendly messages
## Extension Features
- Semantic code search within VSCode
- Integration with Claude Context core
- Progress indicators for indexing
- Search results in sidebar
## Working in VSCode
### Extension Development Host
- Press `F5` to open a new VSCode window with your extension loaded
- Try the extension in the new window with real codebases
- Check the Developer Console (`Help > Toggle Developer Tools`) for errors
### Manual Verification Checklist
- [ ] Index a sample codebase successfully
- [ ] Search returns relevant results
- [ ] UI components display correctly
- [ ] Configuration settings work properly
- [ ] Commands execute without errors
## Testing with .vsix Package
For a more robust pre-production test (safer than F5 development mode), you can package and install the extension locally:
```bash
# Navigate to extension directory
cd packages/vscode-extension
# Package the extension (remove existing .vsix file if present)
pnpm run package
# Uninstall any existing version
code --uninstall-extension semanticcodesearch-xxx.vsix
# Install the packaged extension
code --install-extension semanticcodesearch-xxx.vsix
```
After installation, the extension will be available in VSCode just like any marketplace extension. This method:
- Tests the actual packaged version
- Simulates real user installation experience
- Provides better isolation from development environment
- **Recommended for final testing before production release**
## Publishing
> **Note**: Only maintainers can publish to VS Code Marketplace
## Questions?
- **General questions**: See [main contributing guide](../../CONTRIBUTING.md)
- **VSCode-specific issues**: Open an issue with the `vscode` label
```
--------------------------------------------------------------------------------
/packages/mcp/CONTRIBUTING.md:
--------------------------------------------------------------------------------
```markdown
# Contributing to @zilliz/claude-context-mcp
Thanks for your interest in contributing to the Claude Context MCP server!
> 📖 **First time contributing?** Please read the [main contributing guide](../../CONTRIBUTING.md) first for general setup and workflow.
## MCP Server Development
This guide covers development specific to the MCP server.
### Quick Commands
```bash
# Build MCP server
pnpm build:mcp
# Watch mode for development
pnpm dev:mcp
# Start server
pnpm start
# Run with environment variables
pnpm start:with-env
```
### Required Environment Variables
See [README.md](./README.md#prepare-environment-variables) for required environment variables.
## Running the MCP Server
1. Build the server:
```bash
pnpm build
```
2. Run with MCP client or directly:
```bash
pnpm start
```
3. Use the tools:
- `index_codebase` - Index a sample codebase with optional custom ignore patterns
- `search_code` - Search for code snippets
- `clear_index` - Clear the index
## Making Changes
1. Create a new branch for your feature/fix
2. Edit `src/index.ts` - Main MCP server implementation
3. Verify with MCP clients (Claude Desktop, etc.)
4. Follow commit guidelines in the [main guide](../../CONTRIBUTING.md)
## MCP Protocol
- Follow [MCP specification](https://modelcontextprotocol.io/)
- Use stdio transport for compatibility
- Handle errors gracefully with proper MCP responses
- Redirect logs to stderr (not stdout)
## Tool Parameters
### `index_codebase`
- `path` (required): Path to the codebase directory
- `force` (optional): Force re-indexing even if already indexed (default: false)
- `splitter` (optional): Code splitter type - 'ast' or 'langchain' (default: 'ast')
- `ignorePatterns` (optional): Additional ignore patterns to add to defaults (default: [])
- Examples: `["static/**", "*.tmp", "private/**", "docs/generated/**"]`
- Merged with default patterns (node_modules, .git, etc.)
### `search_code`
- `path` (required): Path to the indexed codebase
- `query` (required): Natural language search query
- `limit` (optional): Maximum number of results (default: 10, max: 50)
### `clear_index`
- `path` (required): Path to the codebase to clear
## Guidelines
- Keep tool interfaces simple and intuitive
- Provide clear error messages
- Validate all user inputs
- Use TypeScript for type safety
## Working with MCP Clients
### Cursor/Claude Desktop Development Mode Configuration
You can use the following configuration to configure the MCP server with a development mode.
```json
{
"mcpServers": {
"claude-context-local": {
"command": "node",
"args": ["PATH_TO_CLAUDECONTEXT/packages/mcp/dist/index.js"],
"env": {
"OPENAI_API_KEY": "sk-your-openai-api-key",
"MILVUS_TOKEN": "your-zilliz-cloud-api-key"
}
}
}
}
```
### Claude Code Development Mode Configuration
```bash
claude mcp add claude-context -e OPENAI_API_KEY=sk-your-openai-api-key -e MILVUS_TOKEN=your-zilliz-cloud-api-key -- node PATH_TO_CLAUDECONTEXT/packages/mcp/dist/index.js
```
And then you can start Claude Code with `claude --debug` to see the MCP server logs.
### Manual Usage
Use all three MCP tools:
- `index_codebase` - Index sample repositories with optional custom ignore patterns
Example with ignore patterns: `{"path": "/repo/path", "ignorePatterns": ["static/**", "*.tmp"]}`
- `search_code` - Search with various queries
- `clear_index` - Clear and re-index
## Questions?
- **General questions**: See [main contributing guide](../../CONTRIBUTING.md)
- **MCP-specific issues**: Open an issue with the `mcp` label
```
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
```markdown
# Contributing to Claude Context
Thank you for your interest in contributing to Claude Context! This guide will help you get started.
## 🚀 Getting Started
### Prerequisites
- Node.js >= 20.0.0 and < 24.0.0
- pnpm >= 10.0.0
- Git
### Development Setup
1. **Fork and Clone**
```bash
git clone https://github.com/your-username/claude-context.git
cd claude-context
```
2. **Platform-Specific Setup**
**Windows Users:**
```powershell
# Configure git line endings (recommended)
git config core.autocrlf false
# Ensure pnpm is installed
npm install -g pnpm
```
**Linux/macOS Users:**
```bash
# Standard setup - no additional configuration needed
```
3. **Install Dependencies**
```bash
pnpm install
```
4. **Build All Packages**
```bash
pnpm build
```
5. **Start Development Mode**
```bash
pnpm dev
```
## 📁 Project Structure
```
claude-context/
├── packages/
│ ├── core/ # Core indexing engine
│ ├── vscode-extension/ # VSCode extension
│ └── mcp/ # Model Context Protocol server
├── examples/
│ └── basic-usage/ # Basic usage example
```
### Package-Specific Development
Each package has its own development guide with specific instructions:
- **[Core Package](packages/core/CONTRIBUTING.md)** - Develop the core indexing engine
- **[VSCode Extension](packages/vscode-extension/CONTRIBUTING.md)** - Develop the VSCode extension
- **[MCP Server](packages/mcp/CONTRIBUTING.md)** - Develop the MCP protocol server
## 🛠️ Development Workflow
### Building All Packages
```bash
# Build all packages
pnpm build
# Clean and rebuild
pnpm clean && pnpm build
# Development mode (watch all packages)
pnpm dev
```
### Package-Specific Development
For detailed development instructions for each package, see:
- [Core Package Development](packages/core/CONTRIBUTING.md)
- [VSCode Extension Development](packages/vscode-extension/CONTRIBUTING.md)
- [MCP Server Development](packages/mcp/CONTRIBUTING.md)
## 📝 Making Changes
### Commit Guidelines
We follow conventional commit format:
```
type(scope): description
feat(core): add new embedding provider
fix(vscode): resolve search result display issue
docs(readme): update installation instructions
refactor(mcp): improve error handling
```
**Types**: `feat`, `fix`, `docs`, `refactor`, `perf`, `chore`
**Scopes**: `core`, `vscode`, `mcp`, `examples`, `docs`
### Pull Request Process
1. **Create Feature Branch**
```bash
git checkout -b feature/your-feature-name
```
2. **Make Your Changes**
- Keep changes focused and atomic
- Update documentation if needed
3. **Build and Verify**
```bash
pnpm build
```
4. **Commit Your Changes**
```bash
git add .
git commit -m "feat(core): add your feature description"
```
5. **Push and Create PR**
```bash
git push origin feature/your-feature-name
```
## 🎯 Contribution Areas
### Priority Areas
- **Core Engine**: Improve indexing performance and accuracy
- **Embedding Providers**: Add support for more embedding services
- **Vector Databases**: Extend database integration options
- **Documentation**: Improve examples and guides
- **Bug Fixes**: Fix reported issues
### Ideas for Contribution
- Add support for new programming languages
- Improve code chunking strategies
- Enhance search result ranking
- Add configuration options
- Create more usage examples
## 📋 Reporting Issues
When reporting bugs or requesting features:
1. **Check Existing Issues**: Search for similar issues first
2. **Use Templates**: Follow the issue templates when available
3. **Provide Context**: Include relevant details about your environment
4. **Steps to Reproduce**: Clear steps for reproducing bugs
## 💬 Getting Help
- **GitHub Issues**: For bugs and feature requests
- **GitHub Discussions**: For questions and general discussion
## 📄 License
By contributing to Claude Context, you agree that your contributions will be licensed under the MIT License.
---
Thank you for contributing to Claude Context! 🎉
```
--------------------------------------------------------------------------------
/packages/chrome-extension/CONTRIBUTING.md:
--------------------------------------------------------------------------------
```markdown
# Contributing to Chrome Extension
Thanks for your interest in contributing to the Claude Context Chrome extension!
> 📖 **First time contributing?** Please read the [main contributing guide](../../CONTRIBUTING.md) first for general setup and workflow.
## Chrome Extension Development
This guide covers development specific to the Chrome extension.
### Quick Commands
```bash
# Build Chrome extension
pnpm build:chrome
# Watch mode for development
pnpm dev:chrome
# Clean build artifacts
pnpm clean
# Lint code
pnpm lint
# Type checking
pnpm typecheck
# Generate icons
pnpm prebuild
```
### Development Setup
1. **Install Dependencies**:
```bash
cd packages/chrome-extension
pnpm install
```
2. **Build Extension**:
```bash
pnpm build
```
3. **Load in Chrome**:
- Open Chrome and go to `chrome://extensions/`
- Enable "Developer mode"
- Click "Load unpacked" and select the `dist` folder
4. **Development Mode**:
```bash
pnpm dev # Watch mode for automatic rebuilds
```
## Making Changes
1. Create a new branch for your feature/fix
2. Make changes in the `src/` directory
3. Test in Chrome with "Reload extension" after changes
4. Follow commit guidelines in the [main guide](../../CONTRIBUTING.md)
## Project Structure
```
src/
├── content.ts # Content script for GitHub integration
├── background.ts # Background service worker
├── options.ts # Options/settings page
├── options.html # Options page HTML
├── styles.css # Extension styles
├── manifest.json # Extension manifest
├── config/
│ └── milvusConfig.ts # Milvus configuration
├── milvus/
│ └── chromeMilvusAdapter.ts # Browser Milvus adapter
├── storage/
│ └── indexedRepoManager.ts # Repository management
├── stubs/ # Browser compatibility stubs
└── icons/ # Extension icons
```
## Development Workflow
### 1. Content Script Development
- Modify `src/content.ts` for GitHub UI integration
- Test on various GitHub repository pages
- Ensure UI doesn't conflict with GitHub's interface
### 2. Background Service Worker
- Edit `src/background.ts` for extension lifecycle management
- Handle cross-tab communication and data persistence
- Test extension startup and shutdown scenarios
### 3. Options Page
- Update `src/options.ts` and `src/options.html` for settings
- Test configuration persistence and validation
- Ensure user-friendly error messages
### 4. Testing Workflow
1. Make changes to source files
2. Run `pnpm build` or use `pnpm dev` for watch mode
3. Go to `chrome://extensions/` and click "Reload" on the extension
4. Test functionality on GitHub repositories
5. Check Chrome DevTools console for errors
## Browser Compatibility
### WebPack Configuration
- `webpack.config.js` handles Node.js polyfills for browser environment
- Modules like `crypto`, `fs`, `path` are replaced with browser-compatible versions
### Key Polyfills
- `crypto-browserify` - Cryptographic functions
- `buffer` - Node.js Buffer API
- `process` - Process environment variables
- `path-browserify` - Path manipulation
- `vm-browserify` - Virtual machine context
### Testing Browser Compatibility
```bash
# Build and test in different browsers
pnpm build
# Load extension in Chrome, Edge, Brave, etc.
```
## Extension-Specific Guidelines
### Manifest V3 Compliance
- Use service workers instead of background pages
- Follow content security policy restrictions
- Handle permissions properly
### Performance Considerations
- Minimize content script impact on GitHub page load
- Use efficient DOM manipulation
- Lazy load heavy components
### Security Best Practices
- Validate all user inputs
- Sanitize HTML content
- Use secure communication between scripts
- Handle API keys securely
### UI/UX Guidelines
- Match GitHub's design language
- Provide loading states for async operations
- Show clear error messages
- Ensure accessibility compliance
## Chrome Extension Features
### Core Functionality
- **Repository Indexing**: Parse GitHub repositories and create vector embeddings
- **Semantic Search**: Natural language code search within repositories
- **UI Integration**: Seamless GitHub interface enhancement
- **Configuration Management**: User settings and API key management
### Advanced Features
- **Cross-Repository Search**: Search across multiple indexed repositories
- **Context-Aware Search**: Search similar code from selected snippets
- **Progress Tracking**: Real-time indexing progress indicators
- **Offline Support**: Local caching of indexed repositories
## Testing Checklist
### Manual Testing
- [ ] Extension loads without errors
- [ ] UI appears correctly on GitHub repository pages
- [ ] Indexing works for public repositories
- [ ] Search returns relevant results
- [ ] Options page saves configuration correctly
- [ ] Extension works across different GitHub page types
- [ ] No conflicts with GitHub's native functionality
### Cross-Browser Testing
- [ ] Chrome (latest)
- [ ] Edge (Chromium-based)
- [ ] Brave Browser
- [ ] Other Chromium-based browsers
### GitHub Integration Testing
- [ ] Repository home pages
- [ ] File browser pages
- [ ] Code view pages
- [ ] Pull request pages
- [ ] Different repository sizes
- [ ] Private repositories (with token)
## Debugging
### Chrome DevTools
1. Right-click extension icon → "Inspect popup"
2. Go to GitHub page → F12 → check console for content script errors
3. `chrome://extensions/` → click "service worker" link for background script debugging
### Common Issues
- **Permission errors**: Check manifest.json permissions
- **CSP violations**: Verify content security policy compliance
- **Module not found**: Check webpack polyfill configuration
- **API errors**: Validate API keys and network connectivity
### Debug Commands
```bash
# Check build output (Unix/macOS)
ls -la dist/
# Check build output (Windows PowerShell)
Get-ChildItem dist/ | Format-Table -AutoSize
# Validate manifest (Unix/macOS)
cat dist/manifest.json | jq
# Validate manifest (Windows PowerShell)
Get-Content dist/manifest.json | ConvertFrom-Json | ConvertTo-Json -Depth 10
# Check for TypeScript errors (cross-platform)
pnpm typecheck
```
## Publishing Preparation
### Pre-Publishing Checklist
- [ ] All tests pass
- [ ] No console errors
- [ ] Icons generated correctly
- [ ] Manifest version updated
- [ ] README updated with new features
- [ ] Screenshots prepared for store listing
### Build for Production
```bash
# Clean build
pnpm clean
pnpm build
# Verify bundle size (Unix/macOS)
ls -lh dist/
# Verify bundle size (Windows PowerShell)
Get-ChildItem dist/ | Select-Object Name, @{Name="Size";Expression={[math]::Round($_.Length/1KB,2)}} | Format-Table -AutoSize
```
> **Note**: Only maintainers can publish to Chrome Web Store
## Questions?
- **General questions**: See [main contributing guide](../../CONTRIBUTING.md)
- **Chrome extension specific issues**: Open an issue with the `chrome-extension` label
- **Browser compatibility**: Test across different Chromium browsers
- **GitHub integration**: Ensure changes work across all GitHub page types
```
--------------------------------------------------------------------------------
/evaluation/retrieval/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/evaluation/servers/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/evaluation/utils/__init__.py:
--------------------------------------------------------------------------------
```python
```
--------------------------------------------------------------------------------
/packages/core/src/utils/index.ts:
--------------------------------------------------------------------------------
```typescript
export { EnvManager, envManager } from './env-manager';
```
--------------------------------------------------------------------------------
/pnpm-workspace.yaml:
--------------------------------------------------------------------------------
```yaml
packages:
- packages/*
- examples/*
ignoredBuiltDependencies:
- faiss-node
```
--------------------------------------------------------------------------------
/packages/chrome-extension/src/vm-stub.js:
--------------------------------------------------------------------------------
```javascript
// This file is intentionally left blank to act as a stub for the 'vm' module in the browser environment.
```
--------------------------------------------------------------------------------
/evaluation/utils/constant.py:
--------------------------------------------------------------------------------
```python
from pathlib import Path
evaluation_path = Path(__file__).parent.parent.absolute() # evaluation/
project_path = evaluation_path.parent.absolute() # claude-context/
```
--------------------------------------------------------------------------------
/packages/core/src/index.ts:
--------------------------------------------------------------------------------
```typescript
export * from './splitter';
export * from './embedding';
export * from './vectordb';
export * from './types';
export * from './context';
export * from './sync/synchronizer';
export * from './utils';
```
--------------------------------------------------------------------------------
/packages/core/src/embedding/index.ts:
--------------------------------------------------------------------------------
```typescript
// Export base classes and interfaces
export * from './base-embedding';
// Implementation class exports
export * from './openai-embedding';
export * from './voyageai-embedding';
export * from './ollama-embedding';
export * from './gemini-embedding';
```
--------------------------------------------------------------------------------
/.vscode/extensions.json:
--------------------------------------------------------------------------------
```json
{
// See http://go.microsoft.com/fwlink/?LinkId=827846
// for the documentation about the extensions.json format
"recommendations": [
"dbaeumer.vscode-eslint",
"ms-vscode.extension-test-runner",
"ms-vscode.vscode-typescript-next",
"ms-vscode.vscode-json"
]
}
```
--------------------------------------------------------------------------------
/packages/chrome-extension/tsconfig.json:
--------------------------------------------------------------------------------
```json
{
"extends": "../../tsconfig.json",
"compilerOptions": {
"lib": ["ES2021", "DOM", "DOM.Iterable"],
"types": ["chrome"],
"noImplicitAny": false,
"outDir": "dist"
},
"include": [
"src/**/*.ts"
],
"exclude": [
"node_modules",
"dist"
]
}
```
--------------------------------------------------------------------------------
/packages/core/src/types.ts:
--------------------------------------------------------------------------------
```typescript
export interface SearchQuery {
term: string;
includeContent?: boolean;
limit?: number;
}
export interface SemanticSearchResult {
content: string;
relativePath: string;
startLine: number;
endLine: number;
language: string;
score: number;
}
```
--------------------------------------------------------------------------------
/packages/vscode-extension/src/stubs/milvus-vectordb-stub.js:
--------------------------------------------------------------------------------
```javascript
// Stub implementation for MilvusVectorDatabase to avoid gRPC dependencies in VSCode extension
// This file replaces the actual milvus-vectordb.ts when bundling for VSCode
class MilvusVectorDatabase {
constructor(config) {
throw new Error('MilvusVectorDatabase (gRPC) is not available in VSCode extension. Use MilvusRestfulVectorDatabase instead.');
}
}
module.exports = {
MilvusVectorDatabase
};
```
--------------------------------------------------------------------------------
/packages/vscode-extension/tsconfig.json:
--------------------------------------------------------------------------------
```json
{
"extends": "../../tsconfig.json",
"compilerOptions": {
"module": "commonjs",
"outDir": "./dist",
"rootDir": "./src",
"composite": true,
"lib": [
"ES2020"
],
"skipLibCheck": true,
"moduleResolution": "node"
},
"include": [
"src/**/*"
],
"exclude": [
"dist",
"node_modules"
],
"references": [
{
"path": "../core"
}
]
}
```
--------------------------------------------------------------------------------
/evaluation/case_study/django_14170/both_result.json:
--------------------------------------------------------------------------------
```json
{
"instance_id": "django__django-14170",
"hits": [
"django/db/models/lookups.py"
],
"oracles": [
"django/db/models/lookups.py",
"django/db/backends/base/operations.py"
],
"token_usage": {
"input_tokens": 8582,
"output_tokens": 454,
"total_tokens": 9036,
"max_single_turn_tokens": 3829
},
"tool_stats": {
"tool_call_counts": {
"search_code": 1,
"edit": 2
},
"total_tool_calls": 3
},
"retrieval_types": [
"cc",
"grep"
]
}
```
--------------------------------------------------------------------------------
/evaluation/case_study/pydata_xarray_6938/both_result.json:
--------------------------------------------------------------------------------
```json
{
"instance_id": "pydata__xarray-6938",
"hits": [
"xarray/core/dataset.py",
"xarray/core/dataarray.py"
],
"oracles": [
"xarray/core/variable.py",
"xarray/core/dataset.py"
],
"token_usage": {
"input_tokens": 15428,
"output_tokens": 398,
"total_tokens": 15826,
"max_single_turn_tokens": 6971
},
"tool_stats": {
"tool_call_counts": {
"search_code": 1,
"edit": 2
},
"total_tool_calls": 3
},
"retrieval_types": [
"cc",
"grep"
]
}
```
--------------------------------------------------------------------------------
/evaluation/pyproject.toml:
--------------------------------------------------------------------------------
```toml
[project]
name = "evaluation"
version = "0.1.0"
description = ""
readme = "README.md"
requires-python = ">=3.10"
dependencies = [
"langchain-mcp-adapters>=0.1.9",
"langgraph>=0.6.4",
"mcp>=1.12.4",
"langchain>=0.1.0",
"langchain-core>=0.1.0",
"langchain-anthropic>=0.1.0",
"langchain-openai>=0.3.29",
"langchain-ollama>=0.3.6",
"datasets>=4.0.0",
"gitpython>=3.1.45",
"matplotlib>=3.10.5",
"seaborn>=0.13.2",
"pandas>=2.3.1",
"numpy>=2.2.6",
"plotly>=6.3.0",
"kaleido>=1.0.0",
]
```
--------------------------------------------------------------------------------
/evaluation/case_study/pydata_xarray_6938/grep_result.json:
--------------------------------------------------------------------------------
```json
{
"instance_id": "pydata__xarray-6938",
"hits": [
"xarray/core/dataarray.py",
"xarray/core/dataset.py",
"/data2/zha...ims",
"xarray/core/common.py"
],
"oracles": [
"xarray/core/variable.py",
"xarray/core/dataset.py"
],
"token_usage": {
"input_tokens": 40898,
"output_tokens": 1101,
"total_tokens": 41999,
"max_single_turn_tokens": 8156
},
"tool_stats": {
"tool_call_counts": {
"list_directory": 3,
"search_text": 1,
"read_file": 3,
"edit": 4
},
"total_tool_calls": 11
}
}
```
--------------------------------------------------------------------------------
/evaluation/case_study/django_14170/grep_result.json:
--------------------------------------------------------------------------------
```json
{
"instance_id": "django__django-14170",
"hits": [
"django/db/models/functions/datetime.py",
"tests/db_functions/datetime/test_extract_trunc.py"
],
"oracles": [
"django/db/backends/base/operations.py",
"django/db/models/lookups.py"
],
"token_usage": {
"input_tokens": 130064,
"output_tokens": 755,
"total_tokens": 130819,
"max_single_turn_tokens": 26750
},
"tool_stats": {
"tool_call_counts": {
"directory_tree": 1,
"search_text": 1,
"edit": 6
},
"total_tool_calls": 8
},
"retrieval_types": [
"grep"
]
}
```
--------------------------------------------------------------------------------
/examples/basic-usage/package.json:
--------------------------------------------------------------------------------
```json
{
"name": "claude-context-basic-example",
"version": "0.1.3",
"description": "Basic usage example for Claude Context",
"main": "index.ts",
"scripts": {
"start": "tsx index.ts",
"build": "tsc index.ts --outDir dist --target es2020 --module commonjs --moduleResolution node --esModuleInterop true",
"dev": "tsx --watch index.ts"
},
"dependencies": {
"@zilliz/claude-context-core": "workspace:*"
},
"devDependencies": {
"tsx": "^4.0.0",
"typescript": "^5.0.0",
"@types/node": "^20.0.0",
"dotenv": "^16.0.0"
},
"private": true
}
```
--------------------------------------------------------------------------------
/packages/mcp/tsconfig.json:
--------------------------------------------------------------------------------
```json
{
"compilerOptions": {
"target": "ES2020",
"module": "ES2020",
"lib": [
"ES2020"
],
"declaration": true,
"declarationMap": true,
"sourceMap": true,
"outDir": "./dist",
"rootDir": "./src",
"strict": true,
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"moduleResolution": "node",
"composite": true
},
"include": [
"src/**/*"
],
"exclude": [
"dist",
"node_modules"
],
"references": [
{
"path": "../core"
}
]
}
```
--------------------------------------------------------------------------------
/.vscode/settings.json:
--------------------------------------------------------------------------------
```json
// Place your settings in this file to overwrite default and user settings.
{
"files.exclude": {
"**/node_modules": true,
"**/dist": false,
"**/out": false
},
"search.exclude": {
"**/node_modules": true,
"**/dist": true,
"**/out": true
},
// Turn off tsc task auto detection since we have the necessary tasks as npm scripts
"typescript.tsc.autoDetect": "off",
"typescript.preferences.includePackageJsonAutoImports": "on",
// ESLint settings
"eslint.workingDirectories": [
"packages/vscode-extension",
"packages/core"
],
// Format on save
"editor.formatOnSave": true,
"editor.codeActionsOnSave": {
"source.fixAll.eslint": "explicit"
}
}
```
--------------------------------------------------------------------------------
/packages/core/src/vectordb/index.ts:
--------------------------------------------------------------------------------
```typescript
// Re-export types and interfaces
export {
VectorDocument,
SearchOptions,
VectorSearchResult,
VectorDatabase,
HybridSearchRequest,
HybridSearchOptions,
HybridSearchResult,
RerankStrategy,
COLLECTION_LIMIT_MESSAGE
} from './types';
// Implementation class exports
export { MilvusRestfulVectorDatabase, MilvusRestfulConfig } from './milvus-restful-vectordb';
export { MilvusVectorDatabase, MilvusConfig } from './milvus-vectordb';
export {
ClusterManager,
ZillizConfig,
Project,
Cluster,
CreateFreeClusterRequest,
CreateFreeClusterResponse,
CreateFreeClusterWithDetailsResponse,
DescribeClusterResponse
} from './zilliz-utils';
```
--------------------------------------------------------------------------------
/.vscode/tasks.json:
--------------------------------------------------------------------------------
```json
// See https://go.microsoft.com/fwlink/?LinkId=733558
// for the documentation about the tasks.json format
{
"version": "2.0.0",
"tasks": [
{
"type": "npm",
"script": "webpack:dev",
"path": "packages/vscode-extension/",
"problemMatcher": "$tsc-watch",
"isBackground": true,
"presentation": {
"reveal": "never"
},
"group": {
"kind": "build",
"isDefault": true
}
},
{
"type": "npm",
"script": "webpack",
"path": "packages/vscode-extension/",
"group": "build",
"presentation": {
"echo": true,
"reveal": "silent",
"focus": false,
"panel": "shared",
"showReuseMessage": true,
"clear": false
},
"problemMatcher": "$tsc"
}
]
}
```
--------------------------------------------------------------------------------
/evaluation/utils/llm_factory.py:
--------------------------------------------------------------------------------
```python
from langchain_openai import ChatOpenAI
from langchain_ollama import ChatOllama
from langchain_anthropic import ChatAnthropic
import os
def llm_factory(llm_type: str, llm_model: str):
if llm_type == "openai":
return ChatOpenAI(model=llm_model)
elif llm_type == "ollama":
return ChatOllama(model=llm_model)
elif llm_type == "moonshot":
return ChatOpenAI(
model=llm_model,
base_url="https://api.moonshot.cn/v1",
api_key=os.getenv("MOONSHOT_API_KEY"),
)
elif llm_type == "anthropic":
return ChatAnthropic(model=llm_model, api_key=os.getenv("ANTHROPIC_API_KEY"))
else:
raise ValueError(f"Unsupported LLM type: {llm_type}")
```
--------------------------------------------------------------------------------
/packages/core/tsconfig.json:
--------------------------------------------------------------------------------
```json
{
"compilerOptions": {
"target": "ES2020",
"module": "commonjs",
"lib": [
"ES2020"
],
"declaration": true,
"declarationMap": true,
"sourceMap": true,
"outDir": "./dist",
"rootDir": "./src",
"strict": true,
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"moduleResolution": "node",
"composite": true,
"allowSyntheticDefaultImports": true,
"downlevelIteration": true,
"incremental": true,
"tsBuildInfoFile": "./dist/.tsbuildinfo"
},
"include": [
"src/**/*"
],
"exclude": [
"dist",
"node_modules"
]
}
```
--------------------------------------------------------------------------------
/packages/mcp/src/utils.ts:
--------------------------------------------------------------------------------
```typescript
import * as path from "path";
/**
* Truncate content to specified length
*/
export function truncateContent(content: string, maxLength: number): string {
if (content.length <= maxLength) {
return content;
}
return content.substring(0, maxLength) + '...';
}
/**
* Ensure path is absolute. If relative path is provided, resolve it properly.
*/
export function ensureAbsolutePath(inputPath: string): string {
// If already absolute, return as is
if (path.isAbsolute(inputPath)) {
return inputPath;
}
// For relative paths, resolve to absolute path
const resolved = path.resolve(inputPath);
return resolved;
}
export function trackCodebasePath(codebasePath: string): void {
const absolutePath = ensureAbsolutePath(codebasePath);
console.log(`[TRACKING] Tracked codebase path: ${absolutePath} (not marked as indexed)`);
}
```
--------------------------------------------------------------------------------
/build-benchmark.json:
--------------------------------------------------------------------------------
```json
[
{
"timestamp": "2025-08-25T19:04:13.664Z",
"platform": "win32",
"nodeVersion": "v22.15.1",
"results": [
{
"success": true,
"duration": 1849,
"command": "pnpm clean",
"description": "Clean all packages"
},
{
"success": true,
"duration": 6754,
"command": "pnpm build:core",
"description": "Build core package"
},
{
"success": true,
"duration": 9782,
"command": "pnpm build:mcp",
"description": "Build MCP package"
},
{
"success": true,
"duration": 6821,
"command": "pnpm build:vscode",
"description": "Build VSCode extension"
},
{
"success": true,
"duration": 14526,
"command": "pnpm -r --filter=\"./packages/chrome-extension\" build",
"description": "Build Chrome extension"
}
]
}
]
```
--------------------------------------------------------------------------------
/.github/workflows/release.yml:
--------------------------------------------------------------------------------
```yaml
name: Release
on:
push:
tags:
- 'v*'
- 'c*'
jobs:
release:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Install pnpm
uses: pnpm/action-setup@v4
with:
version: 10
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: '20.x'
cache: 'pnpm'
- name: Install dependencies
run: pnpm install --frozen-lockfile
- name: Setup npm auth
run: |
echo "//registry.npmjs.org/:_authToken=${{ secrets.NPM_TOKEN }}" > .npmrc
- name: Build packages
run: pnpm build
- name: Publish core package to npm
run: pnpm --filter @zilliz/claude-context-core publish --access public --no-git-checks
- name: Publish mcp package to npm
run: pnpm --filter @zilliz/claude-context-mcp publish --access public --no-git-checks
- name: Publish vscode extension
run: pnpm release:vscode
env:
VSCE_PAT: ${{ secrets.VSCE_PAT }}
```
--------------------------------------------------------------------------------
/.vscode/launch.json:
--------------------------------------------------------------------------------
```json
// A launch configuration that compiles the extension and then opens it inside a new window
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
{
"version": "0.2.0",
"configurations": [
{
"name": "Run Extension",
"type": "extensionHost",
"request": "launch",
"args": [
"--extensionDevelopmentPath=${workspaceFolder}/packages/vscode-extension"
],
"outFiles": [
"${workspaceFolder}/packages/vscode-extension/dist/**/*.js"
],
"preLaunchTask": "npm: webpack:dev - packages/vscode-extension"
},
{
"name": "Extension Tests",
"type": "extensionHost",
"request": "launch",
"args": [
"--extensionDevelopmentPath=${workspaceFolder}/packages/vscode-extension",
"--extensionTestsPath=${workspaceFolder}/packages/vscode-extension/dist/test/suite/index"
],
"outFiles": [
"${workspaceFolder}/packages/vscode-extension/dist/test/**/*.js"
],
"preLaunchTask": "npm: webpack:dev - packages/vscode-extension"
}
]
}
```
--------------------------------------------------------------------------------
/packages/core/src/splitter/index.ts:
--------------------------------------------------------------------------------
```typescript
// Interface definitions
export interface CodeChunk {
content: string;
metadata: {
startLine: number;
endLine: number;
language?: string;
filePath?: string;
};
}
// Splitter type enumeration
export enum SplitterType {
LANGCHAIN = 'langchain',
AST = 'ast'
}
// Splitter configuration interface
export interface SplitterConfig {
type?: SplitterType;
chunkSize?: number;
chunkOverlap?: number;
}
export interface Splitter {
/**
* Split code into code chunks
* @param code Code content
* @param language Programming language
* @param filePath File path
* @returns Array of code chunks
*/
split(code: string, language: string, filePath?: string): Promise<CodeChunk[]>;
/**
* Set chunk size
* @param chunkSize Chunk size
*/
setChunkSize(chunkSize: number): void;
/**
* Set chunk overlap size
* @param chunkOverlap Chunk overlap size
*/
setChunkOverlap(chunkOverlap: number): void;
}
// Implementation class exports
export * from './langchain-splitter';
export * from './ast-splitter';
```
--------------------------------------------------------------------------------
/tsconfig.json:
--------------------------------------------------------------------------------
```json
{
"compilerOptions": {
"target": "ES2020",
"module": "commonjs",
"lib": [
"ES2020"
],
"declaration": true,
"declarationMap": true,
"sourceMap": true,
"strict": true,
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"moduleResolution": "node",
"composite": true,
"resolveJsonModule": true,
"allowSyntheticDefaultImports": true,
"baseUrl": ".",
"downlevelIteration": true,
"incremental": true,
"tsBuildInfoFile": ".tsbuildinfo",
"paths": {
"@zilliz/claude-context-core": [
"./packages/core/src"
],
"@zilliz/claude-context-core/*": [
"./packages/core/src/*"
]
}
},
"references": [
{
"path": "./packages/core"
},
{
"path": "./packages/vscode-extension"
},
{
"path": "./packages/chrome-extension"
},
{
"path": "./packages/mcp"
}
],
"files": []
}
```
--------------------------------------------------------------------------------
/packages/chrome-extension/src/manifest.json:
--------------------------------------------------------------------------------
```json
{
"manifest_version": 3,
"name": "GitHub Code Vector Search",
"version": "1.0",
"description": "Index GitHub repository code and perform vector search.",
"content_security_policy": {
"extension_pages": "script-src 'self' 'wasm-unsafe-eval'"
},
"action": {
"default_icon": {
"16": "icons/icon16.png",
"32": "icons/icon32.png",
"48": "icons/icon48.png",
"128": "icons/icon128.png"
}
},
"permissions": [
"storage",
"scripting",
"unlimitedStorage"
],
"host_permissions": [
"https://github.com/*",
"https://api.openai.com/*",
"http://*/*",
"https://*/*"
],
"background": {
"service_worker": "background.js"
},
"content_scripts": [
{
"matches": [
"https://github.com/*/*"
],
"js": [
"content.js"
],
"css": [
"styles.css"
]
}
],
"options_ui": {
"page": "options.html",
"open_in_tab": true
},
"web_accessible_resources": [
{
"resources": [
"ort-wasm-simd-threaded.wasm",
"options.html",
"options.js"
],
"matches": [
"<all_urls>"
]
}
]
}
```
--------------------------------------------------------------------------------
/evaluation/servers/edit_server.py:
--------------------------------------------------------------------------------
```python
#!/usr/bin/env python3
"""
An edit server using MCP (Model Context Protocol).
This server provides file editing functionality for modifying files.
"""
import os
from mcp.server.fastmcp import FastMCP
# Create the MCP server
mcp = FastMCP("Edit Server")
@mcp.tool()
def edit(file_path: str, old_string: str, new_string: str) -> str:
"""Edits the specified file with the given modifications.
This tool marks files that need to be edited with the specified changes.
Args:
file_path: The absolute path to the file to modify.
old_string: The exact literal text to replace. Must uniquely identify the single
instance to change. Should include at least 3 lines of context before
and after the target text, matching whitespace and indentation precisely.
If old_string is empty, the tool attempts to create a new file at
file_path with new_string as content.
new_string: The exact literal text to replace old_string with.
Returns:
A string indicating the file has been successfully modified.
"""
# Mock the edit operation
return f"Successfully modified file: {file_path}"
if __name__ == "__main__":
# Run the server with stdio transport
mcp.run(transport="stdio")
```
--------------------------------------------------------------------------------
/packages/mcp/package.json:
--------------------------------------------------------------------------------
```json
{
"name": "@zilliz/claude-context-mcp",
"version": "0.1.3",
"description": "Model Context Protocol integration for Claude Context",
"type": "module",
"main": "dist/index.js",
"types": "dist/index.d.ts",
"bin": "dist/index.js",
"scripts": {
"build": "pnpm clean && tsc --build --force",
"dev": "tsx --watch src/index.ts",
"clean": "rimraf dist",
"lint": "eslint src --ext .ts",
"lint:fix": "eslint src --ext .ts --fix",
"typecheck": "tsc --noEmit",
"start": "tsx src/index.ts",
"start:with-env": "OPENAI_API_KEY=${OPENAI_API_KEY:your-api-key-here} MILVUS_ADDRESS=${MILVUS_ADDRESS:localhost:19530} tsx src/index.ts",
"prepublishOnly": "pnpm build"
},
"dependencies": {
"@zilliz/claude-context-core": "workspace:*",
"@modelcontextprotocol/sdk": "^1.12.1",
"zod": "^3.25.55"
},
"devDependencies": {
"@types/node": "^20.0.0",
"tsx": "^4.19.4",
"typescript": "^5.0.0"
},
"files": [
"dist",
"README.md"
],
"repository": {
"type": "git",
"url": "https://github.com/zilliztech/claude-context.git",
"directory": "packages/mcp"
},
"license": "MIT",
"publishConfig": {
"access": "public"
}
}
```
--------------------------------------------------------------------------------
/packages/core/package.json:
--------------------------------------------------------------------------------
```json
{
"name": "@zilliz/claude-context-core",
"version": "0.1.3",
"description": "Core indexing engine for Claude Context",
"main": "dist/index.js",
"types": "dist/index.d.ts",
"scripts": {
"build": "pnpm clean && tsc --build --force",
"dev": "tsc --watch",
"clean": "rimraf dist",
"lint": "eslint src --ext .ts",
"lint:fix": "eslint src --ext .ts --fix",
"typecheck": "tsc --noEmit"
},
"dependencies": {
"@google/genai": "^1.9.0",
"@zilliz/milvus2-sdk-node": "^2.5.10",
"faiss-node": "^0.5.1",
"fs-extra": "^11.0.0",
"glob": "^10.0.0",
"langchain": "^0.3.27",
"ollama": "^0.5.16",
"openai": "^5.1.1",
"tree-sitter": "^0.21.1",
"tree-sitter-cpp": "^0.22.0",
"tree-sitter-go": "^0.21.0",
"tree-sitter-java": "^0.21.0",
"tree-sitter-javascript": "^0.21.0",
"tree-sitter-python": "^0.21.0",
"tree-sitter-c-sharp": "^0.21.0",
"tree-sitter-rust": "^0.21.0",
"tree-sitter-typescript": "^0.21.0",
"tree-sitter-scala": "^0.24.0",
"typescript": "^5.0.0",
"voyageai": "^0.0.4"
},
"devDependencies": {
"@types/fs-extra": "^11.0.0",
"@types/jest": "^30.0.0",
"@types/mock-fs": "^4.13.4",
"jest": "^30.0.0",
"mock-fs": "^5.5.0",
"ts-jest": "^29.4.0"
},
"files": [
"dist",
"README.md"
],
"repository": {
"type": "git",
"url": "https://github.com/zilliztech/claude-context.git",
"directory": "packages/core"
},
"license": "MIT",
"publishConfig": {
"access": "public"
}
}
```
--------------------------------------------------------------------------------
/.github/workflows/ci.yml:
--------------------------------------------------------------------------------
```yaml
name: CI
on:
push:
branches: [master, main, claude_context]
pull_request:
branches: [master, main, claude_context]
jobs:
lint_and_build:
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest, windows-latest]
node-version: [20.x, 22.x]
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Install pnpm
uses: pnpm/action-setup@v4
with:
version: 10
- name: Setup Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v4
with:
node-version: ${{ matrix.node-version }}
cache: "pnpm"
- name: Configure Windows line endings
if: matrix.os == 'windows-latest'
run: git config --global core.autocrlf false
- name: Install dependencies
run: pnpm install --frozen-lockfile
# - name: Lint code
# run: pnpm lint
- name: Build packages
run: pnpm build
- name: Test clean command (Windows validation)
if: matrix.os == 'windows-latest'
run: |
pnpm clean
echo "Clean command executed successfully on Windows"
- name: Verify build outputs (Unix)
if: matrix.os != 'windows-latest'
run: |
ls -la packages/core/dist || echo "packages/core/dist not found"
ls -la packages/mcp/dist || echo "packages/mcp/dist not found"
- name: Verify build outputs (Windows)
if: matrix.os == 'windows-latest'
run: |
Get-ChildItem packages/core/dist -ErrorAction SilentlyContinue | Format-Table -AutoSize || Write-Host "packages/core/dist not found"
Get-ChildItem packages/mcp/dist -ErrorAction SilentlyContinue | Format-Table -AutoSize || Write-Host "packages/mcp/dist not found"
```
--------------------------------------------------------------------------------
/docs/dive-deep/asynchronous-indexing-workflow.md:
--------------------------------------------------------------------------------
```markdown
# Asynchronous Indexing Workflow
This document explains how Claude Context MCP handles codebase indexing asynchronously in the background.
## Core Concept
Claude Context MCP server allows users to start indexing and get an immediate response, while the actual indexing happens in the background. Users can search and monitor progress at any time.
## How It Works

The sequence diagram above demonstrates the timing and interaction between the agent, MCP server, and background process.
The agent receives an immediate response when starting indexing, then the users can perform searches and status checks through the agent while indexing continues in the background.
## State Flow

The flow diagram above shows the complete indexing workflow, illustrating how the system handles different states and user interactions. The key insight is that indexing starts immediately but runs in the background, allowing users to interact with the system at any time.
## MCP Tools
- **`index_codebase`** - Starts background indexing, returns immediately
- **`search_code`** - Searches codebase (works during indexing with partial results)
- **`get_indexing_status`** - Shows current progress and status
- **`clear_index`** - Removes indexed data
## Status States
- **`indexed`** - ✅ Ready for search
- **`indexing`** - 🔄 Background process running
- **`indexfailed`** - ❌ Error occurred, can retry
- **`not_found`** - ❌ Not indexed yet
## Key Benefits
- **Non-blocking**: Agent gets immediate response
- **Progressive**: Can search partial results while indexing
- **Resilient**: Handles errors gracefully with retry capability
- **Transparent**: Always know current status
```
--------------------------------------------------------------------------------
/packages/chrome-extension/package.json:
--------------------------------------------------------------------------------
```json
{
"name": "@zilliz/claude-context-chrome-extension",
"version": "0.1.3",
"description": "Claude Context Chrome extension for web-based code indexing",
"private": true,
"scripts": {
"build": "webpack --mode=production",
"dev": "webpack --mode=development --watch",
"clean": "rimraf dist",
"lint": "eslint src --ext .ts,.tsx",
"lint:fix": "eslint src --ext .ts,.tsx --fix",
"typecheck": "tsc --noEmit",
"build:milvus": "echo 'build:milvus script not implemented'"
},
"dependencies": {
"@zilliz/claude-context-core": "workspace:*"
},
"overrides": {
"@zilliz/milvus2-sdk-node": false
},
"devDependencies": {
"@types/chrome": "^0.0.246",
"@types/node": "^20.0.0",
"assert": "^2.1.0",
"browserify-zlib": "^0.2.0",
"buffer": "^6.0.3",
"copy-webpack-plugin": "^11.0.0",
"crypto-browserify": "^3.12.1",
"https-browserify": "^1.0.0",
"os-browserify": "^0.3.0",
"path-browserify": "^1.0.1",
"process": "^0.11.10",
"stream-browserify": "^3.0.0",
"stream-http": "^3.2.0",
"terser-webpack-plugin": "^5.3.14",
"ts-loader": "^9.0.0",
"typescript": "^5.0.0",
"url": "^0.11.4",
"util": "^0.12.5",
"vm-browserify": "^1.1.2",
"webpack": "^5.0.0",
"webpack-cli": "^5.0.0"
},
"repository": {
"type": "git",
"url": "https://github.com/zilliztech/claude-context.git",
"directory": "packages/chrome-extension"
},
"license": "MIT",
"main": "content.js",
"keywords": [],
"author": "",
"bugs": {
"url": "https://github.com/zilliztech/claude-context/issues"
},
"homepage": "https://github.com/zilliztech/claude-context#readme"
}
```
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/bug_report.md:
--------------------------------------------------------------------------------
```markdown
---
name: Bug report
about: Create a report to help us improve
title: ''
labels: ''
assignees: ''
---
**Describe the bug**
Please describe your problem in **English**
**Troubleshooting Guide**
Try to follow the [Troubleshooting Guide](https://github.com/zilliztech/claude-context/blob/main/docs/troubleshooting/troubleshooting-guide.md) to solve the problem. If you can not solve the problem, please open an issue.
## For MCP Use Cases
**Get your MCP logs first**
- If you use Claude Code or Gemini CLI, you can start them with `--debug` mode, e.g.,`claude --debug` or `gemini --debug` to get the detailed MCP logs.
- If you use Cursor-like GUI IDEs, you can 1. Open the Output panel in Cursor (⌘⇧U) 2. Select “MCP Logs” from the dropdown. See https://docs.cursor.com/en/context/mcp#faq for details.
**What's your MCP Client Setting**
Suppose you can not solve the problem from the logs. You can report which MCP client you use, and the setting JSON contents. This information will be helpful to locate the issue.
## For vscode-extension Use Cases
**Get your logs first**
In the global search panel, type `> Toggle Developer Tools` to open the Chrome DevTools window to get the logs. See https://stackoverflow.com/questions/30765782/what-is-the-use-of-the-developer-tools-in-vs-code to get more details.
**Report your issue**
Suppose you can not solve the problem from the logs. You can report the settings in the panel if possible. This information will be helpful to locate the issue.
## For Other Cases
Try to locate the issue and provide more detailed setting information.
## Other Information
**Whether you can reproduce the error**
Try to see if the results of reproduced errors are the same every time.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Software version:**
- IDE version
- node/npm/pnpm Version
**Additional context**
Add any other context about the problem here.
```
--------------------------------------------------------------------------------
/docs/getting-started/prerequisites.md:
--------------------------------------------------------------------------------
```markdown
# Prerequisites
Before setting up Claude Context, ensure you have the following requirements met.
## Required Services
### Embedding Provider (Choose One)
#### Option 1: OpenAI (Recommended)
- **API Key**: Get from [OpenAI Platform](https://platform.openai.com/api-keys)
- **Billing**: Active billing account required
- **Models**: `text-embedding-3-small` or `text-embedding-3-large`
- **Rate Limits**: Check current limits on your OpenAI account
#### Option 2: VoyageAI
- **API Key**: Get from [VoyageAI Console](https://dash.voyageai.com/)
- **Models**: `voyage-code-3` (optimized for code)
- **Billing**: Pay-per-use pricing
#### Option 3: Gemini
- **API Key**: Get from [Google AI Studio](https://aistudio.google.com/)
- **Models**: `gemini-embedding-001`
- **Quota**: Check current quotas and limits
#### Option 4: Ollama (Local)
- **Installation**: Download from [ollama.ai](https://ollama.ai/)
- **Models**: Pull embedding models like `nomic-embed-text`
- **Hardware**: Sufficient RAM for model loading (varies by model)
### Vector Database
#### Zilliz Cloud (Recommended)

- **Account**: [Sign up](https://cloud.zilliz.com/signup?utm_source=github&utm_medium=referral&utm_campaign=2507-codecontext-readme) on Zilliz Cloud to get an API key.
- **Convenience**: Fully managed Milvus vector database service without the need to install and manage it.
#### Local Milvus (Advanced)
- **Docker**: Install Milvus by following [this guide](https://milvus.io/docs/install_standalone-docker-compose.md)
- **Resources**: More complex configuration required
## Development Tools (Optional)
### For VSCode Extension
- **VSCode**: Version 1.74.0 or higher
- **Extensions**: Claude Context extension from marketplace
### For Development Contributions
- **Git**: For version control
- **pnpm**: Package manager (preferred over npm)
- **TypeScript**: Understanding of TypeScript development
```
--------------------------------------------------------------------------------
/evaluation/client.py:
--------------------------------------------------------------------------------
```python
import asyncio
from langgraph.prebuilt import create_react_agent
from utils.format import (
extract_conversation_summary,
extract_file_paths_from_edits,
calculate_total_tokens,
)
class Evaluator:
"""Evaluator class for running LLM queries with MCP tools"""
def __init__(self, llm_model, tools):
"""
Initialize the Evaluator
Args:
llm_model: LangChain LLM model instance (required)
tools: List of tools to use (required)
"""
self.llm_model = llm_model
self.tools = tools
self.agent = create_react_agent(self.llm_model, self.tools)
# Setup event loop for sync usage
try:
self.loop = asyncio.get_event_loop()
except RuntimeError:
self.loop = asyncio.new_event_loop()
asyncio.set_event_loop(self.loop)
async def async_run(self, query, codebase_path=None):
"""Internal async method to run the query"""
response = await self.agent.ainvoke(
{"messages": [{"role": "user", "content": query}]},
config={"recursion_limit": 150},
)
# Extract data without printing
conversation_summary, tool_stats = extract_conversation_summary(response)
token_usage = calculate_total_tokens(response)
if codebase_path:
file_paths = extract_file_paths_from_edits(response, codebase_path)
else:
file_paths = []
return conversation_summary, token_usage, file_paths, tool_stats
def run(self, query: str, codebase_path=None):
"""
Run a query synchronously
Args:
query (str): The query to execute
codebase_path (str): Path to the codebase for relative path conversion
Returns:
tuple: (response, conversation_summary, token_usage, file_paths)
"""
return asyncio.run(self.async_run(query, codebase_path))
```
--------------------------------------------------------------------------------
/packages/core/src/embedding/base-embedding.ts:
--------------------------------------------------------------------------------
```typescript
// Interface definitions
export interface EmbeddingVector {
vector: number[];
dimension: number;
}
/**
* Abstract base class for embedding implementations
*/
export abstract class Embedding {
protected abstract maxTokens: number;
/**
* Preprocess text to ensure it's valid for embedding
* @param text Input text
* @returns Processed text
*/
protected preprocessText(text: string): string {
// Replace empty string with single space
if (text === '') {
return ' ';
}
// Simple character-based truncation (approximation)
// Each token is roughly 4 characters on average for English text
const maxChars = this.maxTokens * 4;
if (text.length > maxChars) {
return text.substring(0, maxChars);
}
return text;
}
/**
* Detect embedding dimension
* @param testText Test text for dimension detection
* @returns Embedding dimension
*/
abstract detectDimension(testText?: string): Promise<number>;
/**
* Preprocess array of texts
* @param texts Array of input texts
* @returns Array of processed texts
*/
protected preprocessTexts(texts: string[]): string[] {
return texts.map(text => this.preprocessText(text));
}
// Abstract methods that must be implemented by subclasses
/**
* Generate text embedding vector
* @param text Text content
* @returns Embedding vector
*/
abstract embed(text: string): Promise<EmbeddingVector>;
/**
* Generate text embedding vectors in batch
* @param texts Text array
* @returns Embedding vector array
*/
abstract embedBatch(texts: string[]): Promise<EmbeddingVector[]>;
/**
* Get embedding vector dimension
* @returns Vector dimension
*/
abstract getDimension(): number;
/**
* Get service provider name
* @returns Provider name
*/
abstract getProvider(): string;
}
```
--------------------------------------------------------------------------------
/packages/vscode-extension/src/webview/webviewHelper.ts:
--------------------------------------------------------------------------------
```typescript
import * as vscode from 'vscode';
import * as fs from 'fs';
import * as path from 'path';
export class WebviewHelper {
/**
* Read HTML template file with support for external resources
* @param extensionUri Extension root directory URI
* @param templatePath Template file relative path
* @param webview webview instance
* @returns HTML content with resolved resource URIs
*/
static getHtmlContent(extensionUri: vscode.Uri, templatePath: string, webview: vscode.Webview): string {
const htmlPath = path.join(extensionUri.fsPath, templatePath);
try {
let htmlContent = fs.readFileSync(htmlPath, 'utf8');
// Check if template needs resource URI replacement (modular templates)
if (htmlContent.includes('{{styleUri}}') || htmlContent.includes('{{scriptUri}}')) {
// Create URIs for external resources
const styleUri = webview.asWebviewUri(
vscode.Uri.joinPath(extensionUri, 'dist', 'webview', 'styles', 'semanticSearch.css')
);
const scriptUri = webview.asWebviewUri(
vscode.Uri.joinPath(extensionUri, 'dist', 'webview', 'scripts', 'semanticSearch.js')
);
// Replace template placeholders
htmlContent = htmlContent
.replace('{{styleUri}}', styleUri.toString())
.replace('{{scriptUri}}', scriptUri.toString());
}
return htmlContent;
} catch (error) {
console.error('Failed to read HTML template:', error);
return this.getFallbackHtml();
}
}
/**
* Get fallback HTML content (used when file reading fails)
*/
private static getFallbackHtml(): string {
return `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Semantic Search</title>
</head>
<body>
<h3>Semantic Search</h3>
<p>Error loading template. Please check console for details.</p>
</body>
</html>
`;
}
}
```
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
```json
{
"name": "claude-context",
"version": "0.1.3",
"description": "A powerful code indexing tool with multi-platform support",
"private": true,
"scripts": {
"build": "pnpm -r --filter='!./examples/*' build && pnpm -r --filter='./examples/*' build",
"build:core": "pnpm --filter @zilliz/claude-context-core build",
"build:vscode": "pnpm --filter semanticcodesearch compile",
"build:mcp": "pnpm --filter @zilliz/claude-context-mcp build",
"dev": "pnpm -r dev",
"dev:core": "pnpm --filter @zilliz/claude-context-core dev",
"dev:vscode": "pnpm --filter semanticcodesearch watch",
"dev:mcp": "pnpm --filter @zilliz/claude-context-mcp dev",
"clean": "pnpm -r clean",
"lint": "pnpm -r lint",
"lint:fix": "pnpm -r run lint:fix",
"typecheck": "pnpm -r run typecheck",
"release:core": "pnpm --filter @zilliz/claude-context-core... run build && pnpm --filter @zilliz/claude-context-core publish --access public --no-git-checks",
"release:mcp": "pnpm --filter @zilliz/claude-context-mcp... run build && pnpm --filter @zilliz/claude-context-mcp publish --access public --no-git-checks",
"release:vscode": "pnpm --filter @zilliz/claude-context-core build && pnpm --filter semanticcodesearch run webpack && pnpm --filter semanticcodesearch release",
"example:basic": "pnpm --filter claude-context-basic-example start",
"benchmark": "node scripts/build-benchmark.js"
},
"devDependencies": {
"@types/node": "^20.0.0",
"@typescript-eslint/eslint-plugin": "^8.31.1",
"@typescript-eslint/parser": "^8.31.1",
"assert": "^2.1.0",
"browserify-zlib": "^0.2.0",
"eslint": "^9.25.1",
"https-browserify": "^1.0.0",
"os-browserify": "^0.3.0",
"rimraf": "^6.0.1",
"stream-http": "^3.2.0",
"tree-sitter-cli": "^0.25.6",
"typescript": "^5.8.3",
"url": "^0.11.4",
"vm-browserify": "^1.1.2"
},
"engines": {
"node": ">=20.0.0",
"pnpm": ">=10.0.0"
},
"repository": {
"type": "git",
"url": "https://github.com/zilliztech/claude-context.git"
},
"license": "MIT",
"author": "Cheney Zhang <[email protected]>"
}
```
--------------------------------------------------------------------------------
/packages/vscode-extension/copy-assets.js:
--------------------------------------------------------------------------------
```javascript
const fs = require('fs');
const path = require('path');
// Ensure dist/webview directory exists
const webviewDistDir = path.join(__dirname, 'dist', 'webview');
if (!fs.existsSync(webviewDistDir)) {
fs.mkdirSync(webviewDistDir, { recursive: true });
}
// Copy CSS files
const stylesDir = path.join(__dirname, 'src', 'webview', 'styles');
if (fs.existsSync(stylesDir)) {
const destStylesDir = path.join(webviewDistDir, 'styles');
if (!fs.existsSync(destStylesDir)) {
fs.mkdirSync(destStylesDir, { recursive: true });
}
const styleFiles = fs.readdirSync(stylesDir);
styleFiles.forEach(file => {
if (file.endsWith('.css')) {
const srcPath = path.join(stylesDir, file);
const destPath = path.join(destStylesDir, file);
fs.copyFileSync(srcPath, destPath);
console.log(`Copied ${file} to webview styles`);
}
});
}
// Copy JavaScript files
const scriptsDir = path.join(__dirname, 'src', 'webview', 'scripts');
if (fs.existsSync(scriptsDir)) {
const destScriptsDir = path.join(webviewDistDir, 'scripts');
if (!fs.existsSync(destScriptsDir)) {
fs.mkdirSync(destScriptsDir, { recursive: true });
}
const scriptFiles = fs.readdirSync(scriptsDir);
scriptFiles.forEach(file => {
if (file.endsWith('.js')) {
const srcPath = path.join(scriptsDir, file);
const destPath = path.join(destScriptsDir, file);
fs.copyFileSync(srcPath, destPath);
console.log(`Copied ${file} to webview scripts`);
}
});
}
// Ensure dist/wasm directory exists and copy WASM files
const wasmDistDir = path.join(__dirname, 'dist', 'wasm');
if (!fs.existsSync(wasmDistDir)) {
fs.mkdirSync(wasmDistDir, { recursive: true });
}
// Copy WASM parser files
const wasmDir = path.join(__dirname, 'wasm');
if (fs.existsSync(wasmDir)) {
const wasmFiles = fs.readdirSync(wasmDir);
wasmFiles.forEach(file => {
if (file.endsWith('.wasm')) {
const srcPath = path.join(wasmDir, file);
const destPath = path.join(wasmDistDir, file);
fs.copyFileSync(srcPath, destPath);
console.log(`Copied ${file} to dist/wasm`);
}
});
}
console.log('Webview assets and WASM files copied successfully!');
```
--------------------------------------------------------------------------------
/packages/chrome-extension/webpack.config.js:
--------------------------------------------------------------------------------
```javascript
const path = require('path');
const CopyWebpackPlugin = require('copy-webpack-plugin');
const webpack = require('webpack');
module.exports = {
mode: 'production',
entry: {
background: './src/background.ts',
content: './src/content.ts',
options: './src/options.ts'
},
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].js',
clean: true
},
cache: {
type: 'filesystem',
buildDependencies: {
config: [__filename]
}
},
devtool: false,
experiments: {
outputModule: false
},
module: {
rules: [
{
test: /\.tsx?$/,
use: 'ts-loader',
exclude: /node_modules/
}
]
},
resolve: {
extensions: ['.tsx', '.ts', '.js'],
fallback: {
"crypto": require.resolve("crypto-browserify"),
"stream": require.resolve("stream-browserify"),
"buffer": require.resolve("buffer"),
"path": require.resolve("path-browserify"),
"util": require.resolve("util"),
"process": require.resolve("process/browser"),
"vm": false,
"os": require.resolve("os-browserify/browser"),
"fs": false,
"tls": false,
"net": false,
"http": require.resolve("stream-http"),
"https": require.resolve("https-browserify"),
"zlib": require.resolve("browserify-zlib"),
"dns": false,
"child_process": false,
"http2": false,
"url": require.resolve("url"),
"assert": require.resolve("assert/"),
"module": false,
"worker_threads": false
},
alias: {
'process/browser': require.resolve('process/browser')
}
},
plugins: [
new CopyWebpackPlugin({
patterns: [
{ from: 'src/manifest.json', to: 'manifest.json' },
{ from: 'src/options.html', to: 'options.html' },
{ from: 'src/styles.css', to: 'styles.css' },
{ from: 'src/icons', to: 'icons' }
]
}),
new webpack.ProvidePlugin({
process: 'process/browser',
Buffer: ['buffer', 'Buffer']
}),
new webpack.DefinePlugin({
'process.env.NODE_ENV': JSON.stringify('production'),
'global': 'globalThis'
}),
new webpack.NormalModuleReplacementPlugin(
/^vm$/,
require.resolve('./src/vm-stub.js')
)
],
target: 'web',
optimization: {
minimize: true,
minimizer: [
new (require('terser-webpack-plugin'))({
terserOptions: {
compress: {
drop_console: false,
drop_debugger: true,
pure_funcs: ['console.debug']
},
mangle: {
safari10: true
},
output: {
comments: false,
safari10: true
}
},
extractComments: false
})
]
},
node: {
global: false,
__filename: false,
__dirname: false
}
};
```
--------------------------------------------------------------------------------
/scripts/build-benchmark.js:
--------------------------------------------------------------------------------
```javascript
#!/usr/bin/env node
/**
* Build performance benchmarking script
* Measures and reports build times for all packages
*/
const { execSync } = require('child_process');
const fs = require('fs');
const path = require('path');
const BENCHMARK_FILE = 'build-benchmark.json';
function measureBuildTime(command, description) {
console.log(`\n🔄 ${description}...`);
const startTime = Date.now();
try {
execSync(command, { stdio: 'inherit' });
const endTime = Date.now();
const duration = endTime - startTime;
console.log(`✅ ${description} completed in ${duration}ms`);
return { success: true, duration, command, description };
} catch (error) {
const endTime = Date.now();
const duration = endTime - startTime;
console.error(`❌ ${description} failed after ${duration}ms`);
return { success: false, duration, command, description, error: error.message };
}
}
function saveBenchmark(results) {
const benchmark = {
timestamp: new Date().toISOString(),
platform: process.platform,
nodeVersion: process.version,
results
};
let history = [];
if (fs.existsSync(BENCHMARK_FILE)) {
try {
history = JSON.parse(fs.readFileSync(BENCHMARK_FILE, 'utf8'));
} catch (e) {
console.warn('Could not read existing benchmark file');
}
}
history.push(benchmark);
// Keep only last 10 benchmarks
if (history.length > 10) {
history = history.slice(-10);
}
fs.writeFileSync(BENCHMARK_FILE, JSON.stringify(history, null, 2));
console.log(`\n📊 Benchmark saved to ${BENCHMARK_FILE}`);
}
function main() {
console.log('🚀 Starting build performance benchmark...');
const results = [];
// Clean first
results.push(measureBuildTime('pnpm clean', 'Clean all packages'));
// Build individual packages
results.push(measureBuildTime('pnpm build:core', 'Build core package'));
results.push(measureBuildTime('pnpm build:mcp', 'Build MCP package'));
results.push(measureBuildTime('pnpm build:vscode', 'Build VSCode extension'));
// Full build
results.push(measureBuildTime('pnpm -r --filter="./packages/chrome-extension" build', 'Build Chrome extension'));
const totalTime = results.reduce((sum, result) => sum + result.duration, 0);
const successCount = results.filter(r => r.success).length;
console.log(`\n📈 Benchmark Summary:`);
console.log(` Total time: ${totalTime}ms`);
console.log(` Successful builds: ${successCount}/${results.length}`);
console.log(` Platform: ${process.platform}`);
console.log(` Node version: ${process.version}`);
saveBenchmark(results);
}
if (require.main === module) {
main();
}
module.exports = { measureBuildTime, saveBenchmark };
```
--------------------------------------------------------------------------------
/packages/core/src/sync/merkle.ts:
--------------------------------------------------------------------------------
```typescript
import * as crypto from 'crypto';
export interface MerkleDAGNode {
id: string;
hash: string;
data: string;
parents: string[];
children: string[];
}
export class MerkleDAG {
nodes: Map<string, MerkleDAGNode>;
rootIds: string[];
constructor() {
this.nodes = new Map();
this.rootIds = [];
}
private hash(data: string): string {
return crypto.createHash('sha256').update(data).digest('hex');
}
public addNode(data: string, parentId?: string): string {
const nodeId = this.hash(data);
const node: MerkleDAGNode = {
id: nodeId,
hash: nodeId,
data,
parents: [],
children: []
};
// If there's a parent, create the relationship
if (parentId) {
const parentNode = this.nodes.get(parentId);
if (parentNode) {
node.parents.push(parentId);
parentNode.children.push(nodeId);
this.nodes.set(parentId, parentNode);
}
} else {
// If no parent, it's a root node
this.rootIds.push(nodeId);
}
this.nodes.set(nodeId, node);
return nodeId;
}
public getNode(nodeId: string): MerkleDAGNode | undefined {
return this.nodes.get(nodeId);
}
public getAllNodes(): MerkleDAGNode[] {
return Array.from(this.nodes.values());
}
public getRootNodes(): MerkleDAGNode[] {
return this.rootIds.map(id => this.nodes.get(id)!).filter(Boolean);
}
public getLeafNodes(): MerkleDAGNode[] {
return Array.from(this.nodes.values()).filter(node => node.children.length === 0);
}
public serialize(): any {
return {
nodes: Array.from(this.nodes.entries()),
rootIds: this.rootIds
};
}
public static deserialize(data: any): MerkleDAG {
const dag = new MerkleDAG();
dag.nodes = new Map(data.nodes);
dag.rootIds = data.rootIds;
return dag;
}
public static compare(dag1: MerkleDAG, dag2: MerkleDAG): { added: string[], removed: string[], modified: string[] } {
const nodes1 = new Map(Array.from(dag1.getAllNodes()).map(n => [n.id, n]));
const nodes2 = new Map(Array.from(dag2.getAllNodes()).map(n => [n.id, n]));
const added = Array.from(nodes2.keys()).filter(k => !nodes1.has(k));
const removed = Array.from(nodes1.keys()).filter(k => !nodes2.has(k));
// For modified, we'll check if the data has changed for nodes that exist in both
const modified: string[] = [];
for (const [id, node1] of Array.from(nodes1.entries())) {
const node2 = nodes2.get(id);
if (node2 && node1.data !== node2.data) {
modified.push(id);
}
}
return { added, removed, modified };
}
}
```
--------------------------------------------------------------------------------
/packages/core/src/utils/env-manager.ts:
--------------------------------------------------------------------------------
```typescript
import * as fs from 'fs';
import * as path from 'path';
import * as os from 'os';
export class EnvManager {
private envFilePath: string;
constructor() {
const homeDir = os.homedir();
this.envFilePath = path.join(homeDir, '.context', '.env');
}
/**
* Get environment variable by name
* Priority: process.env > .env file > undefined
*/
get(name: string): string | undefined {
// First try to get from process environment variables
if (process.env[name]) {
return process.env[name];
}
// If not found in process env, try to read from .env file
try {
if (fs.existsSync(this.envFilePath)) {
const content = fs.readFileSync(this.envFilePath, 'utf-8');
const lines = content.split('\n');
for (const line of lines) {
const trimmedLine = line.trim();
if (trimmedLine.startsWith(`${name}=`)) {
return trimmedLine.substring(name.length + 1);
}
}
}
} catch (error) {
// Ignore file read errors
}
return undefined;
}
/**
* Set environment variable to the .env file
*/
set(name: string, value: string): void {
try {
// Ensure directory exists
const envDir = path.dirname(this.envFilePath);
if (!fs.existsSync(envDir)) {
fs.mkdirSync(envDir, { recursive: true });
}
let content = '';
let found = false;
// Read existing content if file exists
if (fs.existsSync(this.envFilePath)) {
content = fs.readFileSync(this.envFilePath, 'utf-8');
// Update existing variable
const lines = content.split('\n');
for (let i = 0; i < lines.length; i++) {
if (lines[i].trim().startsWith(`${name}=`)) {
// Replace the existing value
lines[i] = `${name}=${value}`;
found = true;
console.log(`[EnvManager] ✅ Updated ${name} in ${this.envFilePath}`);
break;
}
}
content = lines.join('\n');
}
// If variable not found, append it
if (!found) {
if (content && !content.endsWith('\n')) {
content += '\n';
}
content += `${name}=${value}\n`;
console.log(`[EnvManager] ✅ Added ${name} to ${this.envFilePath}`);
}
fs.writeFileSync(this.envFilePath, content, 'utf-8');
} catch (error) {
console.error(`[EnvManager] ❌ Failed to write env file: ${error}`);
throw error;
}
}
/**
* Get the path to the .env file
*/
getEnvFilePath(): string {
return this.envFilePath;
}
}
// Export a default instance for convenience
export const envManager = new EnvManager();
```
--------------------------------------------------------------------------------
/packages/chrome-extension/src/config/milvusConfig.ts:
--------------------------------------------------------------------------------
```typescript
export interface MilvusConfig {
address: string;
token?: string;
username?: string;
password?: string;
database?: string;
}
export interface ChromeStorageConfig {
githubToken?: string;
openaiToken?: string;
milvusAddress?: string;
milvusToken?: string;
milvusUsername?: string;
milvusPassword?: string;
milvusDatabase?: string;
}
export class MilvusConfigManager {
/**
* Get Milvus configuration from Chrome storage
*/
static async getMilvusConfig(): Promise<MilvusConfig | null> {
return new Promise((resolve) => {
chrome.storage.sync.get([
'milvusAddress',
'milvusToken',
'milvusUsername',
'milvusPassword',
'milvusDatabase'
], (items: ChromeStorageConfig) => {
if (chrome.runtime.lastError) {
console.error('Error loading Milvus config:', chrome.runtime.lastError);
resolve(null);
return;
}
if (!items.milvusAddress) {
resolve(null);
return;
}
const config: MilvusConfig = {
address: items.milvusAddress,
token: items.milvusToken,
username: items.milvusUsername,
password: items.milvusPassword,
database: items.milvusDatabase || 'default'
};
resolve(config);
});
});
}
/**
* Save Milvus configuration to Chrome storage
*/
static async saveMilvusConfig(config: MilvusConfig): Promise<void> {
return new Promise((resolve, reject) => {
chrome.storage.sync.set({
milvusAddress: config.address,
milvusToken: config.token,
milvusUsername: config.username,
milvusPassword: config.password,
milvusDatabase: config.database || 'default'
}, () => {
if (chrome.runtime.lastError) {
reject(chrome.runtime.lastError);
} else {
resolve();
}
});
});
}
/**
* Get OpenAI configuration
*/
static async getOpenAIConfig(): Promise<{ apiKey: string; model: string } | null> {
return new Promise((resolve) => {
chrome.storage.sync.get(['openaiToken'], (items: ChromeStorageConfig) => {
if (chrome.runtime.lastError || !items.openaiToken) {
resolve(null);
return;
}
resolve({
apiKey: items.openaiToken,
model: 'text-embedding-3-small' // Default model
});
});
});
}
/**
* Validate Milvus configuration
*/
static validateMilvusConfig(config: MilvusConfig): boolean {
if (!config.address) {
return false;
}
// For basic validation, just check if address is provided
// Authentication can be optional for local instances
return true;
}
}
```
--------------------------------------------------------------------------------
/evaluation/generate_subset_json.py:
--------------------------------------------------------------------------------
```python
#!/usr/bin/env python3
"""
Generate swe_verified_15min1h_2files_instances.json from the subset analysis
"""
import json
import re
from datasets import load_dataset
def parse_patch_files(patch_content):
"""Parse patch content to extract the number of modified files"""
if not patch_content:
return []
file_pattern = r'^diff --git a/(.*?) b/(.*?)$'
files = []
for line in patch_content.split('\n'):
match = re.match(file_pattern, line)
if match:
file_path = match.group(1)
files.append(file_path)
return files
def main():
print("Loading SWE-bench_Verified dataset...")
dataset = load_dataset("princeton-nlp/SWE-bench_Verified")
instances = list(dataset['test'])
print("Filtering instances for: 15min-1hour difficulty + 2 patch files...")
# Filter for the specific subset
subset_instances = []
for instance in instances:
difficulty = instance.get('difficulty', 'Unknown')
# Parse main patch to count files
patch_content = instance.get('patch', '')
patch_files = parse_patch_files(patch_content)
oracle_count = len(patch_files)
# Check if it matches our criteria
if difficulty == '15 min - 1 hour' and oracle_count == 2:
subset_instances.append(instance)
print(f"Found {len(subset_instances)} instances matching criteria")
# Create the JSON structure that _prepare_instances expects
output_data = {
"metadata": {
"description": "SWE-bench_Verified subset: 15min-1hour difficulty with 2 patch files",
"source_dataset": "princeton-nlp/SWE-bench_Verified",
"extraction_date": "2024",
"filter_criteria": {
"difficulty": "15 min - 1 hour",
"patch_files_count": 2
},
"total_instances": len(subset_instances),
"statistics": {
"total_instances_in_original": 500,
"subset_count": len(subset_instances),
"percentage_of_original": round((len(subset_instances) / 500) * 100, 1)
}
},
"instances": subset_instances
}
# Save to JSON file
output_file = "swe_verified_15min1h_2files_instances.json"
with open(output_file, 'w') as f:
json.dump(output_data, f, indent=2)
print(f"Generated {output_file} with {len(subset_instances)} instances")
# Verify the structure
print("\nVerifying JSON structure...")
with open(output_file, 'r') as f:
loaded_data = json.load(f)
print(f"✓ Contains 'instances' key: {'instances' in loaded_data}")
print(f"✓ Contains 'metadata' key: {'metadata' in loaded_data}")
print(f"✓ Number of instances: {len(loaded_data['instances'])}")
print(f"✓ First instance has required fields:")
if loaded_data['instances']:
first_instance = loaded_data['instances'][0]
required_fields = ['instance_id', 'repo', 'base_commit', 'problem_statement']
for field in required_fields:
has_field = field in first_instance
print(f" - {field}: {'✓' if has_field else '✗'}")
print(f"\nFile successfully generated: {output_file}")
print("This file can be used with BaseRetrieval._prepare_instances()")
if __name__ == "__main__":
main()
```
--------------------------------------------------------------------------------
/evaluation/run_evaluation.py:
--------------------------------------------------------------------------------
```python
import os
from argparse import ArgumentParser
from typing import List, Optional
from retrieval.custom import CustomRetrieval
from utils.constant import evaluation_path, project_path
import logging
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s")
logger = logging.getLogger(__name__)
def main(
dataset_name_or_path: str,
output_dir: str,
retrieval_types: List[str],
llm_type: str = "openai",
llm_model: Optional[str] = None,
splits: List[str] = ["test"],
root_dir: str = str(evaluation_path / "repos"),
max_instances: Optional[int] = 5,
):
"""
Main function to run custom retrieval.
Args:
dataset_name_or_path: Dataset path or name
output_dir: Output directory for results
retrieval_types: List of retrieval types to use ('cc', 'grep', or both)
llm_type: Type of LLM to use
llm_model: LLM model name
splits: Dataset splits to process
root_dir: Root directory for repositories
max_instances: Maximum number of instances to process
"""
logger.info(f"Starting custom retrieval with types: {retrieval_types}")
retrieval = CustomRetrieval(
dataset_name_or_path=dataset_name_or_path,
splits=splits,
output_dir=output_dir,
retrieval_types=retrieval_types,
llm_type=llm_type,
llm_model=llm_model,
max_instances=max_instances,
)
retrieval.run(root_dir, token=os.environ.get("GITHUB_TOKEN", "git"))
def parse_retrieval_types(value: str) -> List[str]:
"""Parse comma-separated retrieval types string into list"""
types = [t.strip().lower() for t in value.split(",")]
valid_types = {"cc", "grep"}
for t in types:
if t not in valid_types:
raise ValueError(
f"Invalid retrieval type '{t}'. Must be one of: {valid_types}"
)
return types
if __name__ == "__main__":
parser = ArgumentParser(
description="Custom Retrieval for SWE-bench with flexible retrieval types"
)
parser.add_argument(
"--dataset_name_or_path",
type=str,
# default="SWE-bench/SWE-bench_Lite",
default="swe_verified_15min1h_2files_instances.json",
help="Dataset name or path",
)
parser.add_argument(
"--output_dir",
type=str,
default=str(evaluation_path / "retrieval_results_custom"),
help="Output directory",
)
parser.add_argument(
"--retrieval_types",
type=parse_retrieval_types,
default="cc,grep",
help="Comma-separated list of retrieval types to use. Options: 'cc', 'grep', or 'cc,grep' (default: 'cc,grep')",
)
parser.add_argument(
"--llm_type",
type=str,
choices=["openai", "ollama", "moonshot"],
# default="moonshot",
default="openai",
# default="anthropic",
help="LLM type",
)
parser.add_argument(
"--llm_model",
type=str,
# default="kimi-k2-0711-preview",
default="gpt-4o-mini",
# default="claude-sonnet-4-20250514",
help="LLM model name, e.g. gpt-4o-mini",
)
parser.add_argument(
"--splits", nargs="+", default=["test"], help="Dataset splits to process"
)
parser.add_argument(
"--root_dir",
type=str,
default=str(evaluation_path / "repos"),
help="Temporary directory for repositories",
)
parser.add_argument(
"--max_instances",
type=int,
default=5,
help="Maximum number of instances to process (default: 5, set to -1 for all)",
)
args = parser.parse_args()
main(**vars(args))
```
--------------------------------------------------------------------------------
/docs/dive-deep/file-inclusion-rules.md:
--------------------------------------------------------------------------------
```markdown
# File Inclusion & Exclusion Rules
This document explains how Claude Context determines which files to include in the indexing process and which files to exclude.
## Overview
Claude Context uses a comprehensive rule system that combines multiple sources of file extensions and ignore patterns to determine what gets indexed.
## The Core Rule
```
Final Files = (All Supported Extensions) - (All Ignore Patterns)
```
Where:
- **All Supported Extensions** = Default + MCP Custom + Environment Variable Extensions
- **All Ignore Patterns** = Default + MCP Custom + Environment Variable + .gitignore + .xxxignore + Global .contextignore
## File Inclusion Flow

The diagram above shows how different sources contribute to the final file selection process.
## Extension Sources (Additive)
All extension sources are combined together:
### 1. Default Extensions
Built-in supported file extensions including:
- Programming languages: `.ts`, `.tsx`, `.js`, `.jsx`, `.py`, `.java`, `.cpp`, `.c`, `.h`, `.hpp`, `.cs`, `.go`, `.rs`, `.php`, `.rb`, `.swift`, `.kt`, `.scala`, `.m`, `.mm`
- Documentation: `.md`, `.markdown`, `.ipynb`
For more details, see [DEFAULT_SUPPORTED_EXTENSIONS](../../packages/core/src/context.ts) in the context.ts file.
### 2. MCP Custom Extensions
Additional extensions passed dynamically via MCP `customExtensions` parameter:
```json
{
"customExtensions": [".vue", ".svelte", ".astro"]
}
```
Just dynamically tell the agent what extensions you want to index to invoke this parameter. For example:
```
"Index this codebase, and include .vue, .svelte, .astro files"
```
### 3. Environment Variable Extensions
Extensions from `CUSTOM_EXTENSIONS` environment variable:
```bash
export CUSTOM_EXTENSIONS=".vue,.svelte,.astro"
```
See [Environment Variables](../getting-started/environment-variables.md) for more details about how to set environment variables.
## Ignore Pattern Sources (Additive)
All ignore pattern sources are combined together:
### 1. Default Ignore Patterns
Built-in patterns for common files/directories to exclude:
- **Build outputs**: `node_modules/**`, `dist/**`, `build/**`, `out/**`, `target/**`, `coverage/**`, `.nyc_output/**`
- **IDE files**: `.vscode/**`, `.idea/**`, `*.swp`, `*.swo`
- **Version control**: `.git/**`, `.svn/**`, `.hg/**`
- **Cache directories**: `.cache/**`, `__pycache__/**`, `.pytest_cache/**`
- **Logs and temporary**: `logs/**`, `tmp/**`, `temp/**`, `*.log`
- **Environment files**: `.env`, `.env.*`, `*.local`
- **Minified files**: `*.min.js`, `*.min.css`, `*.min.map`, `*.bundle.js`, `*.bundle.css`, `*.chunk.js`, `*.vendor.js`, `*.polyfills.js`, `*.runtime.js`, `*.map`
For more details, see [DEFAULT_IGNORE_PATTERNS](../../packages/core/src/context.ts) in the context.ts file.
### 2. MCP Custom Ignore Patterns
Additional patterns passed dynamically via MCP `ignorePatterns` parameter:
```json
{
"ignorePatterns": ["temp/**", "*.backup", "private/**"]
}
```
Just dynamically tell the agent what patterns you want to exclude to invoke this parameter. For example:
```
"Index this codebase, and exclude temp/**, *.backup, private/** files"
```
### 3. Environment Variable Ignore Patterns
Patterns from `CUSTOM_IGNORE_PATTERNS` environment variable:
```bash
export CUSTOM_IGNORE_PATTERNS="temp/**,*.backup,private/**"
```
See [Environment Variables](../getting-started/environment-variables.md) for more details about how to set environment variables.
### 4. .gitignore Files
Standard Git ignore patterns in codebase root.
### 5. .xxxignore Files
Any file in codebase root matching pattern `.xxxignore`:
- `.cursorignore`
- `.codeiumignore`
- `.contextignore`
- etc.
### 6. Global .contextignore
User-wide patterns in `~/.context/.contextignore`.
```
--------------------------------------------------------------------------------
/docs/troubleshooting/faq.md:
--------------------------------------------------------------------------------
```markdown
# Frequently Asked Questions (FAQ)
## Q: What files does Claude Context decide to embed?
**A:** Claude Context uses a comprehensive rule system to determine which files to include in indexing:
**Simple Rule:**
```
Final Files = (All Supported Extensions) - (All Ignore Patterns)
```
- **Extensions are additive**: Default extensions + MCP custom + Environment variables
- **Ignore patterns are additive**: Default patterns + MCP custom + Environment variables + .gitignore + .xxxignore files + global .contextignore
**For detailed explanation see:** [File Inclusion Rules](../dive-deep/file-inclusion-rules.md)
## Q: Can I use a fully local deployment setup?
**A:** Yes, you can deploy Claude Context entirely on your local infrastructure. While we recommend using the fully managed [Zilliz Cloud](https://cloud.zilliz.com/signup?utm_source=github&utm_medium=referral&utm_campaign=2507-codecontext-readme) service for ease of use, you can also set up your own private local deployment.
**For local deployment:**
1. **Vector Database (Milvus)**: Deploy Milvus locally using Docker Compose by following the [official Milvus installation guide](https://milvus.io/docs/install_standalone-docker-compose.md). Configure the following environment variables:
- `MILVUS_ADDRESS=127.0.0.1:19530` (or your Milvus server address)
- `MILVUS_TOKEN=your-optional-token` (if authentication is enabled)
2. **Embedding Service (Ollama)**: Install and run [Ollama](https://ollama.com/) locally for embedding generation. Configure:
- `EMBEDDING_PROVIDER=Ollama`
- `OLLAMA_HOST=http://127.0.0.1:11434` (or your Ollama server URL)
- `OLLAMA_MODEL=nomic-embed-text` (or your preferred embedding model)
This setup gives you complete control over your data while maintaining full functionality. See our [environment variables guide](../getting-started/environment-variables.md) for detailed configuration options.
## Q: Does it support multiple projects / codebases?
**A:** Yes, Claude Context fully supports multiple projects and codebases. In MCP mode, it automatically leverages the MCP client's AI Agent to detect and obtain the current codebase path where you're working.
You can seamlessly use queries like `index this codebase` or `search the main function` without specifying explicit paths. When you switch between different codebase working directories, Claude Context automatically discovers the change and adapts accordingly - no need to manually input specific codebase paths.
**Key features for multi-project support:**
- **Automatic Path Detection**: Leverages MCP client's workspace awareness to identify current working directory
- **Seamless Project Switching**: Automatically detects when you switch between different codebases
- **Background Code Synchronization**: Continuously monitors for changes and automatically re-indexes modified parts
- **Context-Aware Operations**: All indexing and search operations are scoped to the current project context
This makes it effortless to work across multiple projects while maintaining isolated, up-to-date indexes for each codebase.
## Q: How does Claude Context compare to other coding tools like Serena, Context7, or DeepWiki?
**A:** Claude Context is specifically focused on **codebase indexing and semantic search**. Here's how we compare:
- **[Serena](https://github.com/oraios/serena)**: A comprehensive coding agent toolkit with language server integration and symbolic code understanding. Provides broader AI coding capabilities.
- **[Context7](https://github.com/upstash/context7)**: Focuses on providing up-to-date documentation and code examples to prevent "code hallucination" in LLMs. Targets documentation accuracy.
- **[DeepWiki](https://docs.devin.ai/work-with-devin/deepwiki-mcp)**: Generates interactive documentation from GitHub repositories. Creates documentation from code.
**Our focus**: Making your entire codebase searchable and contextually available to AI assistants through efficient vector-based indexing and hybrid search.
```